As I was coming up with the project idea, I wanted to make something that I could continuously build on even past the midterm, and stay true to ‘machine learning’ as a core part of the project. I recalled one of the videos we watched early on in the semester where a man spoke a made-up language and they would generate subtitles animated according to his speech pattern. Unfortunately I could not locate the video but this inspired my idea of matching gestures to the English alphabet. After starting the project I quickly realized that this would be hard to accomplish, due to the physical limitations of the body to create shapes that resemble letters. I would have preferred to use leap motion or the kinect to trace the fingers, which would offer more flexibility in terms of representing the characters but I figured it might have been a better idea to stick with poseNet as I hadn’t worked with either leap motion nor kinect for over a year.
The full arc of my project was to include tracing of the arms, saving it as an image, comparing the image to a library of the English characters, and then detecting which one of the letters most closely matched the gesture. This would become a basis for visuals similar to the aforementioned video that inspired me. The letter would appear and would be animated according to either sound or movement, however, in the end I did not manage to add this section.
For image comparison I found a library called resemble.js.
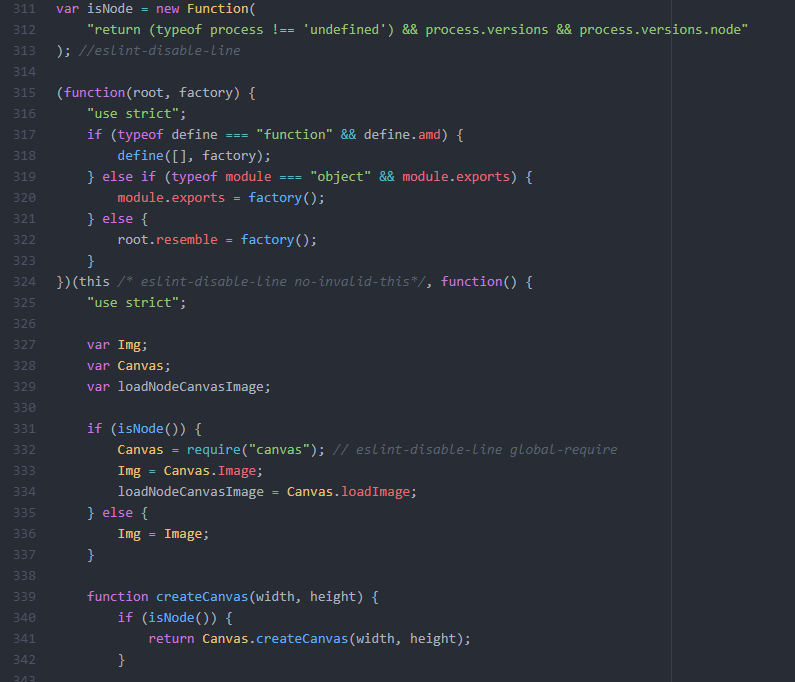
Unfortunately, I ran into quite a few problems while using this. They only had one demo that incorporated jQuery, so I needed to take a decent amount of time distinguishing the syntax of jQuery from the library. I also had problem referencing the library as an external script, so I ended up directly copy and pasting it into the main sketch.js which ended up working out.
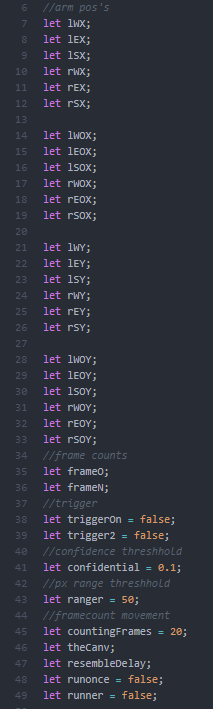
I wanted to create some specific parameters for controlling when and how p5/poseNet detected the arms and dictated when it was time to save the canvas for comparison. Knowing that poseNet has a tendency to ‘stutter,’ I wanted to make sure that it only ran when specifically triggered, and ended with another trigger. I used the confidence markers that poseNet offers in order to dictate this, only starting when all the wrist, elbow, and shoulder points stayed relatively stable with a high confidence level for a certain amount of frames( utilizing two sets of variables tracking the last frame’s positions and the current frame’s),
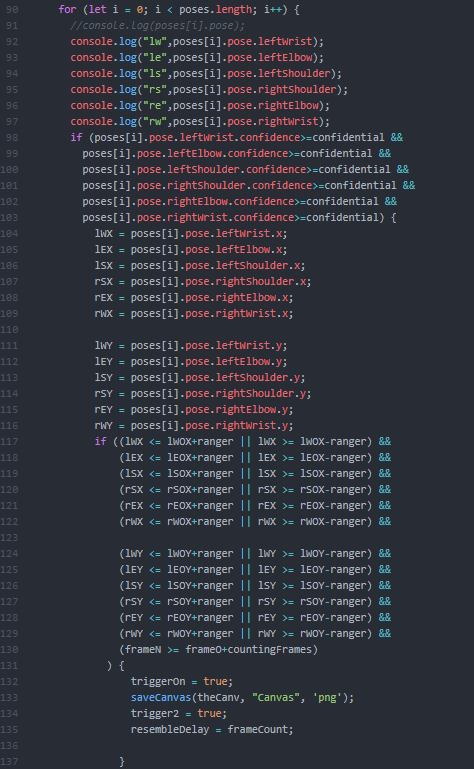
or resetting when the confidence level of the hands dropped below a certain point (signifying the hands dropping out of frame). Due to the unreliability of the confidence levels fed by poseNet, I had to keep the threshold very low (0.1 out of 1) just so that it could track the arms more reliably, at the cost of this “off” trigger, so I decided to remove it until I could find a better way to trigger the reset.
