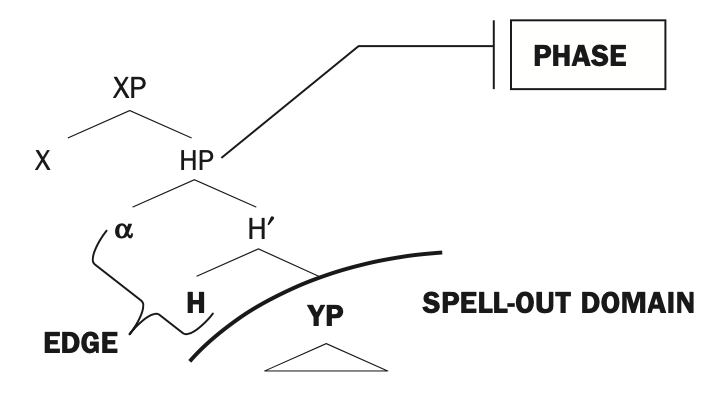
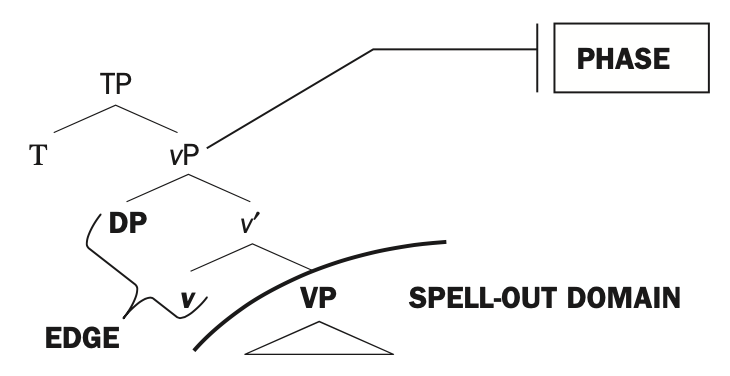
What stimulus properties are responsible for driving neural activity during speech comprehension? For quite some time, we’ve known that word frequency modulates brain responses like the ERP N400; higher frequency words elicit smaller amplitude responses. In addition, listeners’ expectancies for particular words, as quantified in Cloze probability ratings, also modulate reaction time and the N400; higher Cloze probabilities elicit faster RTs and smaller amplitude responses.
For variables that modulate brain responses to speech sounds, phoneme surprisal seems to robustly correlate with superior temporal activity around 100 to 140ms after the onset of a phoneme (Brodbeck et al. 2018), although we’ll show below that phoneme surprisal effects are not limited to this time window. As a variable, phoneme surprisal is a product of information theory – how much information a phoneme carries in context, where the usual context to consider is the “prefix” or list of phonemes before the target phoneme starting from the beginning of a word. As we have seen in previous posts, phoneme surprisal is conventionally measured in terms of the probability distribution over the “cohort” of words that are consistent with this “prefix.”
In considering the literature on phoneme surprisal, and in planning future experiments, we should distinguish between “phoneme surprisal” as a variable (PSV) and “phoneme surprisal” as a particular neural response (or multiple such responses) modulated by the phoneme surprisal variable (PSN). We should also be clear about the difference between using surprisal as variable without an account of why linguistic processing should be sensitive to this variable at a particular point of time and in a particular brain region, and using surprisal as a variable in connection with a neurobiological theory of speech processing, as say in the “predictive coding” framework (see e.g., Gagnepain et al. 2012).
