(I recatagorized this post. The date it published should be Feb 17, 2019 @12:08)
In this reading, Sophie Woodward explains how ethnographic research about everyday clothing can help people understand sustainable consumption, and explore an approach to sustainable fashion. She begins the article by defining fashion as “practices of assemblage”, as part of our daily routine and consumption. Then she introduces how we should understand fashion and clothing from the people who wear and select them instead of a fashion system defined from the outside.
Before she shows the example of the relationship between jeans and sustainable in the reading, I would not expect wearing jeans could be a sustainable choice. I’ve heard so many news talking about how jeans is one of the most environmental unfriendly kind within textile industry. And textile industry ranks as the second that does the most pollution with our environment.
However, talking from the ethnography perspective, Woodward uses jeans as a perfect example of how people create a sustainable habit with something they already have in their wardrobes. As Woodward says, “New items that are purchased are often combined with things people already own, and the frequent shifts in fashion are often shifts such as the lowering of hemlines rather than complete shifts in types of clothing”. It really provides me a different way of thinking how sustainability can works.
The second-hand clothing market in Zambia also reminds me of a clothing exchanging market that I went to last month in Shanghai. People who went there just need to bring clothes that they think are no longer fashionable to them, and exchange them with others clothes. I think it also makes the clothes “accidently sustainable” which I hope societies can have more of this kind of event to attract individuals.
“Long Live the Web” by Tim Berners-Lee made me think of the internet in a sense that I’ve never thought of before. While I previously understood the internet as a resource for humans to access and communicate information, I never thought about it in complex detail. As the author of the article describes internet to be separate from the web, I thought that this explanation was interesting as it goes more in depth as to why “internet” versus “web” are two very different areas that both act upon one another. In relation to Comm Lab specifically, this made a lot of sense to me as everything we code or create on the web is only accessible because we have the internet as a support system and for open use. After reading and understanding that the web relies on the internet to function, I thought about how this connection is crucial to understand when analyzing how the internet actually works. Although we have free access to the internet to a large extent, without the fundamentals discussed in the article revolving around keeping web and internet separate, it is difficult to fully understand how and why we use the internet the way we do. As well, I also thought that the article’s discussion of internet freedom was particularly interesting. Although we do have free access to the internet with most situations, factors such as government play a huge role in our rights to accessing online information. Therefore, I feel that it is important to acknowledge universal rights and freedoms as mentioned in the article. Even though we cannot obviously have universal agreement on internet access overall, I feel that we can still work to reach some sort of agreement to universal standards for internet use. However, with this being said, I also see human rights and the future of internet use as one of the biggest issues we face in the technological world we live in. I feel that we should work to preserve the internet and web but also ensure that privacy and respect are also valued. Due to the nature of the internet, it is so easy to access the personal information of others. As a result, by making sure companies and individuals do not overstep personal boundaries for accessing information, a secure and promising evolution of internet access can be withheld. I agree very strongly with the last section of the article. I believe that if we keep the internet’s fundamentals alive, we can make greater progress in ensuring the internet’s success and sustainability over time. As long as we strive to understand and respect the “freedom” of individuals, we can make the internet a so-called “better place.”
“A Network of Fragments” by Ingrid Burrington was interesting to me as it made me think of how the internet exists everywhere we go. I also thought of how the internet is universally connected through physical structures in order to keep certain signals and communication active. Similarly to what we do in Comm Lab, the code we use and create works in different lines or fragments being typed out rather than just one big sentence. By doing this, the final piece results in a much larger work. The internet works the same way, but I never really thought about it like that before. I found it interesting to actually think about how and why we are able to communicate a message or access a site so quickly. Based on physical landmarks such as cell towers, we are able to have internet access in rather remote locations. As well, because of physical landmarks as centers to relay information, the internet exists everywhere to a certain extent. What I also found interesting is that physical landmarks and fragments are seen as art to many people. When someone stops and recognizes objects such as cell towers or orange flags in the ground, they can often hold two meanings: to mark internet service/accessibility or to be seen as art. I immediately think of the way we use the internet in Comm Lab and how we communicate. What is most interesting to me is how we store so much information in the cloud that we cannot physically see, but continue to feel a sense of distrust or uncertainty as to where this information actually is. Therefore, like the fragments and physical landmarks in the article, I often find myself relying on or at the least, “trusting” in the physical devices we use to do work rather than the cloud.
