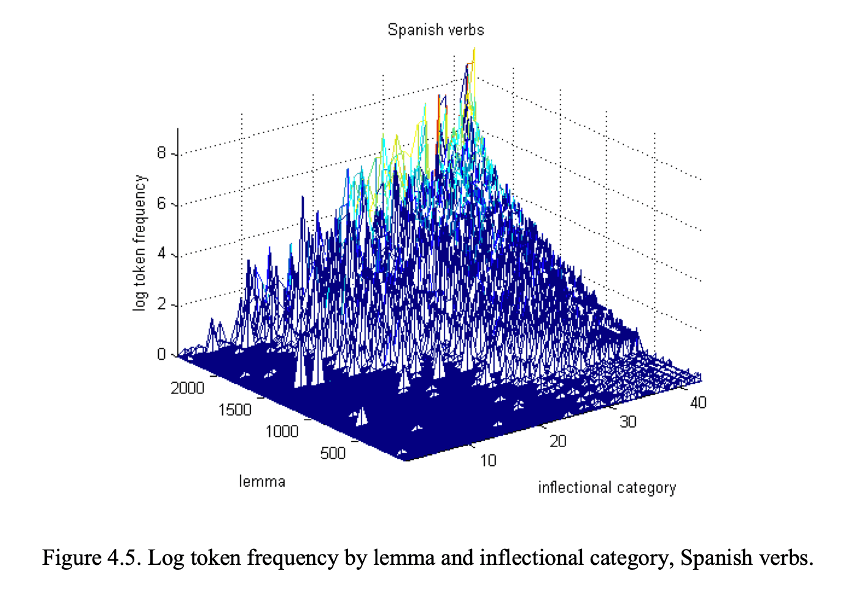
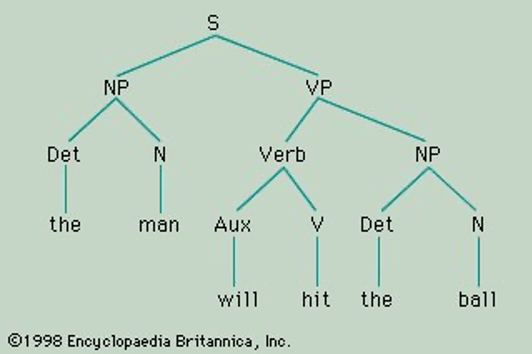
Most approaches that try to relate linguistic knowledge to real time processing of sentences have considered phrase structure rules as a reasonable formalism for the hierarchical constituent structure of sentences. From the perspective of the history of generative linguistics, one can trace the importance of phrase structure rules to Chomsky’s argument in Syntactic Structures (1957) that our knowledge of language involves a hierarchical arrangement of words, phrases, and phrases containing phrases, rather than knowledge of a linear string of words (Marantz 2019). Introductory linguistics textbooks present sentence structure with familiar Sentence → Noun_Phrase Verb_Phrase rules, whose output is illustrated in labelled branching tree structures.
 Note the function of “node” labels in standard phrase structure rules. First, and quite importantly, a label like NP appears in more than one rule. In a textbook presentation of English grammar, NP would appear as sister to VP as the expansion of the S node, but also as sister to the Verb in the expansion of VP. The important generalization captured here is that English includes phrases whose internal structure doesn’t uniquely determine their position in a sentence. Inside an NP, we don’t know if we’re inside a subject or an object – the potentially infinite list of NPs generated by the grammar could appear in either position.
Note the function of “node” labels in standard phrase structure rules. First, and quite importantly, a label like NP appears in more than one rule. In a textbook presentation of English grammar, NP would appear as sister to VP as the expansion of the S node, but also as sister to the Verb in the expansion of VP. The important generalization captured here is that English includes phrases whose internal structure doesn’t uniquely determine their position in a sentence. Inside an NP, we don’t know if we’re inside a subject or an object – the potentially infinite list of NPs generated by the grammar could appear in either position.
It’s true that some languages will distinguish noun phrases using case. In a canonical tensed transitive sentence, the subject might be obligatorily marked with nominative case and the object with accusative case. In languages like Russian, this case marking appears on the head noun of the noun phrase as well as on agreeing adjectives and other constituents. Importantly, however, case-marked noun phrases don’t appear in unique positions in sentences. If you’re inside a dative-marked noun phrase in Icelandic, for example, you don’t know whether you’re in the subject position, the object position, or some other hierarchical position in a sentence. Furthermore, case marking in general appears as if it’s been added “on top of” a noun phrase. That is, the internal structure of a noun phrase (the distribution of determiners, adjectives, etc.) is generally the same within, say, a dative and a nominative noun phrase. As far as phrase structure generalizations are concerned, then, a noun phrase is a noun phrase, no matter what position it is in and what case marking it has.
In phrase structure rules, a node label that appears on the right side of one rule, such as VP in (1), can appear on the left side of another rule (2) that describes the internal structure of that node. That is, a node label serves to connect a phrase’s external distribution and its internal structure.
(1) S → NP VP
(2) VP → V (NP) (NP) PP* (S)
where parentheses indicate optionality and * indicates any number of the category, including zero
The development of the “X-bar” theory of phrase structure captured the important insight that node labels themselves are not arbitrary with respect to syntactic theory. Nodes are labeled according to their internal structure, and the labels themselves consist of sets of features derived from a universal list. So a noun phrase is phrase with a noun as its “head.” More generally, there is some computation over the features of the constituents within a phrase that determines the features of the node at the top. And it’s these top node features that determine the distribution of the phrase within other phrases, since it is via these features that the node will be identified by the right side of phrase structure rules, which describe the distribution of phrases inside phrases. X-bar theory therefore provided a constrained template for phrase structure rules as well as a built-in relationship between the label of a node and its internal structure: phrases are labeled by their heads, so an XP has an X as its head.
