In Syntactic Structures, Chomsky (1957) provides an analysis of the English auxiliary verb system that explains both the order of auxiliary verbs, when more than one are present, and the connection between a given auxiliary and the morphological form of the auxiliary or main verb that follows. For example, progressive be follows perfect have and requires the present participle –ing suffix on the verb that follows it, as in John has been driving recklessly. Subsequent work on languages that load more “inflectional” morphology on verbs and use fewer independent auxiliary verbs has revealed that the order of tense, aspect, and modality morphology cross-linguistically generally mirrors the order of English auxiliaries: tense, modal, perfect, progressive, passive, verb (or, if these are realized as suffixes, verb, passive, progressive, perfect modal, tense). Work on the structure of verb phrases and noun phrases has revealed a set of “functional” categories (for nouns, things like number, definiteness and case) that form constituents with the noun and appear in similar hierarchies across languages.
Grimshaw (1991) was concerned with puzzles that involve the apparent optionality of these functional categories connected to nouns and verbs. For example, a verb phrase may appear only with tense, as in John sings, or it may appear with a number of auxiliaries, in which case tense appears on the top/left most auxiliary: John was/is singing, John has/had been singing, etc. If tense c-selects for a (main) verb, does it optionally also c-select for the progressive auxiliary, perfect auxiliary, etc.? The proper generalization, which was captured by Chomsky’s (1957) system in an elegant but problematic way, is that the functional categories appear in a fixed hierarchical order from the verb up (Chomsky had the auxiliaries in a fixed linear order, rather than a hierarchy, but subsequent research points to the hierarchical solution). There’s a sense in which the functional categories are optional – certainly no overt realization of aspect or “passive” is required in every English verb phrase. Yet there is also a downward selection associated with these categories. The modal auxiliaries, for example, require a bare verbal stem, while the perfect have auxiliary requires a perfect participle to head its complement, and the progressive auxiliary requires a present participle for its own complement.
Grimshaw suggested that noun, verbs, adjectives and prepositions (or postpositions) anchor the distribution of “functional” material like tense or number that appears with these words in larger phrases. To borrow her terminology, a “lexical” category (N, V, Adj, P) is associated with an “extended projection” of optional “functional” (non-lexical) heads. This fixed hierarchy of heads is projected above the structure in which the “arguments” of lexical categories, like subjects and objects, appear.
What emerges from this history of phrase structure within generative syntax since the 1950’s is an understanding of the distribution of morphemes and phrases in sentences that is not captured by standard phrase structure rules. Lexical categories are associated with an “extended projection,” the grammatical well-formedness of which is governed by a head’s demands for the features of the phrases that they combine with; for example, the perfective auxiliary wants to combine with a phrase headed by a perfect participle, and the verb rely wants to combine with a phrase headed by the preposition on. The requirements of heads are thus governed by properties related to semantic compositionality (s-selection) and not directly by subcategorization (c-selection). The “arguments” of lexical categories similarly have their distribution governed by factors of s-selection and other properties (e.g., noun phrases need case), rather than by c-selection of a particular item or by phrase structure generalizations that refer directly to category (e.g., VP → V NP, where NP is the category of the verb’s direct object).
How does this discussion of constituent structure relate to morphology and the internal structure of words? First, note that the formal statement of a selectional relation between one constituent and a feature of another constituent to which it is joined in a larger structure describes a small constituent structure (phrase structure) tree. For instance, to return to an example from Syntactic Structures, the auxiliary have in English selects for a complement headed by a perfect participle (often indicated by the form of one of the allomorphs of the perfect participle suffix –en). Chomsky formalized this dependency by having have introduced along with the –en suffix, then “hopping” the –en onto the adjacent verb, whatever that verb might be (progressive be, passive be, or the main verb). In line with contemporary theories, we might formalize the selectional properties of have with the feature in (1). This corresponds to, and could be used to generate or describe, the small tree in (1). We can suppose that the “perfect participle” features of –en are visible on the verb phrase node that contains verb-en.
(1) have : [ __ [ verb+en … ] ]
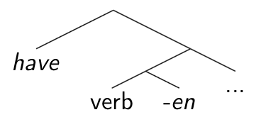
Extrapolating from this example, we can note that by combining various mini-trees corresponding to selectional features, one can generate constituent structure trees for whole sentences. That is, sentence structure to some extent can be seen as a projection of selectional features.
Here we can see the connection between the structure of sentences and the internal structure of words. It is standard practice in generative grammar to encode the distributional properties of affixes in selectional features. For example, the suffix –er can attach to verbs to create agentive or instrumental nouns, a property encoded in the selectional feature in (2) with its corresponding mini-tree.