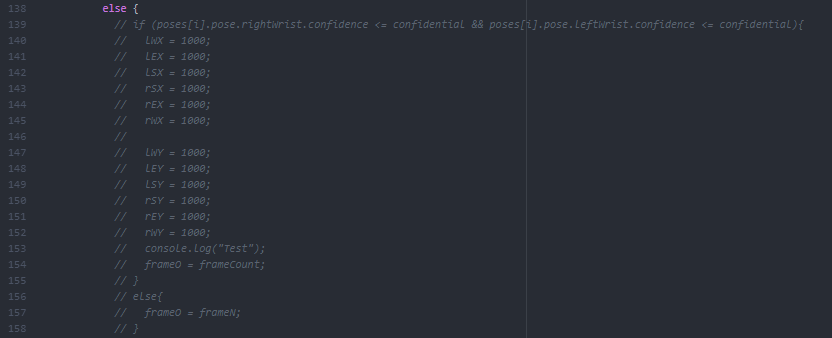
At this point I realized that I could not count on poseNet tracking reliably enough to distinguish a whole set of 26 different characters from each other, especially with the limitations of how we can move our arms. Instead, I replaced this library with 3 basic images that were generally achievable through poseNet.

Knowing PNGs automatically resize depending on the amount of empty space, I made sure to keep everything as that file type, so that no matter what part of the canvas your body took up with poseNet, it’ll automatically center crop out the sides so that the image sizes can match better.
Ex.
The peak of my hardship came after I managed to figure out the individual steps of the project and began to integrate them with each other. While P5 has the ability to save the canvas, I needed it to be able to replace an existing image with the same name. I came to realize that this was only possible using a html5 canvas, while p5 would just keep saving with a sequence number after (eg. CanvasImg(1).png). I had largely forgotten how to utilize the workflow between html and javascript, so I decided to keep using P5 out of time constraints, but this would mean that I would need to manually delete the saved Canvas image each time I wanted to make a new comparison. Another problem was that in order to register the saved images, atom live server had to reload, which would restart the pose detection. Luckily, loadImage() has a two extra parameters, a success callback function, and a fail callback function. I turned the two segments of the project into functions,
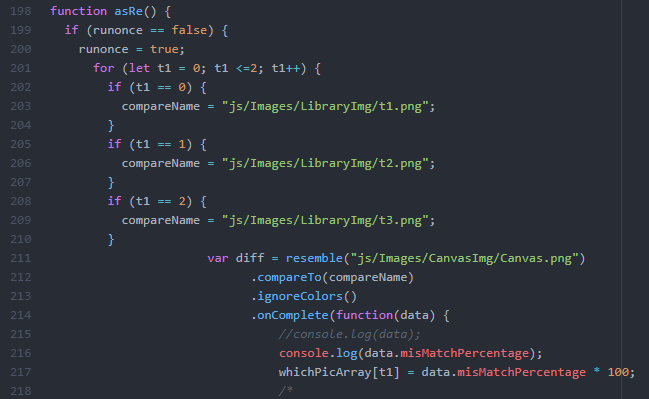
ran through the single call to load the saved canvas image.

In order to run the function that calculates the resemblance of the two images, you would need to reload the page. I never figured out why that is.
I ended up hard coding the call for the three images in the library but I had plans to use for loops in order to run through folders categorizing the different shapes from each other, then append saved canvas images to their corresponding categories, allowing the library to expand therefore ‘training’ the model. While I may have had a much easier time not downloading and uploading images, I wanted to keep it this way as a strong base for further development, since I wanted this library to permanently expand, rather than resetting to the base library each time I reran the code.
Project File:
https://drive.google.com/open?id=1oGikrMPInQqwWK3dTkAtO7HYQRr_yHuQ