Lexical access has been formalized in various bottom-up models of word recognition as the process of deciding, among all the words of a language, which word is being presented (orally or visually). In the auditory modality, thinking of the word as unfolding from beginning to end, phoneme by phoneme, the models imagine a search among all lexical items for the items beginning with the encountered phonemes. This “cohort” of lexical competitors consistent with the observed phonemes is winnowed down as more phonemes are heard, until the “uniqueness point” of the presented word, the point at which only a single item is left in the cohort. This final item is recognized as the word being heard.
| /k/ | /kl/ | /klæ/ | /klæʃ/ |
| clash | clash | clash | clash |
| clan | clan | clan | |
| cleave | cleave | … | |
| car | … | ||
| … |
So, for apparently morphologically simple words, like cat, word recognition in the cohort-based view involves deciding which word, from a finite list provided by the grammar of the language, is being presented. For psycholinguistic processing models, we can assign a probability distribution over the finite list, perhaps based on corpus frequency, and, for auditory word recognition, we can compute the probability of each successive phoneme based on its probability distribution over the members of the cohort compatible with the input string of phonemes encountered at each point.
But what about multimorphemic words, either derived, like teacher, or inflected, like teaches? One approach to modelling the recognition of morphologically complex words would be to assume that the grammar provides structured representations of these words as consisting of multiple parts, “morphemes,” but that these structured representations join the list of monomorphemic words as potential members of the cohorts entertained by the listener/reader when confronted with a token of a word. For psycholinguistic models, the probability of these morphologically complex units can be estimated from their corpus frequency, as with apparently monomorphemic words like cat.
An immediate issue arises, at least for inflection, that we can recognize words that we haven’t heard before. (Here, we can delay the question of how the productivity, or lack thereof, of derivational morphology might figure into an approach to morphological processing that separates derivation and inflection. The relevant issues at this point can be illustrated with inflection, like tense, agreement, case and number morphology.) Erwin Chan from UPenn has quantified this aspect of inflectional morphology (Chan 2008). As you encounter more inflected forms as a learner and fill out the “paradigms” of noun and verb stems in your language, you also encounter more new stems with incomplete paradigms. Figure 4.5 from Chan’s dissertation shows that many of the expected inflected forms of Spanish verb lemmas are frequently unattested. This is known as the sparse data problem. For any amount of input data, some inflected forms of exemplified stems will be missing, requiring one to use one’s grammar to create these inflected forms when they are needed.
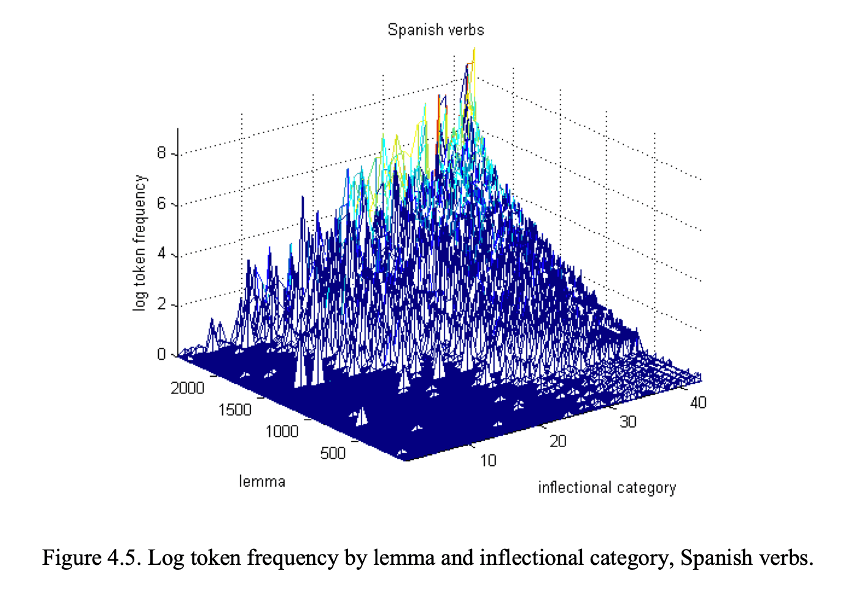
The sparse data problem shows that people must be able to process (produce and understand) words they haven’t heard or read before. But this might be not a real issue for word recognition if the list of words consistent with a grammar is finite. Speakers could use their grammars to pre-generate all the (potential) words of the language and place them in a list from which the cohort of potential candidates for recognition can be derived.
