Initial Thought
My expected midterm project is an interactive virtual instrument. Firstly, the trained model can identify the differences in how musical instruments are played. Once it gets the result it will play the corresponding sound of the instrument. Also there will be a picture of the instrument on the screen around the user.
For example, if the user pretended to be playing guitar, the model would recognize the instrument is guitar and automatically play the sound of guitar. Then there will be an image of guitar showing on the screen. The expected result is that it looks like the user is really playing the guitar on the screen.
Inspiration
My inspiration is a project called teachable machine. This model can be trained in real time. The user can make some similar poses as the input for a class. The maximum of the class is 3. Each pose correspond an image or gif. After setting up the dataset, once the user makes one of the three poses, the corresponding result will come out.
For me the core idea is excellent but the form of output is a little bit. There are also some projects about motion and music or other sound.
So I want to add audio as output. Also the sound of different musical instruments is really artistic and people are familiar with it. Thus my final thought is to let users trigger the sound of the instrument by acting like playing the corresponding musical instrument.
Technology
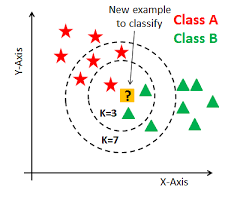
In order to achieve my expectation, I need the technology to locate each part of my body and to identify different poses and then classify them automatically and immediately. According to the previous knowledge, I decide to use PoseNet to do the location part.

I plan to set a button on the camera canvas so that the users don’t need to press the mouse to input information and the interaction will be more natural. To achieve it, I need to set a range for the coordination of my hand. When I lift my hand to the range, the model will start receiving the input image and 3 seconds later it will automatically end it. Next time the user makes similar poses the model will give corresponding output. KNN is a traditional algorithm to classify things. So it can be used to let the model classify the poses in a short time and achieve real time training.
Significance
My goal is to create a project to let people interact with AI in an artistic and natural way. They can make the sound of a musical instrument without having a real physical one. Also it is a way to combine advanced technology and daily art. It provides an interesting and easy way to help people learn about and experience Artificial Intelligence in their daily life.