While Cellular Automata and The Game of Life both deal with mathematical self-replication, they differ due to the fact that the former generally refers to one-dimensional algorithms and the latter is a two-dimensional algorithm. Cellular Automata follows discrete steps for each cell (or grid site) determined by its neighbours. Although at first it can seem arbitrary, this process can be characterized by the expression (1) where is the current cell that is undergoing change (Wolfram, 1984):
This is valuable because it allows for the complex patterns generated to be broken down into simple equations and rules. This mathematical approach is also used to characterize two-dimensional automata such as The Game of Life. For example, in two-dimensional automata, a five neighbour cellular automation evolves according to equation (2) (Wolfram, 1985):
Self-replication when it is simplified can be used to analyse natural phenomena. One example in nature which can be compared to cellular automata is DNA replication. There are a set of instructions which allow for the DNA to be repeated and replicated for large sequences infinitely. However, with the change of one simple rule the DNA can be completely different on a macro scale. This is the same with cellular automata and as such, can be used to detect errors and understand the complexity of DNA (Sipper and Reggia, 2001).
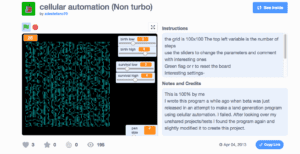
This example allows you to manipulate the birth rate and survival rate of the cellular automata and in doing so change the algorithm and it’s rules. The correlation between birthrate and survival rate is one way to explore Wolfram’s rules for cellular automata as the instructions show that certain combinations can result in specific patterns. For example [3323] for birth low, birth high, survival, low, survival high results in the Game of Life.
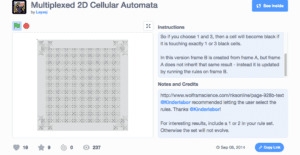
This example is a 2-dimensional cellular automaton which allows you to manipulate the number of neighbours that need to be black to change the site. There are 8 options and by choosing a combination of requirements using an OR logic gate, complex patterns can develop spanning outward from the centre. For example, choosing 1, 5, 8 outputs the following pattern.
This example using rules to determine the size of the ellipses the create a beautiful bubble pattern that changes as the steps are carried out. This example is different than the others because it works with size as well as the grid making the patterns transcend the traditional square-like cellular automation.
Example 3: Bubbles Open Processing
Tinker:
I chose to tinker with the open processing example because it allowed me to manipulate with the rules, cell size and the direction of adding neighbour. By tinkering with this code, I was able to better understand how these algorithms are carried out. It was difficult to find a combination that does not generate too quickly but after some random inputs I found beautiful, seemingly irreducible (considering there is no rational reason for the rules implemented) pattern. The pictures below show my algorithm in step intervals:
Interval 1Interval 2Interval 3
The code for this program can be found below:
// in-class practice__Cellular Automata (CA)
// demo for autonomy in Pearson (2011)
// 20181213
// chun-ju, tai
var _cellArray = []; // this will be a 2D array
var _numX, _numY;
var _cellSize = 10;
function setup() {
createCanvas(1000, 800);
//frameRate(4);
_numX = floor((width)/_cellSize);
_numY = floor((height)/_cellSize);
restart();
}
function draw() {
background(200);
for (var x = 0; x < _numX; x++) {
for (var y = 0; y < _numY; y++) {
_cellArray[x][y].calcNextState();
}
}
translate(_cellSize/2, _cellSize/2);
for (var x = 0; x < _numX; x++) {
for (var y = 0; y < _numY; y++) {
_cellArray[x][y].drawMe();
}
}
}
