Group Member – Casey, Eric
Github Repo – CartoonGAN-Application
Previous Report – Project Proposal

Continue reading “CartoonGAN on the Web | aiarts.week.07 | Midterm Process Blog – Casey & Eric”
Interactive Media Arts @ NYUSH
Group Member – Casey, Eric
Github Repo – CartoonGAN-Application
Previous Report – Project Proposal
Continue reading “CartoonGAN on the Web | aiarts.week.07 | Midterm Process Blog – Casey & Eric”
Overview
I changed the topic of my project from the ancient Chinese characters to the Hanafuda cards. There are a couple reasons why I changed the subject: first, I found that the idea I proposed before is more based on computer vision rather than artificial intelligence (it does not necessarily need deep learning to identify the resemblance between an image input and a certain Chinese character); second, I wanted to actually train my algorithm instead of utilizing the pre-trained models.

Hanafuda cards, or Hwatu in Korean, are playing cards of Japanese origin that are commonly played in South Korea, Japan, and Hawaii. In a single set, there are twelve suits, representing months. Each is designated by a flower, and each suit has four cards—48 cards in total. Hanafuda can be viewed as an equivalent of poker cards in Western, or mahjong in China as they are mostly used for gambles.
I got the inspiration from Siraj Raval’s “Generating Pokémon with a Generative Adversarial Network,” which trains its algorithm with the images of 150 original Pokémons and generates new Pokémon-ish images based on the data-set by using WGAN. I replaced the dataset with the images of hanafuda cards I found on the web, and modified the code to work accordingly with the newly updated data-set.
Methodology
Collecting the proper image set was the first thing I did. I scraped 192 images in total, including a scanned set of nineteenth century hanafuda cards from the digital library of the Bibliothèque Nationale de France, a set of modern hanafuda cards from a Japanese board game community, vector images of modern Korean hwatu cards from the Urban Brush, and a set of Hawaiian-style Hanafuda cards. I had to manually gather those images and trim out their borders, which may affect the result of generated images.

Although they have slightly different styles, they share same themes, symbols and compositions—as we can see from the image above, there are distinct hanafuda characteristics: including elements of the nature, Japanese style of painting, simple color scheme, and so on. I hope artificial intelligence can detect such features and generate new, interesting hanafuda cards that have not existed so far.
The code is comprised of three parts: Resize, RGBA to RGB, and the main GAN. First, as it is necessary to make the size of all image sources same, “Resize” automatically scales the images to the same size (256*404). Second, “RGBA2RGB” converts the RGBA images to RGB, namely from PNG to JPG. The first two steps are to standardize the images so they can be fed to the algorithm, the main GAN.
The GAN part has two key functions: Discriminator and Generator. The Discriminator function of this GAN keeps trying to distinguish real data from the images created by the Generator function. It has four layers in total, and each layer performs convolution, activation (relu), and bias. At the end of the Discriminator part, we use Sigmoid function to tell whether the image is real or fake. The Generator function has six layers that repeat convolution, bias, and activation. After going through the six layers, the generator will use tanh function to squash the output and return a generated image. It is remarkable that this Generator begins by randomly generating images regardless of the training data-set. And as training goes on, the random inputs will morph into something looks like hanafuda cards due to the optimization scheme, which is back-propagation.
Experiments
As I’m using a Windows laptop, there are some difficulties in terms of work submission to Intel DevCloud. After I figure out how to install needed dependencies(cv2, scipy, numpy, pillar) on the Intel environment, I’ll train the algorithm and see how I might improve the results. Here are a number of potential issues and rooms for improvement:

Above is a set of images generated by Pokémon GAN. Here we can clearly see some Pokémon-like features; and yet, they are still somewhat abstract. Aven pointed out that the result of my hanafuda cards are very likely to be as abstract as those Pokémons are. I need to do more research on how to make my potential results less abstract, or I may select a few interesting outputs and retouch them a little bit.
Since the data-set is comprised of cards of the three different countries, I’m so excited to see what will come out of this project. I’d like to find some “pairable” cards that share similar characteristics, so I can possibly group them as 13th or 14th month.
GITHUB: https://github.com/NHibiki-NYU/AIArts-Mojisaic
The project Mojisaic is a WeChat mini-app that can be launched directly in WeChat by a QRCode or link. The nature of WeChat mini-app is a hybrid app that displays a webpage but has better performance and higher permissions. With the help of WeChat mini-app, the ‘web’ could be started in a flash and act like a normal app. By using TensorFlowJS, Keras model can be converted and loaded on the web client. So, we can keep the power of HTML/CSS/JS as well as the magic of machine learning.
Firstly, I used a VGG like structure to build the model that detects emotion on one’s face.
Then, I find a dataset on kaggle, a data collecting and sharing website.
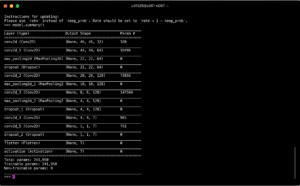
The dataset contains 28,709 samples in its training set and 3,589 in its validation set and testing set. Each sample consists a 48x48x1 dimensional face image and its classified emotion. There are totally 7 emotions that are labelled – Angry, Disgust, Fear, Happy, Sad, Surprise, and Neutral. With the help of this dataset, I started the training on Intel devCloud.

I run the training for 100 epochs and reaches 60% accuracy of emotion classification. According to the author of the previous model, the accuracy of training result lies between 53%-58%, so 0.6 is not a bad outcome.
Since I want my model to be run by JavaScript, I cannot use the model trained by Python/Keras directly. There is a tutorial on TensorFlow website about how to convert Keras model to TensorFlowJS format:
https://www.tensorflow.org/js/tutorials/conversion/import_keras
After I converted the Keras model to the TensorFlowJS model, I created a webpage and try to run the model on the web first before I step forward to WeChat mini-app.
I wrote a script to detect the emotion of people in the image that the user chooses to upload from the web interface, printing out the emoji of the emotion.
As I mentioned previously, WeChat mini-app is built with JavaScript so ideally TensorFlowJS can be used in the app. However, the JavaScript engine is specially customized by WeChat developers so that the library cannot perform fetch and createOffScreenCanvas in WeChat mini-app. Fortunately, a third-party library on GitHub helped in this case.
https://github.com/tensorflow/tfjs-wechat
It is a plugin for mini-app that overrides some interfaces in TensorFlowJS to make it act normally (although not good enough). In the WeChat mini-app, I use WebCam to detect the user’s face in real-time and place emoji directly on the face. By hitting the shot button, the user can save the image or send it to his/her friends.


There are mainly 2 obstacles when I made this project.
First, old model conversion problem. When I want to extract faces from a large image, I use a library called faceapi to run its built-in model to locate faces. However, the WeChat TensorFlowJS plugin cannot support faceapi. So, I should either convert its model to normal TensorFlowJS model or modify the code directly to make it support WeChat API. After countless failures of converting old TensorFlow layer models, I surrendered and chose to modify faceapi source code. (Although it took me nearly 3 days to do that…)
Secondly, the plugin in WeChat mini-app is not perfect enough – it does not support worker in its context. So the whole computational process needs to be done in the main thread. (that’s so exciting and scaring…) Although WeChat mini-app is integrated with 2 threads – one for rendering and the other for logic. The rendering part does not do anything in fact – there are no data binding updates during the predicting process. So all the computational tasks (30 fps, about 30 face detections, and emotion classifications) make WeChat crashes (plus the shot button not responding). The temporary way to solve it is to reduce the number of predictions in one second. I only do a face detection every 3 frame and emotion classification every 15 frames to make the app appears responding.
Discoveries:
WordtoVec doesn’t work with phrases. The sole functionality is mapping individual words to other words. And even then, it does such a horrific job that barely as of the movie plot is distinguishable by searching these related terms. Half the associated words just are not usable after training the model on the script from Detective Pikachu.
I don’t think I can use this with multiple movies? Can you imagine how difficult it would be to pair a movie with the phrase? At first I was thinking about giving each movie an ID and manually adding it to every word… something like DP:are (the word are in Detective Pikachu)… I just don’t think that’s stratifiable.
SOUND CLASSIFIER
This was one of the parts of my project, meant to be sort of a last step, making it the sole interaction. This is really something I only plan on implementing if I get the rest of the project functional! But I thought since I was experimenting as much as I was, it was time to explore this other element as well.
This failed. I don’t think there is any other way to explain this, I think there is a serious issue with using this specific ml5 library with phrases. The confidence level of the sound-classifier with just the eighteen phrases is too low to be used in my project, done. End of story. The identifier can’t even identify the set words IT SHOULD KNOW!
Progress Report:
I know what I need to use, it’s now just a matter of learning how to use things that are beyond the scope of the class. Or at the very least, beyond my current capabilities. This is a good start and I hope to have a better actually working project for the final. For now the experimentation has led to a clearer path.
Original Plan:
Build a project that takes audio input and matches that audio input to the closest equivalent quotation from a movie, yielding the video clip as output.
Use WordtoVec to complete this with SoundClassification.
Now it looks like, I will have to re-evaluate. There is a really nice ITP example: Let’s Read a Story that I want to use to guide me… maybe there is a way to splice scripts together? Granted, that was never an idea I was interested in pursuing. I don’t know if it is too late to change my topic.
(Please see Midterm post for samples of failed tests)
Overview
For the midterm project, I developed an interactive two player combat battle game with a “Ninjia” theme that allows players to use their body movement to control the actions of the character and make certain gestures to trigger the moves and skills of the characters in the game to battle against each other. This game is called “Battle Like a Ninjia”.
Demo
Code:
https://drive.google.com/open?id=1WW0pHSV2e-z1dI86c9RLPnCte3GflbJE
Methodology
Originally, I wanted to use a hand-tracking model to train a hand gesture recognition model that is able to recognize hand gestures and alter the moves of the character in the game accordingly. I spent days searching for an existing model that I can use in my project, however, I later found that the existing hand tracking models are either too inaccurate or not supported for CPU. Given that I only have one week to finish this project, I didn’t want to spent too much time on searching for models and ended up with nothing that can work. Thus, I then turned to use the PoseNet model. But I still do hope I can apply a hand-tracking model in the project in the future.