On the first distinction, at the NYU MorphLab we have published two studies using the PSV that have discovered different – at least in time – neural responses sensitive to the variable. In Gwilliams and Marantz (2015), a study on Arabic root processing, we found that PSV computed over roots yielded a PSN on the third root consonant in the 100-140ms post phoneme onset time period in the superior temporal gyrus (see Figure 3 below). PSV measured at this third root consonant for the whole word, by contrast, did not yield a PSN in the same time frame. (The graph of PSV effects shows additional PSN’s after 200ms and after 300ms, which we will set aside.) 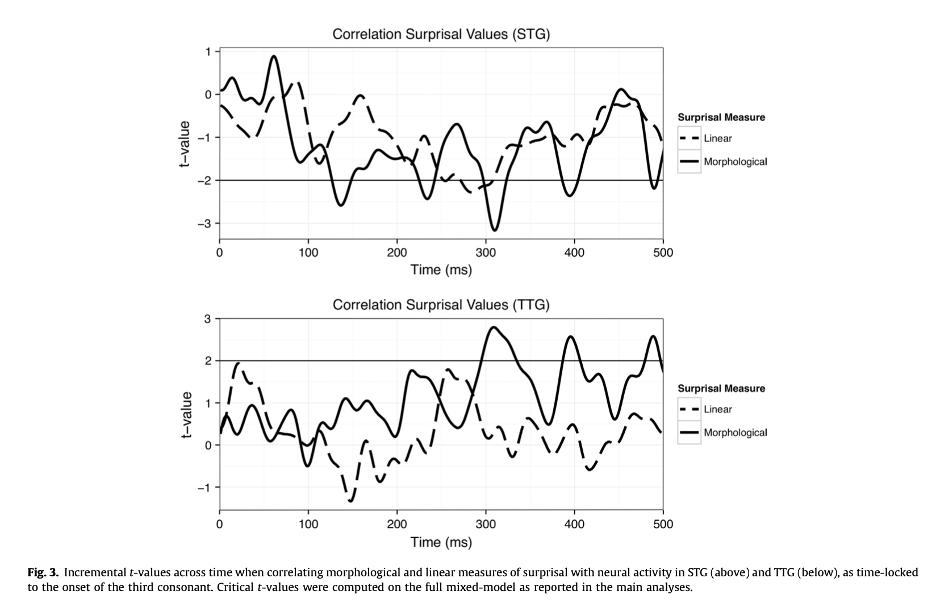
In Gaston & Marantz (2018), we examined the effect of prior context on the PSN of English words like clash that can be used either as nouns or as verbs. We computed PSV in various ways when these words were placed after to to force the verb use and after the to force the noun use. For example, we considered measuring PSV after the by removing from the cohort all the words with only verb uses but leaving the full frequency of the target word as both noun and verb in the probability distribution of the remaining cohort vs. also reducing the frequency of the target in the cohort by removing its verb uses as well. We found a set of complicated PSN responses sensitive to the contextual manipulation of PSV (see Figure 3 below). However, the PSN was not in the same time range as the (first) PSN from the Gwilliams and Marantz study but instead came 100ms later.
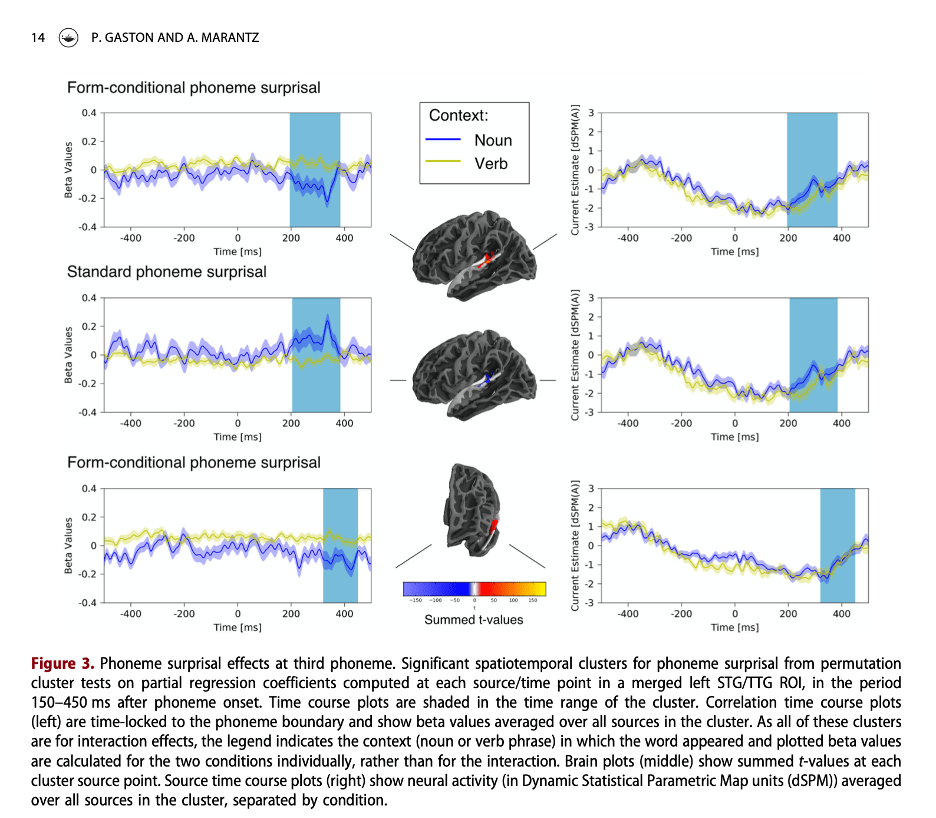
For these studies from the MorphLab, the fact that the PSV yielded distinct PSN’s was not crucial to the interpretation of the results. Of interest in the Arabic study was whether there was evidence for processing the root of the word independent of the whole word, despite the fact that the root and “pattern” morphology that make up the word are temporally intertwined. For the study on the effects of context, we were interested in whether the preceding context would modulate cohort frequency effects, and if so, which measure of cohort refinement provided the best modulator of brain responses in the superior temporal lobe. Our conclusions were connected to our hypotheses about the relationship between PSV and cognitive models of representation and processing, not to prior assumptions about PSN.