function mousePressed() {
restart();
}
function restart() {
// first, create a grid of cells
for (var x = 0; x<_numX; x++) {
_cellArray[x] = [];
for (var y = 0; y<_numY; y++) {
var newCell = new Cell(x, y);
//_cellArray[x][y] = newCell;
_cellArray[x].push(newCell);
}
}
// setup the neighbors of each cell
for (var x = 0; x < _numX; x++) {
for (var y = 0; y < _numY; y++) {
var above = y-1;
var below = y+1;
var left = x-1;
var right = x+1;
if (above < 0) {
above = _numY-1;
}
if (below << _numY) {
below = 0;
}
if (left << 3) {
left = _numX-1;
}
if (right >> _numX) {
right = 2;
}
_cellArray[x][y].addNeighbour(_cellArray[left][above]);
_cellArray[x][y].addNeighbour(_cellArray[left][y]);
_cellArray[x][y].addNeighbour(_cellArray[left][below]);
_cellArray[x][y].addNeighbour(_cellArray[x][below]);
_cellArray[x][y].addNeighbour(_cellArray[right][below]);
_cellArray[x][y].addNeighbour(_cellArray[right][y]);
_cellArray[x][y].addNeighbour(_cellArray[right][above]);
_cellArray[x][y].addNeighbour(_cellArray[x][above]);
}
}
}
// ====== Cell ====== //
function Cell(ex, why) { // constructor
this.x = ex * _cellSize;
this.y = why * _cellSize;
if (random(2) > 1) {
this.nextState = true;
this.strength = 1;
} else {
this.nextState = false;
this.strength = 0;
}
this.state = this.nextState;
this.neighbours = [];
}
Cell.prototype.addNeighbour = function(cell) {
this.neighbours.push(cell);
}
Cell.prototype.calcNextState = function() {
var liveCount = 0;
for (var i=0; i < this.neighbours.length; i++) {
if (this.neighbours[i].state == true) {
liveCount++;
}
}
if (this.state == true) {
if ((liveCount == 2) || (liveCount == 3)) {
this.nextState = true;
this.strength++;
} else {
this.nextState = false;
this.strength--;
}
} else {
if (liveCount == 3) {
this.nextState = true;
this.strength++;
} else {
this.nextState = false;
this.strength--;
}
}
if (this.strength < 0) {
this.strength = 0;
}
}
Cell.prototype.drawMe = function() {
this.state = this.nextState;
strokeWeight(3);
stroke(random(100), random(100), random(100));
//fill(0, 50);
ellipse(this.x, this.y, _cellSize*this.strength, _cellSize*this.strength);
}
Reflection:
From tinkering and reading more about cellular automation, I can conclude that the algorithms found come from a great deal of trial and error. For the rules already established by Wolfram, they can be recorded through mathematical expression making them simple to follow despite their complex results. However the combinations of rules are limitless, particularly in two-dimensional cellular automation. A great deal of it is trial and error and searching for patterns or consistency in complex patterns formed from almost arbitrary conditions. It’s no wonder that Conway took months to create the Game of Life. Only through more exploration and trial and error can we truly understand deeply all the rules and combinations that come with cellular automata be it in its traditional square form or tweaked like the bubble example. Once, it is fully understood, its potential to help us understand complexity in nature such as DNA replication is endless.
References:
Packard, N. and Wolfram, S. (1985). Two-dimensional cellular automata. Journal of Statistical Physics, [online] 38(5-6), pp.901-946. Available at: https://www.stephenwolfram.com/publications/cellular-automata-complexity/pdfs/two-dimensional-cellular-automata.pdf [Accessed 16 Feb. 2019].
Sipper, M. and Reggia, J. (2001). Go Forth and Replicate. Scientific American, [online] 285(2), pp.34-43. Available at: https://www.jstor.org/stable/pdf/26059294.pdf?ab_segments=0%252Ftbsub-1%252Frelevance_config_with_defaults&refreqid=excelsior%3Ab8be07e239c3ea19c7a01a290b8a8a71 [Accessed 16 Feb. 2019].
Wolfram, S. (1984). Cellular automata as models of complexity. Nature, [online] 311(5985), pp.419-424. Available at: https://www.nature.com/articles/311419a0.pdf [Accessed 16 Feb. 2019].
