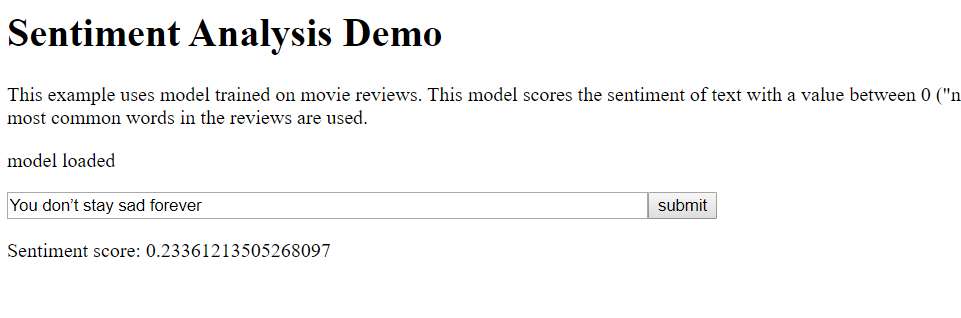
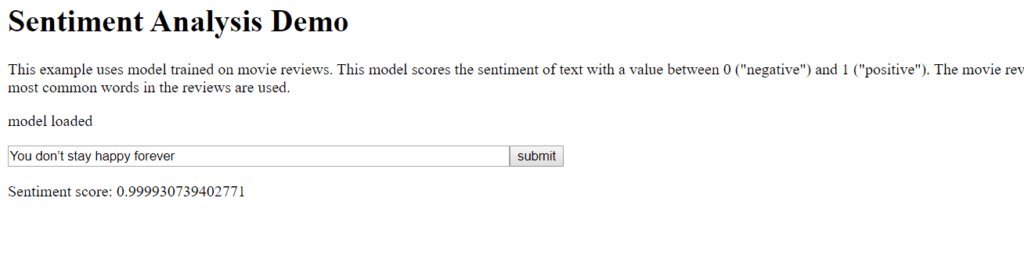
Among the number of ml5.js examples I tried, what I enjoyed the most to play around with was the “Sentiment Analysis Demo.” The model is pretty simple: you put some sentences, and the algorithm will score the given text and identify which sentiment is expressed—in this model, it gives you a value between 0 (negative) and 1 (positive).
The developers of this model noted that this example is trained with a data set of movie reviews, which makes sense because most of the film reviews have both comments and ratings. I think it is a clever way of collecting data for this sort of sentiment analysis model: a large enough collection of data for free!
So I began with inserting some quotes that are either *obviously* positive or negative, just to see if this model can do the easiest tasks.

It’s not a challenging task for us to tell whether what he says is positive. Pretty much same for the analysis model as well, it yielded a result of 0.9661046.

And for Squidward’s quote, the model identified it with confidence: 0.0078813. One thing I noticed from this quote is, the word “cruel” here is presumably the only word that has a negative connotation, in this sentence. I removed that single word and guess what; the model seems quite puzzled now. It gave me a surprising result of 0.5622794, which means the sentence “It’s just a reminder that I’m single and likely to remain that way forever,” according to the algorithm, falls into a gray zone between negative and positive. And yet, this sentence without the word “cruel” still seems somewhat negative for us. An idea came to my mind: is this algorithm smart enough to understand sarcasm?
“If you see me smiling it’s because I’m thinking of doing something bad. If you see me laughing, it’s because I already have.”
I googled up for some sarcastic sentences without any “negative words.” The result was 0.9988156. Not sure if the lines above are more positive than what Spongebob has said with glee, but the algorithm thinks so anyway.
“Algorithm, I love how you look everything on the bright side. You’re smarter than you look. I wish I could be as confident as you are, haha.”
I inserted this sort of backhanded compliment and it seemed pretty much flattered; it showed a result of 0.9985754. Now I feel somewhat bad for this algorithm, as if I’m making a fool of it. The last text I inserted is, all the text I’ve written so far.
For some reason the result was 0.9815316. I enjoyed doing some experiments with this model, because it’s pretty interesting to ponder about the results it has shown. Observing how an omission of the single word can dramatically change its result, I think a word-by-word approach has certain limits. In coder’s perspective, I’m wondering how I may improve this sentiment analysis model to the point which it can comprehend an underlying “sarcasm.” It’ll be a tough challenge, but definitely worthy in terms of computational linguistics and affective computing. Hope Siri and I can happily share the lovely act of sarcasm someday.