The immediate problem with this approach involves the psycholinguistic processing models alluded to earlier. These models require a probability distribution over the members of a cohort, and this distribution is estimated on the basis of corpus statistics. But what is the probability associated with a novel word, one generated by the grammar but not yet encountered? If one follows this approach to word recognition, one can estimate the expected corpus frequency of a morphologically complex word generated by the grammar based on the frequency of the stem and other factors. Fruchter & Marantz (2015), for instance, estimate the surface frequency of a complex word composed of stem X and suffix Y, F(X+Y), as a function of stem frequency (F(X)), biphone transition probability (the probability of encountering the first two phonemes of the suffix, given the preceding two phonemes of the stem, BTP(Y|X)), and semantic coherence (a measure of semantic well-formedness for a complex word, SC(X,Y)).
On a “whole word” approach to lexical access, where morphologically complex words join morphologically simple words on a list of candidates for recognition from which cohorts are computed, a single measure of word expectancy related to corpus frequencies of words and stems is used to derive frequency distributions over candidate words as wholes and, in the case of auditory word recognition, upcoming phonemes. The expectation is that recognition of a morphologically complex word will be modulated by whole word corpus frequency in the same way as a monomorphemic word.
The experimental work from my lab over the past 20 years, as well as related research from other labs, has shown, however, that this whole word approach to morphologically complex word recognition makes the wrong predictions, both for early visual neural responses in the processing of orthographically presented morphologically complex words and in the phoneme surprisal responses in the processing of auditorily presented complex words. That is, being morphologically complex matters for processing at the earliest stages of recognition, a fact that is incompatible with at least existing whole word cohort models of word recognition. For example, the presentation of an orthographic stimulus (a letter string) elicits a neural response from what has been called the Visual Word Form Area (VWFA) at about 170ms. This response is not directly modulated by the corpus frequency of a morphologically complex word, as might be expected if these words were on a stored list with monomorphemic words, but by a variable that reflects the relative frequency of the stem and the affixes. Our experiments have found that the transition probability between the stem and the affixes is the best predictor of the 170ms response (Solomyak & Marantz 2010; Lewis, Solomyak & Marantz 2011; Fruchter, Stockall & Marantz 2013; Fruchter & Marantz 2015; Gwilliams & Marantz 2018).
For auditory word recognition, a neural response in the superior temporal auditory processing regions peaking between 100 and 150ms after the onset of a phoneme is modulated by “phoneme surprisal,” a measure of the expectancy of the phoneme given the prior phonemes and the probability distribution over the cohort of words compatible with the prior phonemes. Work from my lab has shown that putting whole morphologically complex words into the list over which cohorts are defined does not yield good predictors for phoneme surprisal for phonemes in morphological complex words (Ettinger, Linzen & Marantz 2014; Gwilliams & Marantz 2015). Gwilliams & Marantz (2015), for instance, observe a main effect of phoneme surprisal based on morphological decomposition in the superior temporal gyrus but no effect based on whole word, or linear, phoneme expectancy (Figure 3).
