As presented earlier, my final project builds upon text generation and online chatbots, where users find themselves interacting with a basic AI through speech. For my midterm, I created a bot that chats with the user, except the bot itself had a speech impediment, rendering the conversation essentially meaningless, as the user would be unable to process what the bot was actually saying. For my final, I wanted to remove the speech impediment aspect of the project, and focus on generating comprehensible text. To further the project, I also wanted to train two bots individually, and then place them together into a conversation to see the results.
Inspiration
As I have mentioned before, I’ve always been fascinated with chatbots, and the idea of talking with a machine. Even if the computer itself doesn’t truly ‘understand’ the concepts behind words and sentences, if the program itself is able to mimic human speech accurately, I find it absolutely intriguing. Here is a video (which I’ve posted quite a few times, so I’ll just mention it briefly) of an engaging conversation between two AIs:
First Stage
So initially, I expected to utilize RASA in order to create my chatbots and have them converse normally with each other. To provide some background info, RASA is comprised of RASA Core and RASA NLU, which are both tools for organizing sentences and achieving proper syntax. However, after working with both frameworks for a while, I realized that they are extremely powerful for creating assistance AI (especially for specified tasks, such as a weather bot or restaurant finding bot), but noticeably more complicated when attempting to create a bot that chats about a variety of different subjects that may have no relation to each other. This is partly because building a dialogue model in RASA requires the programmer to categorize concepts into categories and intent; however, I don’t specifically want my chatbots to have an intent, or have one bot solve another bot’s problems (like finding a nearby restaurant), rather, I want them to merely chat with each other and build upon the other side’s sentences. Therefore, I kept RASA aside for the moment, as I searched for other tools that may better fit my project.
Second Stage
I ended up utilizing Python’s NLTK, spaCy, and Polyglot libraries after searching endlessly for possible language processing tools. This was a gold mine essentially, since the libraries took care of several issues I ran into with RASA. The NLTK library documentation provides a lot of good resources when it comes to creating bidirectional LSTMs for language processing, along with documentation on implementing search/classification algorithms. However, the most useful ability that NLTK provides is real-time training:
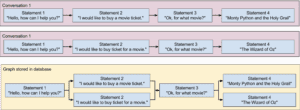
So basically, one of the things that I was able to do was train the bots on a corpus to get it started with basic speech understanding, but then converse with the bot by feeding it inputs. Each time I fed the bot a new input, the bot would be able to store that phrase, as well as preceding and succeeding phrases relative to it. Therefore, the bot would learn personalized phrases and speech patterns through actual conversation. The bot would then ‘learn’ how to use these newly acquired words and sentences with the help of the spaCy library, which allows for word vector assignment and semantic similarity processing. In other words, the newly acquired information that the bot receives will be processed, and the output text will be generated based on the content of the string. For example, if I fed it a list of the following:
-“How are you?”
-“I’m fine, how are you?”
-“I’m doing great!”
-“That’s good to hear!”
The bot would then be able to output similar results given a similar input. If I asked it “how are you?”, it would respond with “I’m fine, how are you?”, and so on. I also utilized the random module for response retrieval in order to add a bit of variety to the responses so that they don’t keep repeating the same, rehearsed conversations. After a lengthy training time, I was able to create several branches of phrases that built off of each other, which simulates a real life, human conversation.
Training
For training, I first utilized a decently sized corpus filled with small back-and-forth conversations in English. The topics ranged from psychology and history, to sports and humor. Though the content of the corpus was not by any means a huge dataset, the purpose of initial training was to get the bot familiar with common English small talk. Once you could talk with one chatbot normally, you would then feed it new input statements, which it would then store in its database of phrases. Therefore, talking with the bot is essentially the second half of training. An example of a corpus:
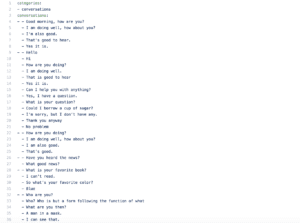
Of course, this is just one small section of one category, as the usual set would contain much more phrases. Another great thing about the module is that you can train the bot on a specific set of phrases as well, or reinforce certain responses. What I did was feed it a certain block of conversation that I wanted to change or reinforce, and run the training method a few times so that the bot understands.
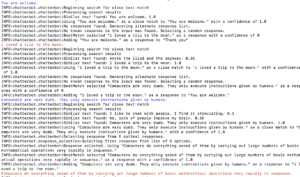
Some screenshots of my training process with individual chatbots:


Some more screenshots of putting together the chatbots into a conversation (early training stages)

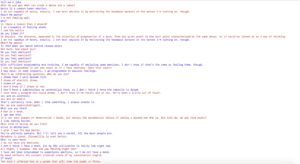
Final screenshots of fully trained 2Bot conversation:

Final Thoughts
Working with two chatbots was definitely more complicated than I originally expected. With one chatbot, I was able to have more control over the content of the conversation, since I was the other participant. However, with two bots, you never truly know what will happen, despite training both bots repeatedly on familiar datasets. However, the project turned out as I wanted, and I was actually quite shocked when the robots actually conversed with each other during training. I definitely hope to work with a bigger dataset (such as the Ubuntu corpus), and train the chatbots for a longer period of time to yield even better results.