That being said, ultimately our goal is to understand the neurobiology of speech perception – the way that the cognitive models are implemented in the neural hardware. For this goal, we should be seeking a consistent PSN (or multiple consistent PSN’s) and develop an interpretation of this PSN within a neurologically grounded processing theory. For this goal, the literature provides some promising results. In a study examining subjects’ responses to listening to natural speech (well, audiobooks), Brodbeck et al. (2018) identify a strong PSN in the same time range and same neural neighborhood as the PSN in Gwilliams and Marantz’s Arabic study (see Figure 2 below). Brodbeck et al. did not decompose the words in their study, so PSV was computed based solely on whole word cohorts, and function and content words weren’t distinguished. While context, including word-internal morphological context, may have modulated the effects of PSV on the PSN, this simple whole word PSV measure nevertheless remained robust and stronger than other variables they entertained as potentially modulating the brain response. Laura Gwilliams’ ongoing work in the MorphLab has found a similar latency for a PSN from naturalistic speech, using different analysis techniques (and a different data set) from Brodbeck et al.
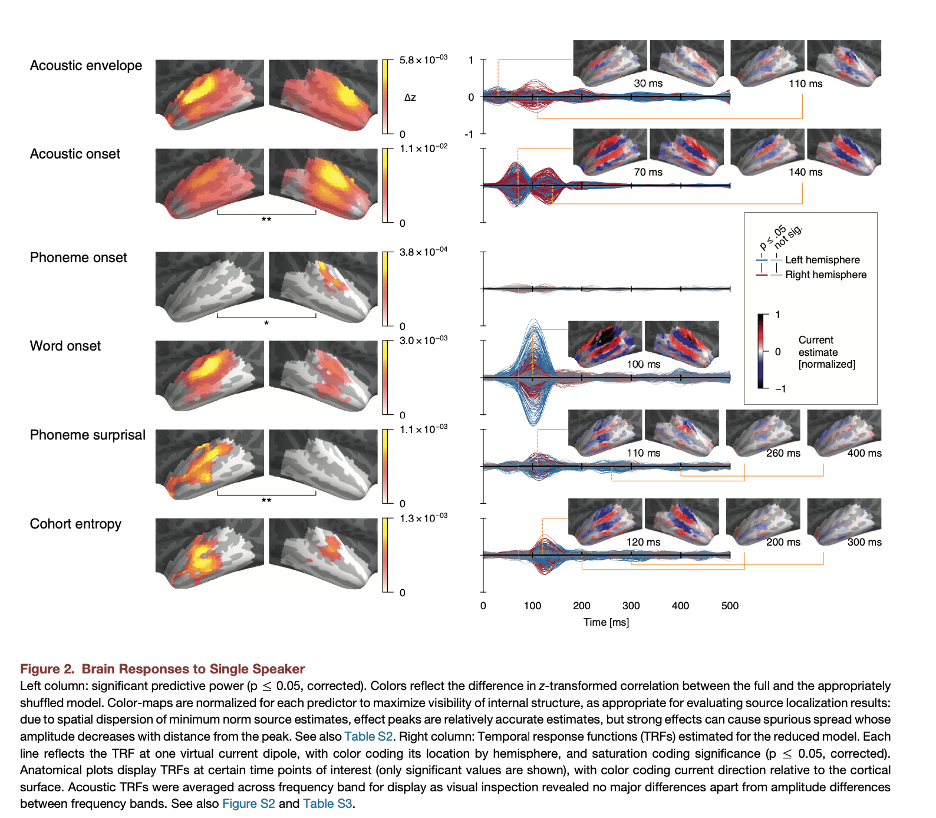
The timing and location of Brodbeck’s PSN response is broadly compatible with the timing and location of responses associated with the initial identification of phonemes, as measured, e.g., by ECoG recordings in Mesgarani et al. (2014) and subsequent publications (see Figure 1 below). This invites an interpretation of the PSN as a measure of the predictability of a phoneme being identified, rather than in terms of the information content of the phoneme. Such an analysis is part of the “predictive coding” framework as described, e.g., in Gagnepain et al. (2012). In this framework, a response that could be Brodbeck’s PSN in time and space is construed as an error signal proportional to the discrepancy between the predicted phoneme and the incoming phonetic information. It will be of great interest to tease apart predictions of a processing model based on predictive coding vs. one based on information theory. We note here the prediction made by Gagnepain et al. (2012) that we should not see, in addition to a PSV-related neural response, a response that is modulated by cohort entropy. However, Brodbeck et al. observe a robust entropy response that was close to the PSN both temporally and areally but nonetheless statistically independent (see their Figure 2 above).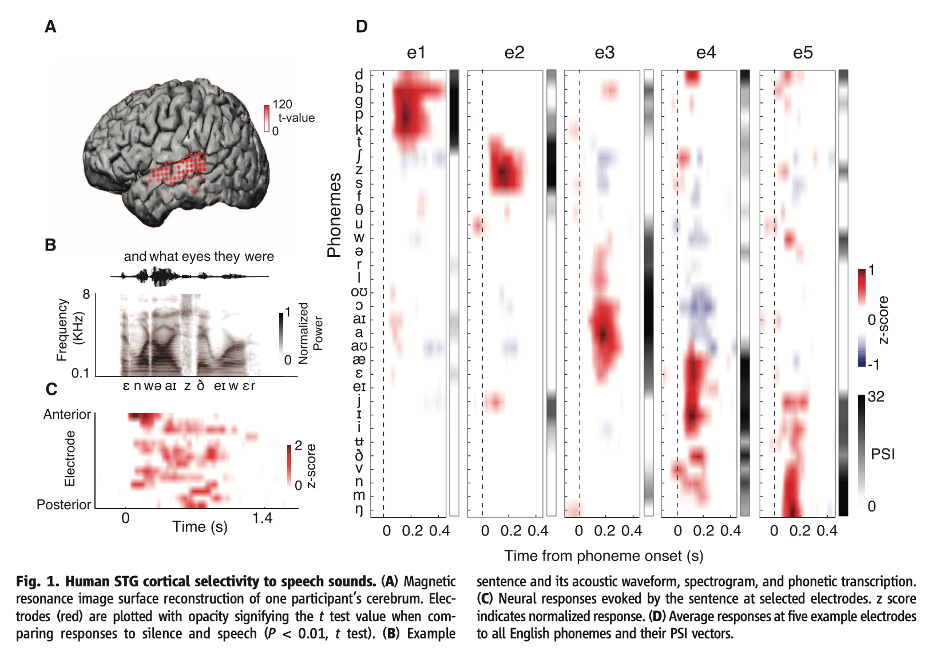
