The technical simplicity of this project shows that AI doesn’t have to be scary or complex in order to use it: it can be a simple tool for artists looking to explore new digital mediums to create something visually interesting.
There is also a lot of discussion surrounding AI art in terms of who the artist is: is it the neural network, or is it the person who programmed the work? A lot of people seem to view this debate as very black and white in terms of believing that the artist is solely the neural network or the artist is solely the programmer. Regardless of what your opinion may be surrounding this debate, I think this project is an example of AI art where I would argue that both the programmer and the AI components equally work together to create the outcome. It doesn’t have to be an all-or-nothing scenario: the point of AI is to help us achieve certain outcomes more easily, so why not use it to work together rather than treating it as something that is taking away human creativity?
Further Development
I can see this project taking two different routes if I were to further develop it. The first route is to make it more user-friendly in order to make this kind of art more accessible to other people. In this case, a better interface would absolutely be necessary. The whole hover-to-start setup worked fine for me, but it might not be so intuitive or useful for others. Some kind of countdown before the drawing process starts, as well as an option to save the completed piece or automatically record it rather than having to manually take a screen capture video would make more sense. Additionally, making the artwork customizable from the interface side would be good to add such as being able to change the colors, size of the ellipses, or even change the shape entirely, rather than having to go into the style.js code to change these aspects.
The second route would be to further explore the concept as a personal artistic exploration. This option is definitely more open-ended. I could try and apply more machine learning skills; for example, I still really like the idea of AI generative art, so what if a GAN or DCGAN could make its own similar pieces based on these body movement pieces? This is conceptually interesting to me because it’s like giving a neural network its own set of eyes. It’s like some machine is watching you and can predict your movements, converting the artwork into a statement on privacy in today’s digital world rather than just an exploration of body movement over time.
Full documentation
(with updated background + motivation for new concept): https://docs.google.com/document/d/1DGs7plWL98vslkEo1t7phG4EcR2uOVikXQ4AFmjzsZI/edit?usp=sharing
For the midterm, I decided to create an interactive sound visualization experiment using posenet. I downloaded and used a library called “Simple Tones” containing multiple different sounds of various pitches. The user will use their left wrist to choose what sound they want to play by placing their wrist along the x-axis. This project was inspired by programs such as Reason and FL Studio as I like to create music in my spare time.
Although I originally planned to create a framework for webVR on A-Frame using posenet, the process turned out to be too difficult and beyond my capabilities and understanding of coding. Although the idea itself is relatively doable compared to my initial proposal, I still needed more time to understand how A-Frame works and the specific coding that goes into the 3D environment.
Methodology
I used the professor’s week 3 posenet example 1 as a basis for my project. It already had the code which allows the user to paint circles with their nose. I wanted to incorporate music into the project, so I looked online and came across an open-source library with different simple sounds called “Simple Tones”.
I wanted the position of my hand in the posenet framework to play sounds. Therefore I decided that the x-axis of my left wrist would be used to determine the pitch.
if (partname == “leftWrist”) {
if (score > 0.8) {
playSound(square, x*3, 0.5);
let randomX = Math.floor(randomNumber(0,windowWidth));
let randomY = Math.floor(randomNumber(0,windowHeight));
console.log(‘x’ + randomX);
console.log(‘y’ + randomY);
graphic.noStroke();
graphic.fill(180, 120, 10);
graphic.ellipse(randomX, randomY, x/7, x/7);
the “playSound” command and its attributes relate to the library that I have in place. Because the x-axis might not have high enough numbers to play certain pitches and sounds, I decided to multiply the number by 3. Left is high-pitch, while the right is low-pitch.
I ran it by itself and it seemed to work perfectly.
After some experimentation, I also wanted some sort of visual feedback that would represent what is being heard. I altered the graphic.ellipse to follow the x-axis coordinate of the left wrist. The higher the pitch (the more left it was on the axis) – the bigger the circle.
The end result is something like this. The color and sounds that it produces give off the impression of an old movie.
Experience and difficulties
I really wanted to add a fading effect on the circles, but for some reason, it would always crash when I write a “for” loop. I looked into different ways to produce the fading effect, but I wasn’t able to include it in the code.