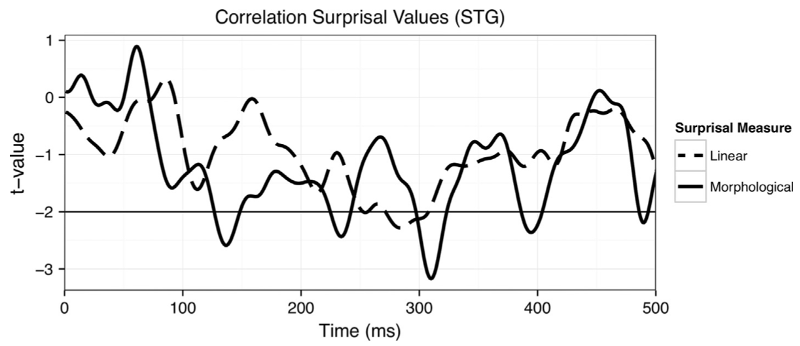
Figure 3. Correlation between morphological and linear measures of surprisal and neural activity in superior temporal gyrus
It is clear, then, that morphological structure feeds into the probability distribution over candidates for recognition to yield accurate measures of phoneme surprisal. However, we do not have a motivated model of how exactly this occurs. That is, although we have shown that morphological complexity matters in word recognition, we do not have a good model of how it matters.
In his dissertation, Yohei Oseki proposes to attack the issue of processing multimorphemic words by eliminating the distinction between word and sentence processing (Oseki 2018) – which is in any case a dubious categorical contrast given the insights of Distributed Morphology and related linguistic theories.
If morphologically complex words are “parsed” from beginning to end, even if presented all at once visually, then the mechanisms of recognizing and assigning structure to a morphologically complex word would be the same as the mechanisms of recognizing and assigning structure to sentences. The estimate of the “surprisal” of a complex word, then, would not be an estimate of the corpus frequency of the word but would be computed over the frequencies of the individual morphemes and over the “rules” or generalizations that define the syntactic structure of the word (see also Gwilliams & Marantz 2018). Work in sentence processing has been able to assign “surprisal” values to sentences in this way, and Oseki provides evidence that this approach yields surprisal estimates for visually presented words that correlate with the 170ms response from VWFA.
Oseki’s work, while promising, does raise a number of problems and issues to which we will return. However, it serves to connect word recognition directly with sentence processing, leading us to examine what we know and don’t know about the latter. In the essays to follow, we’ll detour through considerations of sentence recognition and of syntactic theory, with some side trips through aspects of phonology and of meaning, before returning to our initial question of identifying the best models of morphologically complex word recognition to pit against experimental data.
References
Chan, E. (2008). Structures and distributions in morphology learning. University of Pennsylvania: PhD dissertation.
Ettinger, A., Linzen, T., & Marantz, A. (2014). The role of morphology in phoneme prediction: Evidence from MEG. Brain and Language, 129, 14-23.
Fruchter, J. & Marantz, A. (2015). Decomposition, Lookup, and Recombination: MEG evidence for the Full Decomposition model of complex visual word recognition. Brain and Language, 143, 81-96.
Fruchter, J., Stockall, L., & Marantz, A. (2013). MEG masked priming evidence for form-based decomposition of irregular verbs. Frontiers in Human Neuroscience, 7, 798.
Gwilliams, L., & Marantz, A. (2015). Tracking non-linear prediction in a linear speech stream: Influence of morphological structure on spoken word recognition. Brain and Language, 147, 1-13.
Gwilliams, L., & Marantz, A. (2018). Morphological representations are extrapolated from morpho-syntactic rules. Neuropsychologia, 114, 77–87.
Lewis, G., Solomyak, O., & Marantz, A. (2011). The neural basis of obligatory decomposition of suffixed words. Brain and Language, 118(3), 118-127.
Oseki, Y. (2018). Syntactic structures in morphological processing. New York University: PhD dissertation.
Solomyak, O., & Marantz, A. (2010). Evidence for early morphological decomposition in visual word recognition: A single-trial correlational MEG study. Journal of Cognitive Neuroscience, 22(9), 2042-2057.
Leave a Reply