- Review
Cellular automata (CA in short) are essentially programs that consist of the following components: (1) a discrete space of dimension n G Z divided in cells; (2) a finite set of possible states for each cell; (3) a certain number (the same for all cells) of neighboring cells; and (4) a transition rule that fixes the next state each cell as a function of its current state and the state of its neighbouring cells. (Gil & Alfonesca)
There is an elementary, one-dimensional subset of CA. In an elementary cellular automaton, the state of next generation of cells is determined by the state of that cell and its two neighbours in the current generation.
It is deemed one-dimensional since it can be easily expressed as a single, one-dimensional array. However, instances of ECA are usually expressed on two-dimensional planes, with each subsequent generation on an y-axis and order of cells on an x-axis.
A curious property of ECA is that their rule sets can often be represented in 8-bit binary sequences. 8 possible combinations of triads of binary (standing for one cell and its two neighbours) are defined in a descending order. Then for each triad, a resulting cell in the future generation is defined as either 0 or 1.
Hence, different variations are named after their the decimal equivalents of binary sequences, for example Rule 90 (standing for 01011010) or Rule 110 (01101110).
Elementary cellular automata are explored in depth in a controversial book called “A New Kind if Science” by S. Wolfram. His main thesis (and the main controversy related to the book) is that there’s a new kind of complexity-related scientific inquiries to be made, which can largely explain the complex mechanisms of chemistry, biology, and more.
He is using several examples of ECA to support his thesis. Various combinations of rules can generate simple patterns such as checkerboard (Rule XXX). A slightly more complex one is the Sierpinski Triangle (Rule 30) which stands for a series of symmetrical triangles that form a repetitive, steadily increasing pattern of triangular shapes.
Wolfram takes it a step further and focuses more on rules that generate asymmetry, complexity, or even randomness. An example of that is Rule 110. Based on a relatively simple ruleset, a pattern is generated that does not repeat itself, while generating convergences and similarities in certain parts of its growth. It is, as Wolfram would describe it, on the boundary between predictable and unpredictable.
The further part of this paper will focus specifically on implementations of elementary cellular automata, including one written by myself. Further, different approaches will be compared for efficiency and accuracy.
2. Implementations:
2.1. Devin Acker’s rules for automata
https://github.com/devinacker/celldemo/blob/gh-pages/index.htm
The program is a simple implementation written in JavaScript, and drawn in an HTML canvas element. The preview is publicly available both as a GitHub repository and a standalone website.
The simple user interface enables the user to pick a specific rule of the automaton, as well as choose a starting condition. After the user clicks “Start” the function draw_row() runs every 10 milliseconds. (This creates 100 rows per second).
This implementation creates one-dimensional data. Two arrays are running at the same time, current and next. After data is read and matched, next becomes current, and then the function is invoked again after 10 milliseconds.
2.2. p5.js reference
https://p5js.org/examples/simulate-wolfram-ca.html
A somewhat simpler implementation (albeit lacking a GUI) has been created for the purposes of p5.js reference. Here, the update rule is invoked in the draw() loop, which means a new row is drawn every time a frame is updated (30 times per second).
The program creates new generations and draws them at once. One generation at a time is created. Previous generations are not stored anywhere.
Rules are written down as a series of three-conditional statements. There is a variable ruleset that can be changed by altering the ruleset array.
2.3. Custom implementation
https://editor.p5js.org/krawc/sketches/Fn7Yj4U78
Before exploring any other implementations, I have created my own one. It was based solely off of the general rules of cellular automata found in the Wolfram’s book and various online resources.
The main difference from the two other implementations is its two-dimensionality. Values are stored in an array of arrays, accessible anywhere in the code. This means rules can be created that use further-up rows, or farther neighbours.
The entire image is generated at once, so one cannot see the progress of it – just the end result.
Due to design of this implementation, values are being stored in an easily accessible two-dimensional array. This means I can tinker with various arrangements of triads – instead of just taking three cells next to each other, I can get cells 5 steps away rom each other, or cells from upper rows.
Here are several of the more complexity-generating variations of the original algorithm.
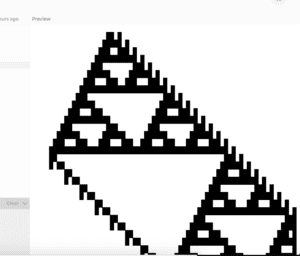


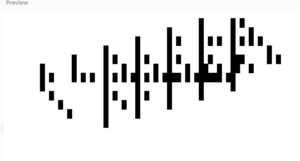


Reflection:
Somewhat accidentally, I ended up with an implementation that was more versatile than the two other ones. It was mostly because it had an easily accessible memory of previous generations.
It’s fairly easy to generate Rule 30, Rule 90 or 110, by simply providing a byte string in function setup().
Some of the variations are actually complex enough to mimic random behaviour. This is something that perhaps, with an appropriate offset, could be used as a generator for random QR codes.
Either way, elementary cellular automata constitute a curious case of phenomena that border between predictable and random. This is especially visible in case of Rule 110, which has shown to generate intricate complexities.
These phenomena, although not independent from the legacy of previous sciences (mostly mathematics), let us reflect and pose questions about the nature of science. Is not science precisely about trying to find patterns and makes sense of the “chaotic”? If we cannot directly observe events such as the origination of the universe, or of life on Earth, can cellular automata point us at the right direction at explaining the complexity?
Even in cellular automata, there has to be a condition that starts the chain of events, and that one is usually chosen arbitrarily. Nevertheless, I think generative complexities like ECA are a useful simulation tool.
References:
Gil, F. J., & Alfonseca, M. (2013). Fine Tuning Explained? Multiverses and Cellular Automata. Journal for General Philosophy of Science, 44(1), 153-172. doi:10.1007/s10838-013-9215-7