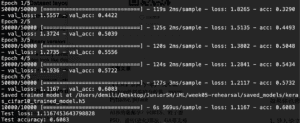
For CIFAR-10 dataset training, I first modified with the batch size and epochs variables. I first set them to batch_size = 32 and epochs = 5. The accuracy turns to be 0.6083 and test loss is 1.1167…
After searching, I get the importance of changing the batch_size value. First, the relation between one epoch and numbers of iterations and batch size is as the following formula: One Epoch = Numbers of Iterations = Train Data/batch size. So larger batch size means fewer iterations and faster processing speed. Also, enlarge the dataset means better memory utilization and greater efficiency. Also, large batch size may cause less fluctuation in the accuracy. But enlarge batch size out of the reasonable range cause larger memory capacity. And the numbers of iteration decreases means more time to adjust in order to reach the same accuracy. So it is necessary to find a proper batch size.
I changed the batch size to 1280 and epochs to 20. The accuracy is 0.48 and the loss is 1.42.

I then changed the batch_size to 32 and epochs to 100. It takes around 2 hours to complete the whole process.


 Above pictures show the accuracy from the first several epochs to 50 epochs and to 100 epochs. We can see that around 50 epochs, the accuracy is 0.76. And afterward, the increase in accuracy is very little, little fluctuation appears in the remaining epochs. As a result, with a batch size of 32 and 50 epochs may be proper parameters for the dataset training.
Above pictures show the accuracy from the first several epochs to 50 epochs and to 100 epochs. We can see that around 50 epochs, the accuracy is 0.76. And afterward, the increase in accuracy is very little, little fluctuation appears in the remaining epochs. As a result, with a batch size of 32 and 50 epochs may be proper parameters for the dataset training.
Then I tried with data augmentation. I first search on what is data augmentation, and why we need them on the internet. It said that when you do not have enough data, you can use ‘flip’, ‘translate’, ‘scale’… to create more data. And for example, without flipping the photos and a limited data set, the machine may think the biggest difference between a frog and a human is one is facing left and one is facing right. So if you input a photo that a human is facing left, the machine may think that it is a photo of a frog. So flipping the data will increase the accuracy by helping them to search the most important characteristics. But, with so many ways to process the image, such as scale, flip, translation, rotation, it is not true that using all the methods can help machine learn better. For example, if we want the machine to classify some standing person, there’s no need to flip a person upside down to tell the machine this is also a person. In fact, it wastes time to learn these things.
In CIFAR-10, I reference to David 9‘s code. I noticed that he changes the image on the horizaontal flip but not rescale of rotation or other changes, since it may not be reasonable to do so.

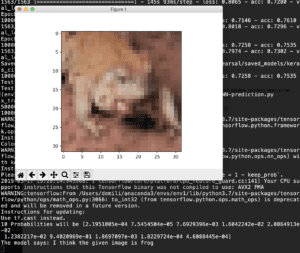
With a batch size of 32 and epochs of 20, the accuracy is 0.71111. The prediction result is as follows. 
Then I change the epochs to 50. The accuracy improves to 0.7545 and loss of 0.7258184. The prediction result is as follows.