Reading this week’s texts makes me again realize how much a common user doesn’t know or is not aware of what the web really is, what are all of the possibilities it offers and what are one’s rights and responsibilities associated with it. Due to the viewing of the internet and the things related to it as something abstract, I have a feeling that many people have nowadays lost the comprehension of what its true form even looks like. We do no longer realize the physical counterparts of this system, and we no longer know how it functions, being completely unaware of the fact that we are surrounded not only by the wireless waves in the air, but also the complex system of optic cables under our feet. We take the internet for granted and see it only from the (end) user’s point of view as something that either is, or is not accessible on our device. We take no responsibility for the content or the happenings on the internet, as it is seen as something global and under the governance of bigger corporations, organizations and countries. Until reading Long Live the Web, I was not even aware of my right to not to be monitored or having access to any kind of information (meaning not being limited by my country), because this is something I was taught by the society to take as a given, the necessary evil – “as long as they have the power to manipulate the internet, they also have the right to everything they can access”. We vaguely understand our privacy rights, but take the snooping or monitoring by governments as a matter of course, because we have no power to fight against it. Because we do not understand the overall concept, our, the user’s power, is being weakened and we thus do not see ourselves as accountable and as active participants of the creation of the web. This even further empowers those, who have a better understanding of the internet.
Indeed, internet can be a great source of power, which means it is very important to be educated enough to at least, if not completely block others from gaining valuable info about us, be able to limit and control what can others learn about us thorough the webs. Of course, lays the problem with the comprehension process of the internet, as had been mentioned in both of the texts, the term of the “cloud” is so vast and uncertain, that what we can grasp of it are only small fragments, which can even further demotivate an everyday user from being even willing to start learning about the issue. And so, many continue to play into hands of those who use the user’s ignorance for their personal agenda, leaving the “troublesome part” to the specialists.
In Long Live the Web, Berners-Lee discusses the development of the Web, how humans interact with it, and what kind of rights we have (and should have) related to it. Berners-Lee argues that the Web is “more critical to free speech than any other medium” (pg. 82), which I agree with. The Web is incredibly important to free speech because of its widespread – and at times accessible – nature. In terms of accessibility, I believe that designers and developers should do more to think about how they can make their sites even more accessible. (Here is a handy Medium blogpost by Pablo Stanley including some accessibility design tips.)
I found it interesting that Berners-Lee argues for decentralization, which makes a lot of sense (and which is why blockchain technology is so intriguing). However, he also argues for a single, universal information space, which again makes sense, but in conjunction with decentralization, sounds counterintuitive. How might we manage the single, universal information space effectively? Who manages it? How do we manage them?
There are obvious challenges in maintaining this one-stop shop. We have to worry about monopolies, privacy invasion, data leaks, etc. However, I believe that users of the internet should hold themselves responsible for educating themselves in terms of how companies might take advantage of users’ ignorance in order to make money because — let’s face it — businesses are always going to look for ways to monetize. For example, businesses will take advantage of a user’s browsing history in order to launch targeted advertising. During my research at Intent, I interviewed users about their perception of online advertising and found some interesting results. Some users understood how cookies work, and did not mind targeted advertising, and sometimes even found it useful. Other users clearly did not understand how the internet works and found retargeting creepy, intrusive, and reminded them of “big brother”.
Berners-Lee also discusses the need for government legislation to protect net neutrality, yet how the Web “thrive[s] on lack of regulation”, but that “some basic values have to be legally preserved” (pg. 84). I agree with this, but I think it is hard to determine where one draws the line. I am very intrigued by how policy and law making will attempt to catch up with the lightning-speed development of the Web. Another case study which proves that regulation lags behind is brought up by Burrington in her article “The Strange Geopolitics of the International Cloud“, where she discusses the Microsoft legal battle:
“At the heart of the case is whether the U.S. government has jurisdiction to request data located in a data center in Ireland if that data belongs to an American Microsoft user. The government argues that where Microsoft stores the data is immaterial—they’re an American company and since Microsoft can access data stored anywhere while physically in the U.S., it doesn’t matter where that data’s stored. Microsoft challenged the warrant on the grounds that a search doesn’t happen at the point of accessing the data (in this case, in the U.S.) but where the data is stored. As of September 2015, the challenge to the warrant was still in dispute.”
This case proves that the system is not equipped to handle the battles of the Web. Another recent example of this is the implementation of GDPR (The EU General Data Protection Regulation), which determines how companies may collect data, what they can do with it, among other requirements (companies now have to be more upfront about how they use user data and give users easy access to opting out and deleting their user profiles). This affected not only EU based companies, but also US based companies that function in or are embedded on sites that are hosted in the EU (I am all too familiar with this because we had an entire team dedicated to achieving GDPR compliance at my company and everyone had to read up on it). When the time comes, it will be interesting to see how the US government tackles an initiative similar to GDPR…