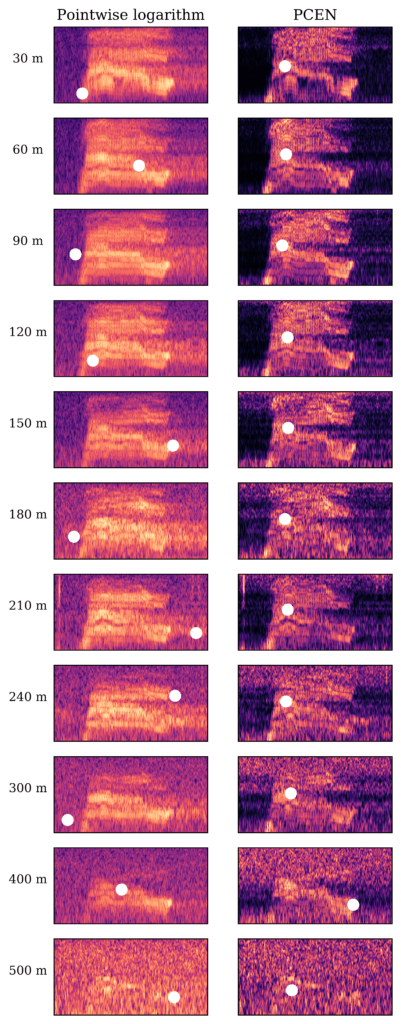
On October 18th, 2018, was held the “Speech and Audio in the North-East” (SANE) workshop at the headquarters of Google in Cambridge, MA, USA. Justin Salamon gave a 50-minute keynote on the recent research activities of BirdVox and Kendra Oudyk presented a poster, following her internship under the supervision of Vincent Lostanlen.
We reproduce the abstract and presentation material below.
Robust sound event detection in acoustic sensor networks
Justin Salamon
The combination of remote acoustic sensors with automatic sound recognition represents a powerful emerging technology for studying both natural and urban environments. At NYU we’ve been working on two projects whose aim is to develop and leverage this technology: the Sounds of New York City (SONYC) project is using acoustic sensors to understand noise patterns across NYC to improve noise mitigation efforts, and the BirdVox project is using them for the purpose of tracking bird migration patterns in collaboration with the Cornell Lab of Ornithology. Acoustic sensors present both unique opportunities and unique challenges when it comes to developing machine listening algorithms for automatic sound event detection: they facilitate the collection of large quantities of audio data, but the data are unlabeled, constraining our ability to leverage supervised machine learning algorithms. Training generalizable models becomes particularly challenging when training data come from a limited set of sensor locations (and times), and yet our models must generalize to unseen natural and urban environments with unknown and sometimes surprising confounding factors. In this talk I will present our work towards tackling these challenges along several different lines with neural network architectures, including novel pooling layers that allow us to better leverage weakly labeled training data, self-supervised audio embeddings that allow us to train high-accuracy models with a limited amount of labeled data, and context-adaptive networks that improve the robustness of our models to heterogenous acoustic environments.
[YouTube][slides]
BirdVox-Imitation: A dataset of human imitations of birdsong with potential for research in psychology and machine listening
Kendra Oudyk, Vincent Lostanlen, Justin Salamon, Andrew Farnsworth, and Juan Pablo Bello
Bird watchers imitate bird sounds in order to elicit vocal responses from birds in the forest, and thus locate the birds. Field guides offer various strategies for learning birdsong, from visualizing spectrograms to memorizing onomatopoeic sounds such as “fee bee”. However, imitating birds can be challenging for humans because we have a different vocal apparatus. Many birds can sing at higher pitches and over a wider range of pitches than humans. In addition, they can alternate between notes more rapidly and some produce complex timbres. Little is known about how humans spontaneously imitate birdsong, and the imitations themselves pose an interesting problem for machine listening. In order to facilitate research into these areas, here we present BirdVox-Imitation, an audio dataset on human imitations of birdsong. This dataset includes audio of a) 1700 imitations from 17 participants who each performed 10 imitations of 10 bird species; b) 100 birdsong stimuli that elicited the imitations, and c) over 6500 excerpts of birdsong, from which the stimuli were selected. These excerpts are ‘clean’ 3-10 second excerpts that were manually annotated and segmented from field recordings of birdsong. The original recordings were scraped from xeno-canto.org: an online, open access, crowdsourced repository of bird sounds. This dataset holds potential for research in both psychology and machine learning. In psychology, questions could be asked about how humans imitate birds – for example, about how humans imitate the pitch, timing, and timbre of birdsong, about when they use different imitation strategies (e.g., humming, whistling, and singing), and about the role of individual differences in musical training and bird-watching experience. In machine learning, this may be the first dataset that is both multimodal (human versus bird) and domain-adversarial (wherein domain refers to imitation strategy, such as whistling vs. humming), so there is plenty of for developing new methods. This dataset will soon be released on Zenodo to facilitate research in these novel areas of investigation.
[PDF]
The official page of the workshop is: http://www.saneworkshop.org/sane2018/