Link to final presentation slides: https://drive.google.com/file/d/1vmSHhVKNERSHDP3kohUbkKPy6XJEMXsV/view?usp=sharing
Link to final project posters: https://drive.google.com/file/d/15ZaGm7wcuEwJYs4QItOdXVyZF-wcR_OH/view
Link to final project video: https://www.youtube.com/watch?v=dNwHWeazyxk
Link to concept presentation slides: https://drive.google.com/file/d/1jgxeo-knGx7nLrnWBmPZYLOIwz4mdJ8k/view?usp=sharing
Background
For my final project, I’ll be exploring abstract art with Deepdream in two different mediums, video and print. I plan on creating a series of images (printed HD onto posters to allow viewers to focus on the detail) and a zooming Deepdream video. I’ll create the original images with digital tools, creating abstract designs, and then push them one step (or several) further into the abstract with the Deepdream algorithm.
I love creating digital art with tools such as Photoshop, Illustrator, Data moshing and code such as P5, however I’ve realized that there are limitations to these tools in terms of how abstract and deconstructed an image can get. I’ve also been interested in Deepdream styles for a while and the artistic possibilities, and I love the infinite ways Deepdream can transform images and video. In the first week, I presented Deepdream as my case study, using different styles of the Deep Dream generator tool to transform my photos.
Case study slides: https://drive.google.com/file/d/1hXeGpJuCXjlElFr1kn5yZVW63Qcd8V5x/view
I would love to take this exploration to the next level by combining my interest in abstract, digital art with the tools we’ve learned in this course.
Motivation
I’m very interested in playing with the amount of control digital tools give me to create, with Photoshop and Illustrator giving me the most control over the output of the image, coding allowing me to randomize certain aspects and generate new designs on its own, and data moshing simply taking in certain controls to “destroy” files on its own, generating glitchy images.
However, Deepdream takes away all most of this prediction and control, and while you are able to set certain guidelines, such as “layer” or style, octaves, or the number of times Deepdream goes over the image, iterations and strength, it is impossible to predict what the algorithm will “see” and produce in the image, creating completely unexpected results that would be nearly impossible to achieve in digital editing tools.
References
I’m very inspired by this Deepdream exploration by artist Memo Akten, capturing the eeriness and infinity of Deepdream: https://vimeo.com/132462576
His article (https://medium.com/@memoakten/deepdream-is-blowing-my-mind-6a2c8669c698) explains in depth his fascination with Deepdream, something I share. As Akten writes, while the psychedelic aesthetic itself is mesmerizing, “the poetry behind the scenes is blowing my mind.” Akten details the process of Deepdream, how the neural networks work to recognizevarious aspects of the reference image based on its previous training and confirm them by choosing a group of neurons and modifying “the input image such that it amplifies the activity in that neuron group” allowing it to “see” more of what it recognizes. Akten’s own interest comes from how we perceive these images, as we recognize more to these Deepdream images, seeing dogs, birds, swirls, etc., meaning viewers are doing the same thing as the neural network by reading deeper into these images. This allows us to work with the neural networks to recognize and confirm the images it has found, creating a cycle requiring both AI technology and human interference, to set the guidelines and direct it to amplify the neural network activity as well as perceive these modified images. Essentially, Deepdream is a collaboration between AI and humans interfering with the system to see deeper into images and produce something together.
Experiments
I started by playing around with different images I had already created in code and with Illustrator and Photoshop using Alex Mordvintsev’s Deepdream code to find the settings I wanted to use. While at first I went all out with the strength and iteration settings, I soon realized that the images became too obscured and I wanted the final result to be an abstraction of an existing image, not a completely indiscernible abstraction.
Here’s an image created with the 5a layer on high strength with many iterations:

After researching what each setting related to and refining my process, I settled on my favorite settings in Deepdream, such as these settings that I used for the video:
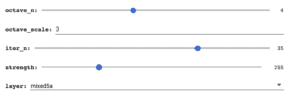
Then I created my own images for the posters and video, using what I learned from my experiments. I realized that images with a lot of white space often had less interesting results and use of color, such as this image of circles created with P5:

And these results, which didn’t achieve the style I was going for:

Therefore, I focused on creating images with a full canvas of color and/or detail to get the most interesting abstract results. I settled on these 5 images to create the Deepdream posters.
This image of “Juju’s” created in p5 which presented an interesting pattern and enough detail across the canvas for Deepdream abstraction:
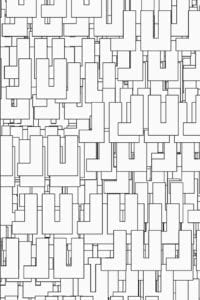
Here is after 5a level iteration:

After editing the image to turn it black and white for the final result:

I really liked this result because the black and white filter applied in Photoshop combined with Deepdream added texture and depth, even though the original image was 2D.
The next image I created was this one, beginning from a photograph and using Illustrator. Using the trace image and merge functions, I separated details of one photograph into the top and bottom of the canvas, applying shapes and letters to add detail.

Using the layer 3b I achieved this result:

I like this one because the abstraction still preserves the “dual reality” I created in the first image in Illustrator, adding fascinating detail and depth.
For the next one, I started with this photo of my old laptop’s lid with stickers on it:

I then used Photoshop to distort the image:

In Illustrator I traced, expanded, ungrouped and moved around various parts to abstract it further:

Then, using the 3b layer in Deepdream, I created this image, with some connection to reality but only if the previous progressions are viewed together:

For this image, I took a photo of a pattern on my pants and used Photoshop to edit the colors and distort the “pattern”:

I then used layer 3a to create this stunning image with new colors and seemingly infinite detail:

Finally, I created this image in p5 using beginShape and Perlin noise to randomize the drawing of the shapes and the colors:

Using layer 3a with a lower strength to highlight the rectangle lines in the original, I created this final image:

A link to all my final images is at the top of this post. To create the posters in A3, I formatted the images in Illustrator, adding quotes to highlight my view of my relationship with Deepdream and creation throughout the process. While I originally viewed this project as giving up control to Deepdream to abstract images further, I ended up regaining that control through editing photos and adjusting Deepdream settings to achieve the level of abstraction I wanted. This made me view the process more as a collaboration, using Deepdream for my specific artistic purposes instead of giving it control over my images.
Social Impact
I think exploring Deepdream is a great case study in the societal impact of AI technology, especially when thinking about Deepdream’s original uses and its artistic applications. Developed originally to enhance Google image’s perception of the content of images, developers realized the potential to create their own psychedelic imagery by increasing the strength, iterations and octaves and pulling images from different layers of neural network to reveal the algorithm’s process of enhancing and “seeing deeper” inside of given images. As AI is developed for practical uses of enhancing companies’ performances and governments’ efficiency, I foresee artists continuing to explore the artistic applications of various AI developments by tweaking the software for their own uses. This shows that as capitalism monetizes technological functions, humans will continue to see the beauty and aesthetics of these functions. Deepdream alone has much more potential in artistic applications as artists continue to explore its uses.
Further Development
One way I plan to develop this project further is through VJing with Deepdream videos. After creating my zooming Deepdream video set to music, I realized that it had great potential to be used as a video DJing tool accompanying techno music. I also received this feedback from friends I showed the video to who thought the pairing with music added a new element to the music. This winter I plan on throwing some parties with my friends who are DJs, and I’m planning on exploring how to import Deepdream style videos into VJing software to allow manipulation of the videos in real time with music. I liked using video editing techniques and manipulating the speed, colors (such as inverting the colors in time with the rhythm) and zoom to accompany the music and I see a lot more potential in this area.
I also plan on continuing my Deepdream poster series as a personal project since I love the results and I have many more images I’ve created with code and digital editing tools I would love to explore more. I plan on creating a new page on my portfolio website showcasing my AI art and potentially collaborating with other artists to use Deepdream in further projects.



































 The resolution of this
The resolution of this