As described in my previous post, I wished to explore GANs and generative art in my final project. In particular, I was very interested in cross-domain translation, and since then, I feel I’ve come a decent way in terms of understanding what sort of GAN model is used for what purposes.
After doing some initial research, I came across multiple different possibilities in terms of the possible datasets I could use.
Since this involves two domains, I need two datasets, namely human faces and anime faces. Getting the human faces dataset was quite easy, I used the popular CelebA dataset. Since this set came with over 250000 images, I decided to just use 25000 since that would speed up training time. (Later, I found out that 25,000 is way too much and would still be extremely slow, so I opted for a much, much more smaller set)
For the anime faces dataset, I had a few options to pick from.
Getchu Dataset – This dataset came with roughly 21000 64×64 images
Danbooru Donmai – This dataset had roughly 143,000 images
Anime Faces – This had another 100,000 or so images.
I decided to go with the Getchu dataset since that would mean an equal load on each GAN in the cycleGAN model.
Here is a sample from both datasets.
Having done the cycleGAN exercise in class, I came to understand how slow the Intel AI cluster was ,and proceeded to find other means to train my final project model. Aven mentioned that some of the computers in the IMA Lab have NVIDIA GTX1080 cards and are very well suited for training ML models. I then went on to dual-boot Ubuntu 18.04 onto one of them. Once that was done, I needed to install the necessary nvidia drivers as well as CUDA, which allows you to use TensorFlow-GPU. I severely underestimated how long it would take to set up the GPU on the computer to run Tensorflow. This stems from the fact there is no fixed configuration for setting up the GPU. It requires three main components – the Nvidia driver, the CUDA toolkit and CuDNN. Each of these have multiple different versions, and each of those different versions have different support capabilities for different versions of TensorFlow and The key idea is to grow both the generator and discriminator progressively: starting from a low resolution, we add new layers that model increasingly fine details as training progresses. This both speeds the training up and greatly stabilizes it, allowing us to produce images of unprecedented quality_Ubuntu. So, setting up the GPU system took multiple re-tries, some of which resulted in horrendous results like losing access to the Linux GUI, and control over the keyboard and mouse. After recovering the operating system and going through multiple Youtube videos like this, as well as Medium articles and tutorials, I was finally able to set up the necessary GPU drivers that can work
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2with Tensorflow-gpu.
Once, I had my datasets, I proceeded to look for suitable model architectures to use my images on. I came across multiple different models, and came down to a question of which one would be most suitable.
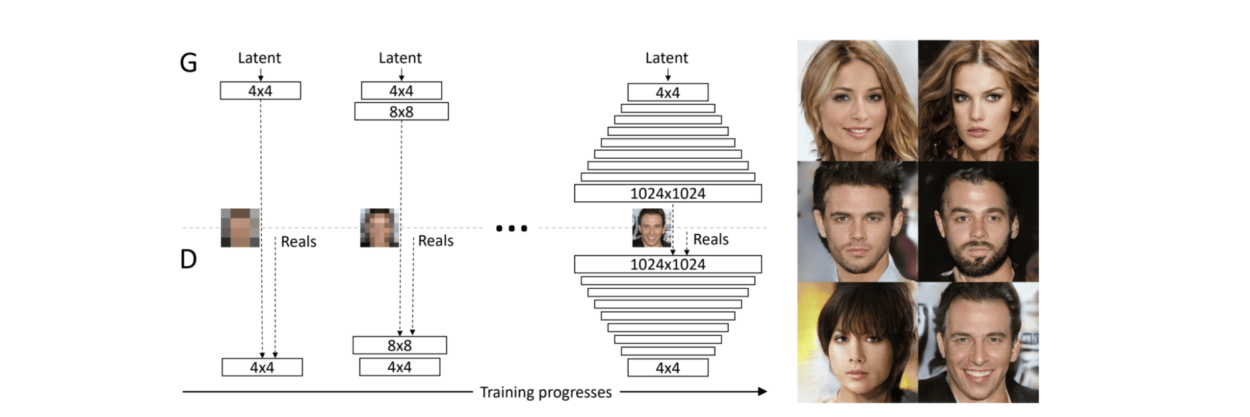
The first model I came across was called TwinGAN which the author described as “Unpaired Cross-Domain Image Translation with Weight-Sharing GANs.” This particular model of GAN is based on an architecture called a Progressively Growing GAN or PCGAN. The author describes the architecture as “to grow both the generator and discriminator progressively: starting from a low resolution, we add new layers that model increasingly fine details as training progresses. This both speeds the training up and greatly stabilizes it, allowing us to produce images of unprecedented quality.”
It is clear that this architecture would allow for higher resolution outputs as opposed to the classic cycleGAN.
Here’s an illustration of how PGGAN (the model that TwinGAN is based on) works.
The first step was to prepare the datasets, and the author of the TwinGAN model had structured the code in such a way that the code takes in .tfrecord files as inputs instead of regular images. This meant there was an additional pre-processing step but that was fairly easy using the scripts provided.

