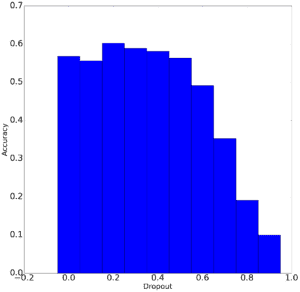
Background: For this week’s assignment, we were introduced to epochs and other inner workings of training. We have been assigned to look into the different variables and tweak them in order to look at the various effects it has on the end result such as loss and accuracy. I first tweaked epochs( number of times it runs), then I moved to tweak the batch size and later the pool size to test the performance.
Machine Specs: 
Variations of the Epoch: I first changed Epoch time by making it from 100 to 10 to see faster results.
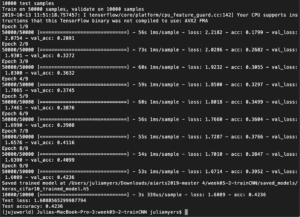
10Epoch
It took me about 25 minutes to complete the whole run. Immediately we can see that 10 iterations result in an accuracy of only 0.4077 and a loss of 1.6772. We can’t really do anything with a single experiment so therefore we need to refer to the next photo of 8 epochs.
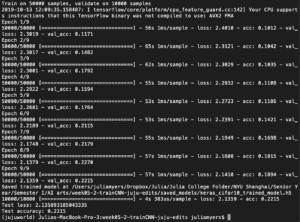
8Epoch

This time it took me 20 minutes to complete the whole run. The test run ended with a loss of 1.7213 and an accuracy of 0.401. The loss increased quite a bit within a difference of 2 epochs while the accuracy difference was only 0.006.
5Epoch
 Let’s check the 5 epoch run. The time it took me to run was actually pretty fast compared to the previous two tests at 12 minutes. However, the accuracy is substantially different at a 0.3636 and a loss of 1.8298.
Let’s check the 5 epoch run. The time it took me to run was actually pretty fast compared to the previous two tests at 12 minutes. However, the accuracy is substantially different at a 0.3636 and a loss of 1.8298.
It seems that the effectiveness of running multiple epochs is shaped like a curve on a graph. You can only get substantial improvements up until a point. After that certain point, the improvements get slower and slower, requiring more and more processing.
Batch Size Experiment:
Looking through sites like Quora I came across an article stating how different batch sizes can have an effect on the accuracy of the model. After looking through people’s answers and posts, it seems like a batch size of 64 seems to be a good experiment. I ran the test of Batch size 64, 128, 256 with 5 epochs.
Batch 64
Overall the test took me about 12 minutes to finish a test of 5 epochs and a batch size of 64 and immediately we can see a huge difference in the accuracy compared to 2048 batch size test. The accuracy is at a whopping 0.5594 and a loss of 1.2511.
I wasn’t expecting a huge amount of success in stats from a small batch size.
Batch 128

This time we doubled the 64 batch to a 128. This made it slightly faster at 11 minutes and 30 seconds. However, we are starting to see a drop in accuracy and an increase in loss. Accuracy is 0.5223 and the loss is 1.3298.
It would seem that the higher a batch size increases, the less effective it becomes at 5 epochs.
Batch 256

Test loss was at 1.4259 and the accuracy at 0.4896. Run time is at 10~minutes
Once again we see that increasing the batch size will not help us when we keep the epoch at 5.
After having run 3 tests corresponding to variation in the batch size, I realize that increasing the batch size past 64 is not a good idea if I want my accuracy high and loss low. I’m now interested in founding out if changing the batch size to below 64 will increase the success of the test. I decided to test this idea out by running a test with a batch size of 32.
Batch 32

I was surprised that the test produced a much better result at 0.6237 accuracy and a loss of 1.08. Run time of 13 minutes.
What I now understand from the two types of tests that I have conducted is that epoch runs will start to stagnate after a certain number of runs. It will start to produce significantly higher results up until a point and any number of runs after that will be producing lower and lower differences than those before it.
Batch size also plays a large role in the accuracy and loss of the test. It seems to me that 32-64 is a solid batch size for this test and I’m sure that the results would have been better if we were to increase the epoch runs.
It would seem that there must be a perfect combination of these two elements when training a model to increase success.