We can describe linguists’ evolving understanding of phrase structure by reviewing a simplified history of the syntactic literature. In Aspects of the Theory of Syntax (1965), Chomsky observed an apparent difference between phrases that appear as the sister to a verb in a verb phrase and phrases that appear as the sister to the verb phrase. Individual verbs seemed to care about the category of their complements within the verb phrase, but they did not seem to specify the category of the sister to the verb phrase, the “subject” of the sentence. For example, some verbs like hit might be transitive, requiring a noun phrase, while verbs like give seem to require either two noun phrases or a noun phrase and a prepositional phrase. Chomsky suggested that the category “verb” could be further “subcategorized” into smaller categories according their complements. Verbs like hit would carry the subcategorization feature +[__NP], putting them in the subcategory of transitive verbs and indicating that they (must) appear as a sister to a noun phrase within the verb phrase. On the other hand, verbs did not seem to specify the category of the “subject” of the sentence, which could be a prepositional phrase or an entire sentence, for example. Instead, verbs might care about whether the subject is, say, animate – a semantic feature. Verbs, then, could “select” for the semantic category of their “specifier” (the sister to the verb phrase), while they would be “subcategorized” by (or “for”) the syntactic categories of the complements they take.
It was then observed that the phrase structure rule for a verb phrase, as in (2), could be generated as the combination of (i) a union of the subcategorization features of English verbs, and (ii) some ordering statements that could follow from general principles (e.g., noun phrases want to be next to the verb and sentential complements want to be at the end of the verb phrase). From this observation came the claim that phrase structure rules themselves do not specify the categories of constituents other than their heads. That is, the distribution of non-heads within phrases, as well as their order, would follow from principles independent of the phrase structure rules.
At this point, we give a shout out to Jane Grimshaw, who contributed foundational papers to the next two developments we’ll discuss. First, Grimshaw (1979, 1981) noted that verbs like ask seem to semantically take a “question” complement, but that this complement can take the syntactic form of either a sentence (ask what the time is) or a noun phrase “concealed question” (ask the time). Other verbs, like wonder, allow the sentence complement but not the noun phrase (wonder what the time is, but not *wonder the time). Grimshaw suggests that semantic selection, like the selection for animate subjects Chomsky described in Aspects, must be distinct from selection for a syntactic category, i.e., subcategorization. She dubbed syntactic category selection “c-selection” and suggested an independence of c-selection and “s-selection” (selection for semantic category or features).
In responding to Grimshaw, David Pesetsky (1982) noted a missing cell in the table one gets by crossing the c-selection possibilities for verbs that s-select for questions. Although there are verbs like wonder that c-select for a sentence and not an NP, there are no verbs that c-select for an NP and not a sentence.
| c-selection for sentence | c-selection for NP | s-selection for question |
| ✓ | ✓ | ask |
| ✓ | ✘ | wonder |
| ✘ | ✓ | * |
Simplifying somewhat, based on this asymmetry, Pesetsky asks whether c-selection is necessary at all. Suppose verbs are only specified for s-selection. What, then, explains the distribution of concealed (NP) questions? Pesetsky notes that the distribution of noun phrases is constrained by what is called “case theory” – the need for noun phrases to be “licensed” by (abstract) case. So the ability to take a noun phrase complement is a special ability, case assignment, which is associated with the theory of case and the special status of noun phrases. By contrast, there is no parallel theory governing the syntactic distribution of embedded sentences. According to Pesetsky, then, verbs can be classified according to whether they s-select for questions. If they do, they will automatically be able to take sentential question complements, since complement sentences don’t require any extra special grammatical sauce. However, to take a concealed question, a verb must also be marked to assign case. The verb ask has this case-assigning property but the verb wonder doesn’t.
Perhaps, then, there is no c-selection – no “subcategorization features” – at all in grammar. Rather, the range of complements to verbs (along with nouns, adjectives, and prepositions) and their order and distribution would be explained by other factors, such as “case theory.”
But is it really true that no syntactic elements are specified to want to combine with nouns, verbs or adjectives? While it seems possible maintain that Ns, Vs, Adjs, and Ps don’t c-select, it would seem that other heads, like “Tense” or “Determiner”, want particular categories as their complements. And here’s where Grimshaw’s second important contribution to phrase structure theory will come in next time – the concept of an “extended projection” of a lexical item, like a verb (Grimshaw 1991).
References
Chomsky, N. (1957). Syntactic Structures. Walter de Gruyter.
Chomsky, N. (1965). Aspects of the Theory of Syntax. MIT Press.
Grimshaw, J. (1979). Complement selection and the lexicon. Linguistic Inquiry 10(2): 279-326.
Grimshaw, J. (1981). Form, function and the language acquisition device. In C. L. Baker and J. J. McCarthy (eds.), The Logical Problem of Language Acquisition, 165-182. MIT Press.
Grimshaw, J. (1991). Extended projection. Brandeis University: Ms. (Also appeared in Grimshaw, J. (2005). Words and Structure. Stanford: CSLI).
Marantz, A. (2019). What do linguists do? The Silver Dialogues.
Pesetsky, D. (1982). Paths and Categories. MIT: PhD dissertation.