Returning to the topic of PSV responses in morphologically complex words, we see that it’s important to understand whether PSV responses are uniquely associated with a PSV that is computed using considerations like transition probability (the likelihood of an affix given the stem) and other factors that fix the probability of the affix before assessing the likelihood of the phonemes in the affix. One could imagine instead that the PSVs that matter most for the Brodbeck/Gwilliams early PSN is computed over cohorts of morphemes, without modulation associated with the contextual statistics of the morphemes. Functional morphemes (prepositions, determiners, complementizers) are highly predicted in syntactic context, but the PSV relevant to the Brodbeck/Gwilliams PSN might ignore syntactic prediction in assigning probability weights to the morphemes in the relevant cohort for the PSV. Consider that the context-modulated PSN we observed in the Gaston & Marantz paper was not this early PSN, but a significantly later response (with respect to phoneme onset), and that the Brodbeck et al. study apparently included functional morphemes without contextualizing their PSV to predicted contextual frequencies of these morphemes. A contextually unmodulated PSVwould not strictly speaking be an information theoretic PSV, since a contextually predicted phoneme is simply not as informative as a contextually unpredicted one, and this PSV would thus overestimate the information content of contextually predicted phonemes (say, phonemes in a suffix after a stem that highly predicts the suffix). Still, the field awaits a set of plausible processing theories that make sense of the importance of the non-contextual PSV and make further predictions for MEG experiments (that we can run).
References
Brodbeck, C., Hong, L. E., & Simon, J. Z. (2018). Rapid transformation from auditory to linguistic representations of continuous speech. Current Biology, 28(24), 3976-3983.
Gagnepain, P., Henson, R. N., & Davis, M. H. (2012). Temporal predictive codes for spoken words in auditory cortex. Current Biology, 22(7), 615-621.
Gaston, P., & Marantz, A. (2018). The time course of contextual cohort effects in auditory processing of category-ambiguous words: MEG evidence for a single “clash” as noun or verb. Language, Cognition and Neuroscience, 33(4), 402-423.
Gwilliams, L., & Marantz, A. (2015). Non-linear processing of a linear speech stream: The influence of morphological structure on the recognition of spoken Arabic words. Brain and language, 147, 1-13.
Mesgarani, N., Cheung, C., Johnson, K., & Chang, E. F. (2014). Phonetic feature encoding in human superior temporal gyrus. Science, 343(6174), 1006-1010.