When training the CNN using CIFAR10 dataset this week, I focused on two parameters, batch_size and epochs. And I have found something very interesting.
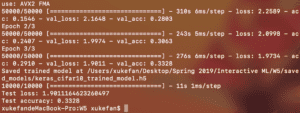
This screenshot shows the original result, given the parameters used during the class. In oder to get this result, the batch_size was set to 2048 with 3 epochs. We can see that every epoch approximately took 4-5 minutes. The test loss was 1.90 with the accuracy of 0.33.
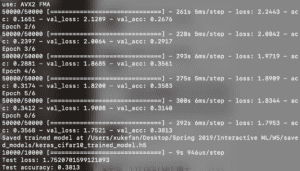
Then I changed the epoch to 6. There isn’t any change with the time that every epoch took. From the result, we can see that it brought a slightly increase in its accuracy, from 0.33 to 0.38.

Then I doubled the batch_size with 3 epochs. Still, the time it took during each epoch didn’t change much. But the loss increased and accuracy dropped to 0.29, even lower than the first result.
Since it seemed that increasing the batch_size can’t contribute to the accuracy, I reduced the batch_size to 32, which was the batch_size of the given example. I ran it with 3 epochs.

The result showed that it took less time in each epoch. Surprisingly, the accuracy increased a lot, to 0.54. It seemed that a smaller batch_size willed to a higher accuracy. So in the forth training, I reduced the batch_size to 16, and it yield an accuracy of 0.58. Then the training with the batch_size of 8 yield an accuracy of 0.62.


Since I did all the training on my own computer, the epoch times is limited. But given enough time, I am confident to bring the accuracy rate to over 75% which is the accuracy rate in the example using a batch_size of 32 with 50 epochs.
But why smaller batch_size will lead to a higher accuracy? Since the batch_size refers to the number of samples the model trained in each step. The result suggested that if we train it with less sample, the result will be better. This conclusion conflicts with my intuition. I took the Machine Learning class in the last semester. And I learned the concept of overfitting in that class. So I am wondering if this is the case. If we train the model with small batch_size, the model is still far from prefect but will have a good match with the testing set. To prove my assumption, I might use other dataset to test the model later.