I would also try to work on my visual appearance for the UI. It does seem basic and could use further adjustment. However, currently, this is as much as my coding skills can provide.
This idea and concept did seem to be a very doable task at first, but it required a lot more skill than I expected. However, I did enjoy the process, especially the breakthrough moment when I could hear the sounds reacting to my movement.
Overall, I have now learned how to use the positioning of a bodypart to do something. Going further, I do want to work on the webVR project and this experience can help in the understanding and implementation.
Social Impact:
In the process of my midterm, I worked on two different projects. The first project was pairing WebVR with posenet in order to develop a means to control the VR experience with the use of the equipment required. The second project was the one I presented in class – Theremin-inspired posenet project. Although I only managed to complete one posenet project, I believe that both projects have a lot of potential for social impact.
First, let’s talk about the WebVR project. The initial idea behind the project was to make VR more inclusive by allowing people without the funds to buy the equipment to experience VR. HTC Vive and other famous brands all cost over 3000RMB to purchase. By allowing posenet to be used inside WebVR, we can allow anyone with an internet connection to experience VR. Obviously, the experience won’t exactly be the same, but it should give a similar enough experience
Secondly, the Theremin-inspired project. I found out about the instrument a while back and thought to myself “What an interesting instrument?”. While the social impact of this project isn’t as important or serious as the previous one, I can see people using this project to get a feel or understand of the instrument. The theremin differs from traditional instruments in that it is more approachable for children, or anyone for that matter. It is easy to create sounds with the theremin but it has a very steep learning curve. By allowing this kind of project to exist, people of any background can experience music and sound without buying the instrument.
Future Development:
For the first project, I can see the project developing into an add-on that works for every WebVR project. For this to be real, one has to have an extensive understanding of the framework A-Frame. By understanding the framework, one can possibly use it to develop the necessary tools for the external machine learning program to be integrated. The machine learning algorithm also needs to be more accurate in order to allow as many functions to be used as possible.
For the second project, I can see music classes using this project to explain the concept of frequencies and velocities to younger children or those with beginner knowledge in music production. It allows a visual and interactive experience for these people. For the future, it can be possible to add the velocity and volume of each point on the x and y-axis to make the sounds more quantifiable for the person who is using it. The types of sounds that can be played can also be placed on the sidebar for the user to pick and choose.
The direction of my project changed from the original concept I had in mind. Originally I wanted to do a project juxtaposing the lifespans of the user (human) and surrounding objects. Upon going through the ImageNet labels though, I realized that there was nothing to describe humans, and that the model had not been trained with human images. There were a few human-related labels (scuba diver, bridegroom/groom, baseball player/ball player, nipple, harvester/reaper), but these rarely show up through the ml5.js Image Classification, even if provided a human image. Because of this, it would be impossible to proceed with my original idea without drastically restructuring my plan.
I had seen another project called I Will Not Forget (https://aitold.me/portfolio/i-will-not-forget/) that shows first a neural network’s imagining a person, then what happens when neurons are turned off one by one. I’m not sure exactly how this works, but I like the idea of utilizing what is already happening in the neural network to make an art piece, not manipulating it too heavily. In combination with my ImageNet issue, this started to make me wonder what a machine (specifically through ImageNet and ml5.js models) thinks a human is then. If it could deconstruct and reconstruct a human body, how would it do it? What would that look like? For my new project, which I would like to continue to work on for my final as well, I want to images of humans based on how different body parts are classified with ImageNet.
New Steps
Use BodyPix with Image Classifier live to isolate the entire body from the background, classify (done)
Use BodyPix live to segment human body into different parts (done)
Use BodyPix with Image Classifier live to then isolate those segmented parts, classify (in progress)
Conduct testing, collect this from more people to get a larger pool of classified data for each body part. (to do)
Use this data to create images of reconstructed “humans” (still vague, still looking into methods of doing this) (to do)
Research
I first was trying to mess around to figure out how to get a more certain idea of what I as a human was being classified as.
Here I use my phone as well to show that the regular webcam/live feed image classifier is unfocused and uncertain. Not only was it recognizing images in the entire frame, but also its certainty was relatively low (19% or 24%).