(2) –er : [N verb __ ]
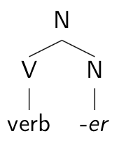
The careful reader may notice an odd fact about the selectional feature (4): –er, of category N, appears to c-select for the category V. Yet in our discussion of lexical categories above in the phrasal domain, we noted that nouns, verbs and adjectives don’t generally c-select for their complements; rather, lexical categories “project” an “extended projection” of “functional” heads, and s-select for complements.
The term “derivational morphology” can be used to refer to affixes that appear to determine, and thus often appear to change, the category of the stems to which they attach. Derivational affixes in English fall into at least two (partially overlapping) categories: (i) those that are widely productive and don’t specify (beyond a category specification) a set of stems or affixes to which they like to attach, and (ii) those that are non- or semi-productive and only attach to a particular set of stems and affixes. Agentive/instrumental –er is a prime example of the first set, attaching to any verb, with the well-formedness of the result a function of the semantics of the combination (e.g., seemer is odd). The nominalizer –ity is of the second sort, creating nouns from a list of stems, some of which are bound roots (e.g., am-ity), and a set of adjectives ending specifically in the suffixes –al and –able. For this second set of derivational affixes, we can say that they s-select for their complement (-ity s-selects for a “property”) and further select for a specific set of morphemes, in the same way that, e.g., depend selects for on.
But for –er and affixes that productively attach to a lexical category of stems like verbs, we do seem to have some form of c-selection: the affixes seem to select for the category of the stems they attach to. But suppose this is upside-down. Suppose we can say that being a verb means that you can appear with –er. This is very similar to saying that the form verb-er can be projected up from the verb, in the same way that (tensed) verb-s and verb-ed are constructed. That is, –ercan be seen as part of the extended projection of a verb.
Extended projections are frequently analyzed as morphological paradigms when the functional material of the extended projection is realized as affixes on the head. By performing an extended projection and realizing the functional material morphophonologically, one fills out the paradigm of inflected forms of the head. On the proposed view that productive derivational morphology associated with categories of stems involves the extended projections of the stems themselves, forms in –er, for example, would then be part of the paradigm of verbs. (This discussion echoes Shigeru Miyagawa’s (1980) treatment of Japanese causatives in his dissertation.) I’ll fill in the details of this proposal, as well as explain the contrast that emerges between the two types of derivation (productive-paradigmatic vs. semi-productive-selectional), in a later post.
Finally, remember that extended projections can be phrasal. That is, the structure of an English sentence, with its possible auxiliary verbs and other material on top of the inflected main verb, is the extended projection of the verb that heads the verb phrase in the sentence. If we view the paradigms of inflected verbs and nouns as generated from the extended projections of their stems, we can view sentences in languages like English as paradigmatic – cells in the paradigm of the head verb generated via the extended projection of that verb. When we look at phonological words in agglutinative languages like Yup’ik Eskimo, we see that these words (i) can stand alone as sentences translated into full phrasal sentences in English and (ii) have been analyzed as part of the enormous paradigm of forms associated with the head verbal root of the word. These types of examples point directly to the connection between parsing words and parsing sentences.
References
Chomsky, N. (1957). Syntactic Structures. Walter de Gruyter.
Grimshaw, J. (1991). Extended projection. Brandeis University: Ms. (Also appeared in Grimshaw, J. (2005). Words and Structure. Stanford: CSLI).
Miyagawa, S. (1980). Complex verbs and the lexicon. University of Arizona: PhD dissertation.
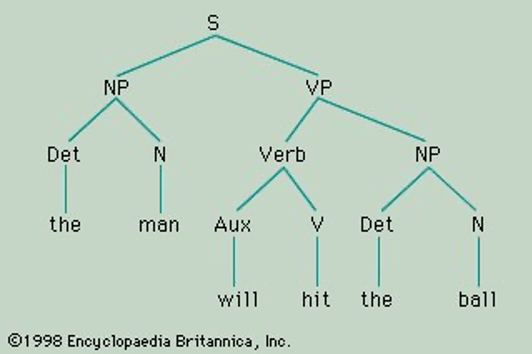
 Note the function of “node” labels in standard phrase structure rules. First, and quite importantly, a label like NP appears in more than one rule. In a textbook presentation of English grammar, NP would appear as sister to VP as the expansion of the S node, but also as sister to the Verb in the expansion of VP. The important generalization captured here is that English includes phrases whose internal structure doesn’t uniquely determine their position in a sentence. Inside an NP, we don’t know if we’re inside a subject or an object – the potentially infinite list of NPs generated by the grammar could appear in either position.
Note the function of “node” labels in standard phrase structure rules. First, and quite importantly, a label like NP appears in more than one rule. In a textbook presentation of English grammar, NP would appear as sister to VP as the expansion of the S node, but also as sister to the Verb in the expansion of VP. The important generalization captured here is that English includes phrases whose internal structure doesn’t uniquely determine their position in a sentence. Inside an NP, we don’t know if we’re inside a subject or an object – the potentially infinite list of NPs generated by the grammar could appear in either position.