(hand gesture experiments ⬆️ didn’t work in my project)
In order to track the movement of the players’ body and use them as input to trigger the game, I utilized the PoseNet model to get the coordination of each part of the player’s body. I first constructed the conditions each body part’s coordination needs to meet to trigger the actions of the characters. I started by documenting the coordination of certain body part when a specific body gesture is posed. I then set a range for the coordination and coded that when these body parts’ coordinations are all in the range, a move of the characters in the screen can be triggered. By doing so, I “trained” the program to recognize the body gesture of the player by comparing the coordination of the players’ body part with the pre-coded coordination needed to trigger the game. For instance, in the first picture below, when the player poses her hand together and made a specific hand sign like the one Naruto does in the animation before he releases a skill, the Naruto figure in the game will do the same thing and release the skill. However, what the program recognize is actually not the hand gesture of the player, but the correct coordination of the player’s wrists and elbows. When the Y coordination of both the left and right wrists and elbows of the player is the same, the program is able to recognize that and gives an output.



(use the correlation of coordination of wrists as condition to “train” the model to recognize posture)
As is shown in the above pictures, when the player does one specific body gesture correctly, and the program successfully recognize the gesture, the character in the game will release certain skills, and the character’s defense and attack (the green and red chart) will also change accordingly. The screen is divided into half. PlayerA standing in front of the left part of the screen can control Naruto’s action with his body movement and PlayerB standing in front of the right part can control Obito. When the two characters battles against each other, their HP will also change according to the number of their current attack and defense.
Experiments
During the process of building this game, I encountered many difficulties. I tried using the coordination of ankles to make the game react to the players’ feet movement. However due to the position of the web cam, it’s very difficult for the webcam to get the look of the players’ ankle. The player would need to stand very far from the screen, which prevents them from seeing the game. Even if the model got the coordination of the ankles, the numbers are still very inaccurate. The PoseNet model also proves to be not very good at telling right wrist from right wrist. At first I wanted the model to recognize when the right hand of the player was held high and then make the character go right. However, I found that when there is only one hand on the screen the model is not able to tell right from left so I have to programmed it to recognize that when the right wrist of the player is higher than his left wrist, the character needs to go right…A lot of compromise like these were made during the process. If given more time, I will try to make more moves available to react to player’s gesture to make this game more fun.I will also try to build an instruction page to inform the users of how to interact with the game, such as exactly which posture can trigger what moves.