Intro
For this week’s research, I’ve run the program 8 times in total to experiment on how different machine specs and training setup influence the accuracy of the classification and the time spent. I experimented on the influences the valuables such as epoch (number of iterations), the batch size (number of samples per gradient update) and the pool size (the size of the pooling) respectively exert on the performance of the program.
The Epoch Variable
Firstly, I only changed the variable epochs and make the other settings the same. The results are as follows.

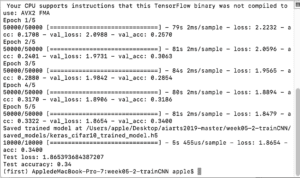
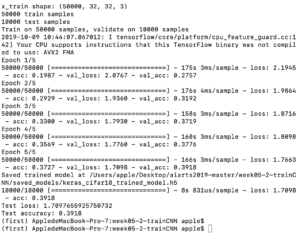
I first changed epochs to 10. It took almost 18 minutes for the program to finish the 10 iterations, yet still the test accuracy is only 0.4711.
![]()
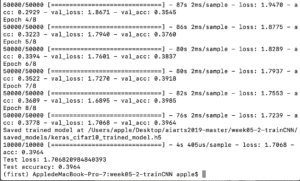
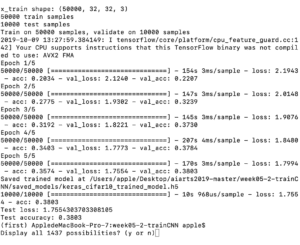
I then changed the epochs to 5 and 3, and left other settings unchanged. The test loss is now 1.83 and the accuracy is 0.4074 when epochs equals to 5, and the time required for the program to finish iterations is 9.4 minutes. And when epoch equals to 3, it took 5.9 minutes for the program to finish and the test loss is only 1.73 and test accuracy is 0.3977.
![]()

![]()

Discovery
According to the comparison between the result when epochs equals 10 and the results when epochs equals 5 and epochs equals 3, it appears that the smaller epochs is, the lower the test accuracy is and the higher the test lost is. There seems to be a positive correlation between the number of epochs and the test accuracy and a negative correlation between epochs and the test loss. But whether such pattern is definite or not is questionable. However, one thing for sure is that the larger the epochs, the more the time is spent for the program to finish because it has to iterate for more times.
The Batch Size Variable
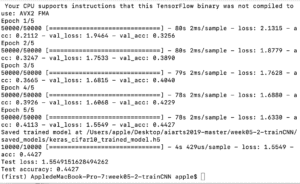
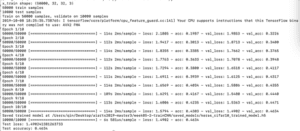
I then only changed the variable epochs and make the other settings the same. The results are as follows.

![]() .
. 


![]()

Discoveries
It seems that the smaller the batch size is, the higher the test accuracy is. I actually thought the result should be the other way around…But I’m guessing the reason behind this is that since the batch size is smaller, it took longer time for the program to finish examining all the samples, which requires more times to finish all samples, so the time is longer and the accuracy is higher…….?
The Pool Size Variable
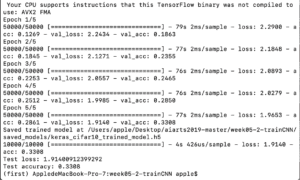
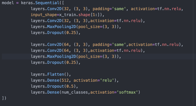
Finally, I decided to research on how the pool size variable influences the accuracy of the estimation. I only changed the pool size value and left other values the same. The results are as follows.

 .
. 
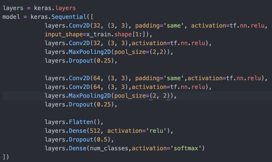 .
. 
Discoveries
In terms of the pool size variable, it seems that the larger the pool size is, the less time is needed for the program to finish and the lower the accuracy is. I guess it’s because when the pool size is large, it took fewer times for the program to compare the sample one pool by one pool. And when the times of comparison is less, the estimation becomes rough too, thus lowering the accuracy.
Thoughts and Questions
In conclusion, this experiment showed me that there exists three correlations between the performance of the program and its training set up (epoch, batch size, pool size). it seems that the larger the epoch is, the more the time spent is and the higher the accuracy is. The larger the batch size is, the faster the program finishes and the lower the accuracy is. Same with the pool size. The larger the pool size is, the less time is required and the lower its accuracy is. But due to the limited data collected from my experiment, I’m still not sure to what extent the influence these variables exert on the program’s performance. I’m even not sure if these correlations are definite at all time. Because when in class, I encounter one situation where the program gets higher accuracy when the epoch equals to 2 than when it equals to 3. Thus, I believe that in order to better understand the deeper relation behind the variables and the performance, I still need to do more research about the structure of such program and the purpose of its.