In the ml5.js reference page I found BodyPix and decided to try that to isolate the human body from the image.
This worked to not only isolate the body, but also more than doubled the certainty. To be able to get more certain classifications for these body parts, I think it would be necessary to at least separate from the background.
With BodyPix, you can also segment the body into 24 parts. This also works with live feed, though there’s a bit of a lag.
Again, in order to get readings for specific parts while simultaneously cutting out background noise, BodyPix part segmentation would need to be used. The next step for this would be to be able to only show one or two segments of the body at a time while blacking out the rest of the frame. This leads into my difficulties.
Difficulties
I’ve been stuck on the same problem/trying to figure out the code in different ways for a few days now. I was getting some help from Tristan last week to try to figure it out, and since we have differing knowledges (he understands it at a lower level than I do) it was very helpful. It was still this issue of isolating one or two parts and blacking out the rest that we couldn’t fully figure out though. For now we know that the image is broken down into an array of pixels, which are assigned numbers that correlate to the specific body part (0-23):
Conclusion
I have a lot more work to do on this project, but I like this idea and am excited to see the results that come from it. I don’t have concrete expectations for what it will look like, but I think it will ultimately depend on what I use to create the final constructed images.
I changed the topic of my project from the ancient Chinese characters to the Hanafuda cards. There are a couple reasons why I changed the subject: first, I found that the idea I proposed before is more based on computer vision rather than artificial intelligence (it does not necessarily need deep learning to identify the resemblance between an image input and a certain Chinese character); second, I wanted to actually trainmy algorithm instead of utilizing the pre-trained models.
Hanafuda cards, or Hwatu in Korean, are playing cards of Japanese origin that are commonly played in South Korea, Japan, and Hawaii. In a single set, there are twelve suits, representing months. Each is designated by a flower, and each suit has four cards—48 cards in total. Hanafuda can be viewed as an equivalent of poker cards in Western, or mahjong in China as they are mostly used for gambles.
I got the inspiration from Siraj Raval’s “Generating Pokémon with a Generative Adversarial Network,” which trains its algorithm with the images of 150 original Pokémons and generates new Pokémon-ish images based on the data-set by using WGAN. I replaced the dataset with the images of hanafuda cards I found on the web, and modified the code to work accordingly with the newly updated data-set.
Methodology
Collecting the proper image set was the first thing I did. I scraped 192 images in total, including a scanned set of nineteenth century hanafuda cards from the digital library of the Bibliothèque Nationale de France, a set of modern hanafuda cards from a Japanese board game community, vector images of modern Korean hwatu cards from the Urban Brush, and a set of Hawaiian-style Hanafuda cards. I had to manually gather those images and trim out their borders, which may affect the result of generated images.
Although they have slightly different styles, they share same themes, symbols and compositions—as we can see from the image above, there are distinct hanafuda characteristics: including elements of the nature, Japanese style of painting, simple color scheme, and so on. I hope artificial intelligence can detect such features and generate new, interesting hanafuda cards that have not existed so far.
The code is comprised of three parts: Resize, RGBA to RGB, and the main GAN. First, as it is necessary to make the size of all image sources same, “Resize” automatically scales the images to the same size (256*404). Second, “RGBA2RGB” converts the RGBA images to RGB, namely from PNG to JPG. The first two steps are to standardize the images so they can be fed to the algorithm, the main GAN.
The GAN part has two key functions: Discriminator and Generator. The Discriminator function of this GAN keeps trying to distinguish real data from the images created by the Generator function. It has four layers in total, and each layer performs convolution, activation (relu), and bias. At the end of the Discriminator part, we use Sigmoid function to tell whether the image is real or fake. The Generator function has six layers that repeat convolution, bias, and activation. After going through the six layers, the generator will use tanh function to squash the output and return a generated image. It is remarkable that this Generator begins by randomly generating images regardless of the training data-set. And as training goes on, the random inputs will morph into something looks like hanafuda cards due to the optimization scheme, which is back-propagation.
