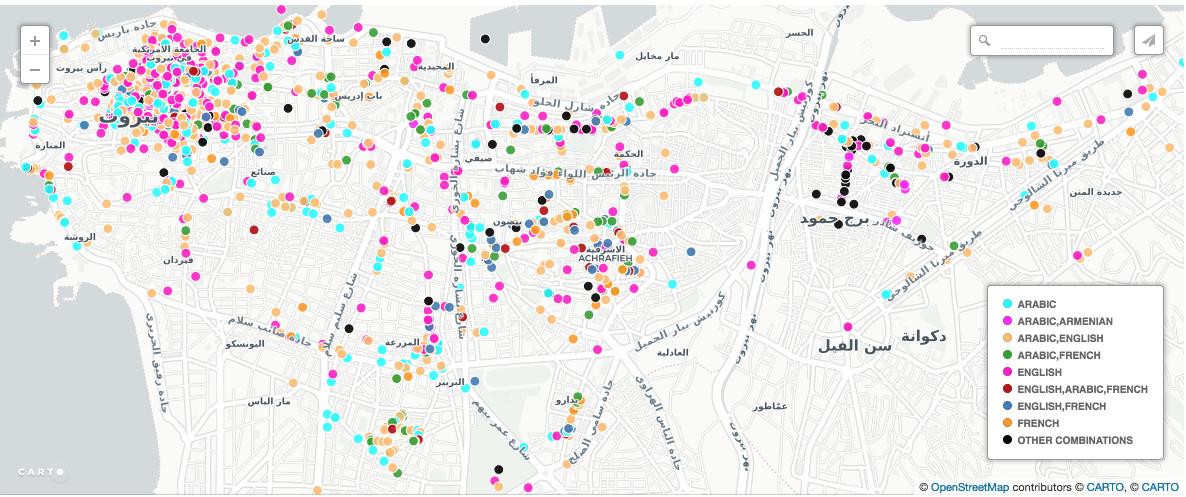
During the Fall 2017 semester, the CDS has been hosting three of Professor David Wrisley’s research assistants, all of whom are doing work on his various digital humanities projects. The first project is a continuation of his Linguistic Landscapes of Beirut project, a “digital project [that] generated some 2000+ images of multilingual writing from the Lebanese capital during the 2015-16 academic year. The original data was collected by smartphone using a form builder application known as Fulcrum. At the point of capture, images were geolocated and data collectors described them using a bounded set of tags. Beginning in the summer of 2017, we are cleaning the data, transcribing the language found within the images and adding more finely granular description. The result is a multi-lingual and multi-script archive of contemporary Beirut’s polyglossia. Each image corresponds to a file in the human-readable serialization language, YAML.”
The research assistants are using CDS hardware and software, including GitHub Desktop and the Atom text editor, to do transcriptions from images using his template, and then pushing them to GitHub for review and correction by the editorial group.
“The Open Medieval French (OpenMedFr) project aims to publish open, plain text versions of works written over four centuries of Medieval French writing. The main goal of the initiative in its early stages is to expand digital textual studies in medieval French through the creation of open corpora and a community of both users and producers of textual data.With such plain text versions at their disposal, researchers can use the texts within the scope of their advanced research questions (digital editions in TEI XML, text mining, NLP, alignment, entity extraction, etc.).
We work with digitized copies of a public domain books, process them by optical character recognition (OCR) and correct and annotate them by hand. In this first phase, the texts will be high quality, but they will not be 100% error free.”