I played with the ml5.js together with p5.js model called “sketch-rnn”. Its idea is drawing with artificial intelligence. The trained model in sketch-rnn would allow the user to pick a category and let the user start drawing first. After the user stops drawing (release the left-click on the mouse), sketch-rnn will automatically complete the rest of the drawing based on the stroke the user made previously and turn it into the shape of the chosen category. It’ll then automatically continuously generate similar artworks until the user presses the “clear” button. The model aims at suggesting humans collaborate with artificial intelligence on art. Currently, due to the limited models in its database, the drawings are rather ragged, but with the collection of more paintings, sketch-rnn can probably create aesthetically-valued works with the human in the future.
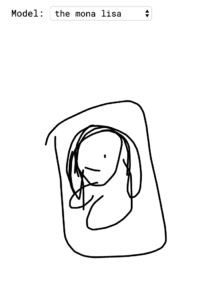
The following is what happened after I chose Mona Lisa in the category and draw a circle to start.

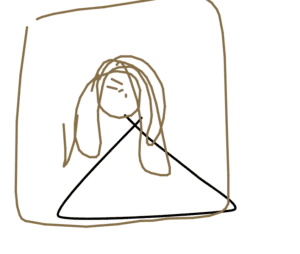
I then try to draw something completely not connected to any elements in the category I choose, I want to see if the AI can cleverly reshape the default pictures in its database. For example, I choose Mona Lisa as my category again and draw a triangle first.
The first drawing turned out good, ai cleverly used my triangle as the body of Mona Lisa. But then I found out that the triangle was no more than some lucky original resources hidden in the database.
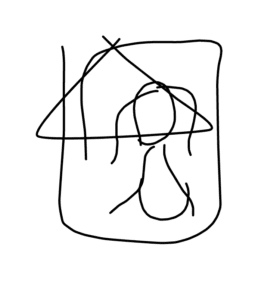
The following drawings didn’t go well, sketch-rnn simply covers my triangle with “Mona Lisa” resources in its database, which make me assume that if this ai can’t find any element in its database similar to the user’s drawings, it would just draw a completely new drawing to cover the original stroke.
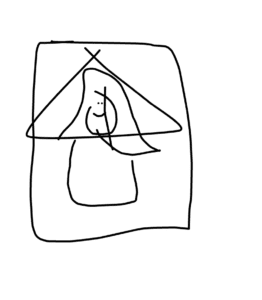
It turns out that my assumption is not entirely right. Even though in the Mona Lisa example it is covering and redrawing, in many other trials I conducted later, it still tries to recognize the basic outline of your drawing and is trying to complete the work with a few more strokes. Sometimes, however, it’s hard to recognize what it’s drawing when I draw a huge mess first and it finishes it by adding on some simple strokes.
I’ve never had experiences in training models before but I tried to read its sample code.
Link: https://github.com/tensorflow/magenta-js/tree/master/sketch
It first implements a set of models for every category, in the sample code, it’s using the cat model as an example. The user’s pen is tracked to see if it has started drawing & finished drawing, previous and after coordinates of the stroke are stored and the model is set to the initial state. After the pen state is stored, it is transferred into the model’s state. The parameters of the model state are traced. The model then samples the coordinates and reset the pen status to the coordinate it collects and finish the drawing according to the cat model resources.
There are certain terms I don’t understand in this code, for example, I don’t understand how the amount of certainty functions here.
Additionally, I can’t locate the code where the model compares the shape of the user’s drawing to the ones in the database, or is it just using the ratio calculated from the coordinates to match with the models.