Experiments
As I’m using a Windows laptop, there are some difficulties in terms of work submission to Intel DevCloud. After I figure out how to install needed dependencies(cv2, scipy, numpy, pillar) on the Intel environment, I’ll train the algorithm and see how I might improve the results. Here are a number of potential issues and rooms for improvement:
Above is a set of images generated by Pokémon GAN. Here we can clearly see some Pokémon-like features; and yet, they are still somewhat abstract. Aven pointed out that the result of my hanafuda cards are very likely to be as abstract as those Pokémons are. I need to do more research on how to make my potential results less abstract, or I may select a few interesting outputs and retouch them a little bit.
Since the data-set is comprised of cards of the three different countries, I’m so excited to see what will come out of this project. I’d like to find some “pairable” cards that share similar characteristics, so I can possibly group them as 13th or 14th month.
My Ideal Cup of Coffee (too bad I don’t drink coffee and this project consumed most of my nights the past two weeks…)
Build a project that takes audio input and matches that audio input to the closest equivalent quotation from a movie, yielding the video clip as output.
Original Plan: Use WordtoVec to complete this with SoundClassification.
Completed Tasks:
Acquired the entire film
Acquired the subtitles
Realized Word2Vec didn’t work
Found an example of something that COULD work (if I can get the API to actually work for me too)
Started playing with Sound Classification
Spliced the entire movie by sentences… (ready for output!)
Discoveries:
WordtoVec doesn’t work with phrases. The sole functionality is mapping individual words to other words. And even then, it does such a horrific job that barely as of the movie plot is distinguishable by searching these related terms. Half the associated words just are not usable after training the model on the script from Detective Pikachu.
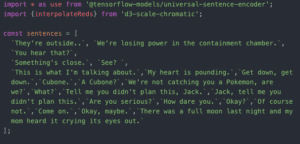
I’ll talk through the examples and how I was able to train the model on the subtitle script.
How To Guide on GitHub
In order to train the model, I had to get the script into a usable format, because straight up the first time I did it, I left all the time stamps and line numbers in the subtitle document, so when it trained, the entire response list was just numbers that didn’t actually correlate to the words I typed into the sample in a meaningful way.
TEST 1: SUBTITLES INTO TRAINER WITH TIME STAMPS + LINE NUMBERS
Results:
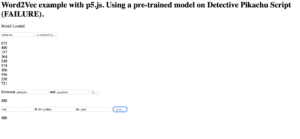
Pure Failure on My PartThis is what not removing numbers looks like…
I took the numbers that were outputted and compared it to the subtitles… then, since the subtitles don’t clarify which character said what, I went into the movie… which honestly… yielded mixed results. Leading me to conclude that there was no actual meaningful correlation between this output and the script itself.
Line 480 Actual Pikachu!Line 675 Actual Pikachu!Line 157 Pikachu is mentioned in this scene, but doesn’t say anything and isn’t present.Line 364 Pikachu is in the SceneLine 248 We as an audience don’t know that’s Pikachu yet… this blob shape could be any intruder… as Pikachu isn’t speakingLine 574 Once again no Mention of Pikachu or direct connection to the characterLine 306 Pikachu escaping evil PokemonLine 556 Evil Guy in Film, No Direct Correlation to PikachuLine 721 … Pikachu is technically Interrogating so this is semi related, but the scene makes it unclear who is asking the questionsLine 530 That’s Pikachu on the Screen!! That’s definitely related…
Conclusion:
I love when things don’t work the way I want them to
So is this data usable? Not really… it’s usually connecting words that yield that high correlation… so I decided to go back to the drawing board with testing. Which is really unfortunate considering how long this initial test took start to finish.
TEST 2: SUBTITLES INTO TRAINER WITHOUT TIME STAMPS + LINE NUMBERS
Results:
I went back and edited out all the time stamps and line numbers… and the results were still mixed in terms of giving me relevant words.
