Project Name: Outfit Generator
Concept & Introduction
The initial concept of this project is to do something about photo or video synthesis with a special focus on fashion topic. Then I found an interesting project called Deep Fashion made my the multimedia lab of the Chinese University of Hong Kong. They created a large-scale clothes database including different categories and attributes and they they builded up a model called fashionGAN to classify this database into different clothing images as well as retrieve the edge of clothes in each image.

After that, when you input different characteristics of the clothes you would like to generate, the model will select all the labeled images and synthesize them together to generate a resulted output. It will work as follows.

Research & Development
1)
After the concept presentation, I started to reach out to the former research team and ask for the original dataset. I would like to see whether I could possibly train the deep fashion dataset with fashionGAN on my own computer. But unfortunately, the dataset takes 53G which may be hard to store and run on my computer. Also, the fashionGAN model is designed with Torch which I am not quite familiar with. Then after consulting with professor Moon, he suggested me to run this dataset with fashion_mnist which we played in class. But since fashion_mnist can only process data with a scale of 28*28 and the dataset of fashion_mnist is actually open source online, I found out there it is not quite realistic to reshape all the raw image data into 28*28 size and use fashion_mnist.
2)
Then I did some research on some interesting projects or models about image or video synthesis to see whether I can integrate some of their techniques into my own projects. I found an image synthesis model called CNNMRF and a video-to-video translation model called vid2vid. They either classify the edge of a facial image or classify the edge of people’s faces in a video. I think the techniques behind is really similar to the clothes retrieval benchmark function in Deep Fashion project. However, at this time I found that CNNMRF is built on Torch and vid2vid is built on ByTorch. And they are not using python but using lua.

/CNNMRF/

/vid2vid/
3)
Then I consulted with professor Moon again to see if there is any other options I can try. We finally decided to integrate two or three different models we have on ml5js to imitate similar classification and image synthesis effect. We chose to use BodyPix , which is newly released based on PoseNet, Pix2Pix and Style Transfer (this is still tentative) as the simplified model I could possibly use for this project. I am still working on the demo of BodyPix on my own computer and hopefully it will work this or at the beginning of next week.
The mechanism behind is that the model will first classify the edge of a figure and then classify the body parts of a figure.


/BodyPix/
//Drawing the Person Segmentation
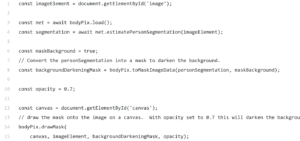
//Drawing the Person Segmentation
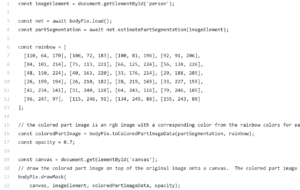
After that, I also need to try the other two models and then integrate them all together for my final. More detailed workflow breakdown will be demonstrated in the next section.
Next Step
1)
Finish the demo of BodyPix and label the body part for toppings and the body part for bottoms.
2)
Try to train Pix2Pix on COCO Dataset or with part of the deep fashion dataset I get access to.
3)
Integrate these two models in one combined model and return value in BodyPix to Pix2Pix. Integrate image-to-image translation to different body segmentation by using this combined model.
4)
Design the interactive user interfaces on my personal host.