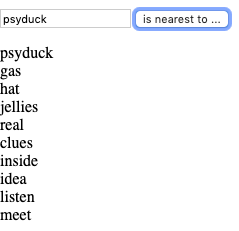
Testing Word 2 VecHORRIBLE RESULT FOR PIKACHUStuff is not DESCRIPTIVE OR SPECIFIC ENOUGHIS ??? definitely not enoughClues has SOME Correlation .. though it’s not really a clear indicator of plot for those not familiar with the filmMinor Correlation Considering PlotBad Cross Comparison ResultAbout Half the Results are MeaningfulPoor OutputBad Comparison
Is this usable information? Not even remotely. Most of the outputs are poor and it is next to impossible to draw any sort of meaningful connection that is not just a plain connector word. My conclusion here was that Word2Vec was not the best option for my project. It simply couldn’t even get meaningful word connections… and it did not possess the capability to analyze sentences as sentences.
Conclusion:
This was me… waiting to have permission to move on from Word2Vec.
I asked Aven if I could quit Word2Vec… he said as long as I documented all my failures and tests… it would be fine… so that’s exactly what I did before starting completely over again! It was… needless to say incredibly frustrating to realize this very easily trainable model didn’t work for my project.
TEST 3: SENTENCE ANALYZER
Inputting the entire scriptTHIS DOESN’T WORK!
So… this is was probably the saddest test I have seen. Seeing as I had nothing to work with… I went back to Medium to see if I could gain some sort of new insights into ml5… I stumbled upon this article about an ITP student’s project and thought I could go about my project in a similar way. He also references Word2Vec… but then explains that there is this other TensorFlow model that works for paragraphs and sentences! That’s exactly what I need! But as you can tell from above… it didn’t work out for me… after I had finally inputted the entire script. Hindsight is 20/20, I probably should have tested the base code BEFORE I inputted and retyped the script… it’s fine you know, you live and you learn.
This is the link to the GitHub Repo which is supposed to guide you just as the link from the ml5 website to the Word2Vec example, unfortunately there seems to be an issue even in their code, even after I downloaded everything necessary to run it (supposedly).
Conclusion:
This was a harder failure to swallow
Well… sometimes Holy Grail answers are too good to be true. I still haven’t given up on this one… I think maybe with enough work and office hours I can get the issue sorted, but this is definitely a potential solution to my issue… especially considering the ITP project, I definitely think this is the right way to go.
TEST 4: SOUND CLASSIFIER
This was one of the parts of my project, meant to be sort of a last step, making it the sole interaction. This is really something I only plan on implementing if I get the rest of the project functional! But I thought since I was experimenting as much as I was, it was time to explore this other element as well.
So what did I do?
Experimenting with the 18 word set 1/3Experimenting with the 18 word set 2/3Experimenting with the 18 word set 3/3
This is nice. I think however, it’s incredibly difficult to get it trained based on your voice, considering HOW MANY LINES ARE IN A SINGLE FILM… it seems rather inefficient to do this. So I was thinking… is there a better method… or a method to help me train this Sound Classifier. And… I think I found something useful.
ADVANTAGESPROCESS
Conclusion:
Solutions!
I am not a computer science student… I don’t think I have the capabilities to build something from scratch… so I have really looked into this. And, should the main functionality of my project work with the Sentence Encoder… this could work to make the interaction smoother.
Progress Report:
I know what I need to use, it’s now just a matter of learning how to use things that are beyond the scope of the class. Or at the very least, beyond my current capabilities. This is a good start and I hope to have a better actually working project for the final. For now the experimentation has led to a clearer path.
Social Impact + Further Development:
In the case of this project, I see it developing into a sort of piece that serves as a social commentary on what we remember, what we really enjoy about media. I think there are so many different ways in which we consume media. We, as consumers all understand and really value different elements, characters, etc out of movies. There is something to be said about our favorite characters and lines, and why we remember them. Is your favorite character your favorite because it reminds you of someone you care about? Do you hate another character and not like their quotes because they play up on stereotypes you don’t believe in?
There is much to be said about who we like and why we like them. For the sake of my midterm, I think it’s best to say this project needs to go. I think in terms of developing on this social impact piece further, I want to maybe look at the psychological aspect of advertising. Are good movies foreshadowed by certain colorings and text? Is there basically an algorithm or recipe to pick out a good movie versus a mad movie? Are we as consumers based against low budget or movies created/acted in by minority actors?
I see that as the direction in which I can make this “Fun” gif generator a more serious work.