After that was done, it was a matter of setting up the training scripting script with the updated datasets and relative paths with the new training sets. Once that was set up, it was just a matter of launching the script and hoping that it would start the training task. However, it turned out that that wouldn’t be the case. I was presented with errors such as these.
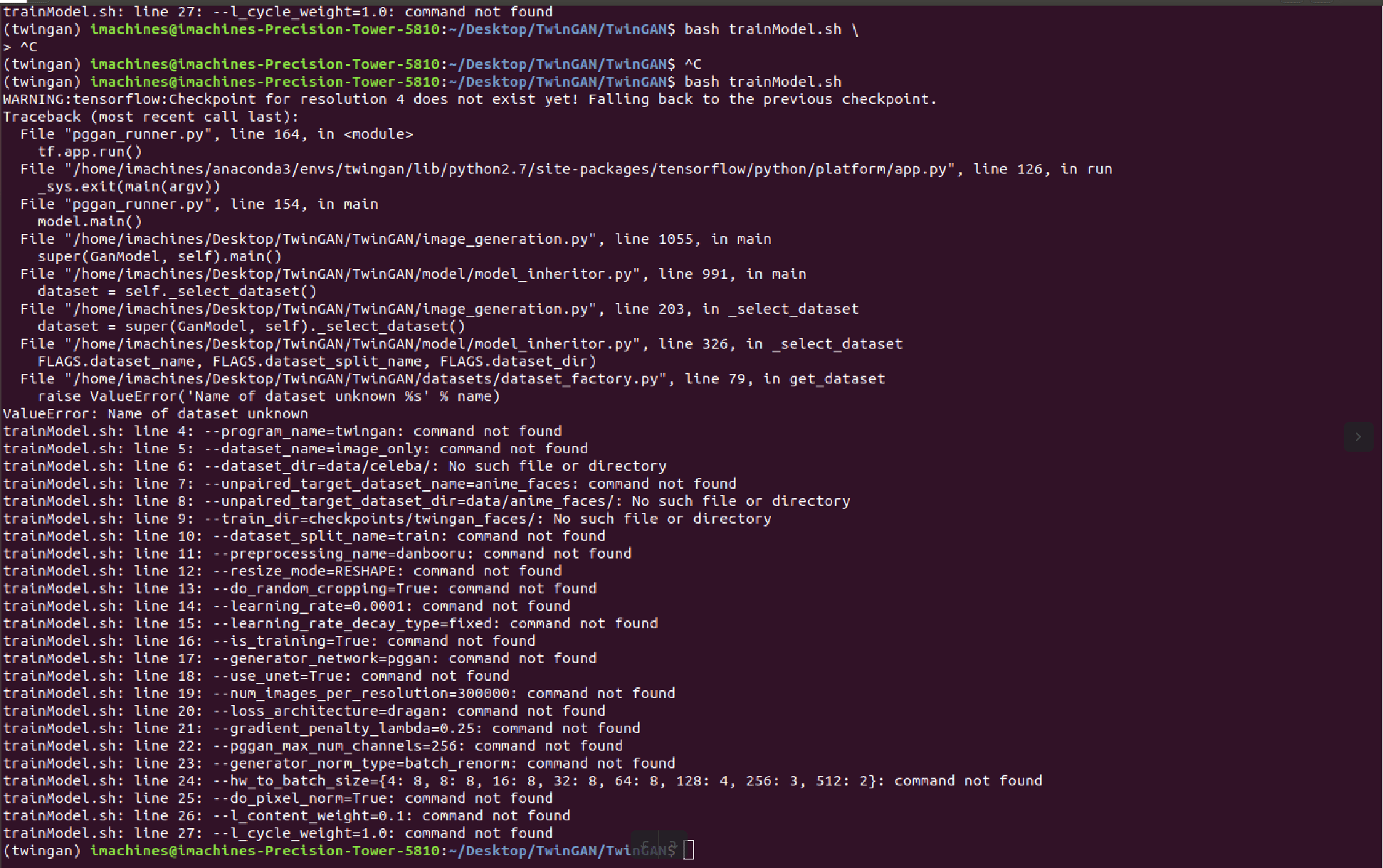 

Initially, I was presented with a few “module not found” errors but that was resolved fairly easily after installing the relevant module through pip/conda.
With errors such as the one above it is difficult to determine from where they began propagating far since I had a very limited understanding of the code base.
Prior to running the code, I set up a conda environment with the packages as described by the author. This meant installing very specific versions of specific packages. His requirements.txt is below:
tensorflow==1.8
Pillow==5.2
scipy==1.1.0
However, he did not mention which version of Linux he had been using, nor had he mentioned whether or not the code was CUDA-enabled, and if it was, which version of CUDA it was running on at the time. This made it difficult to
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2determine which version of CUDA/Tensorflow-GPU/etc would be most compatible with this particular codebase.
I went through the past issues on his Github repo, but could not find any leads on what the issue might have been, so I decided to open up an issue on his repo. 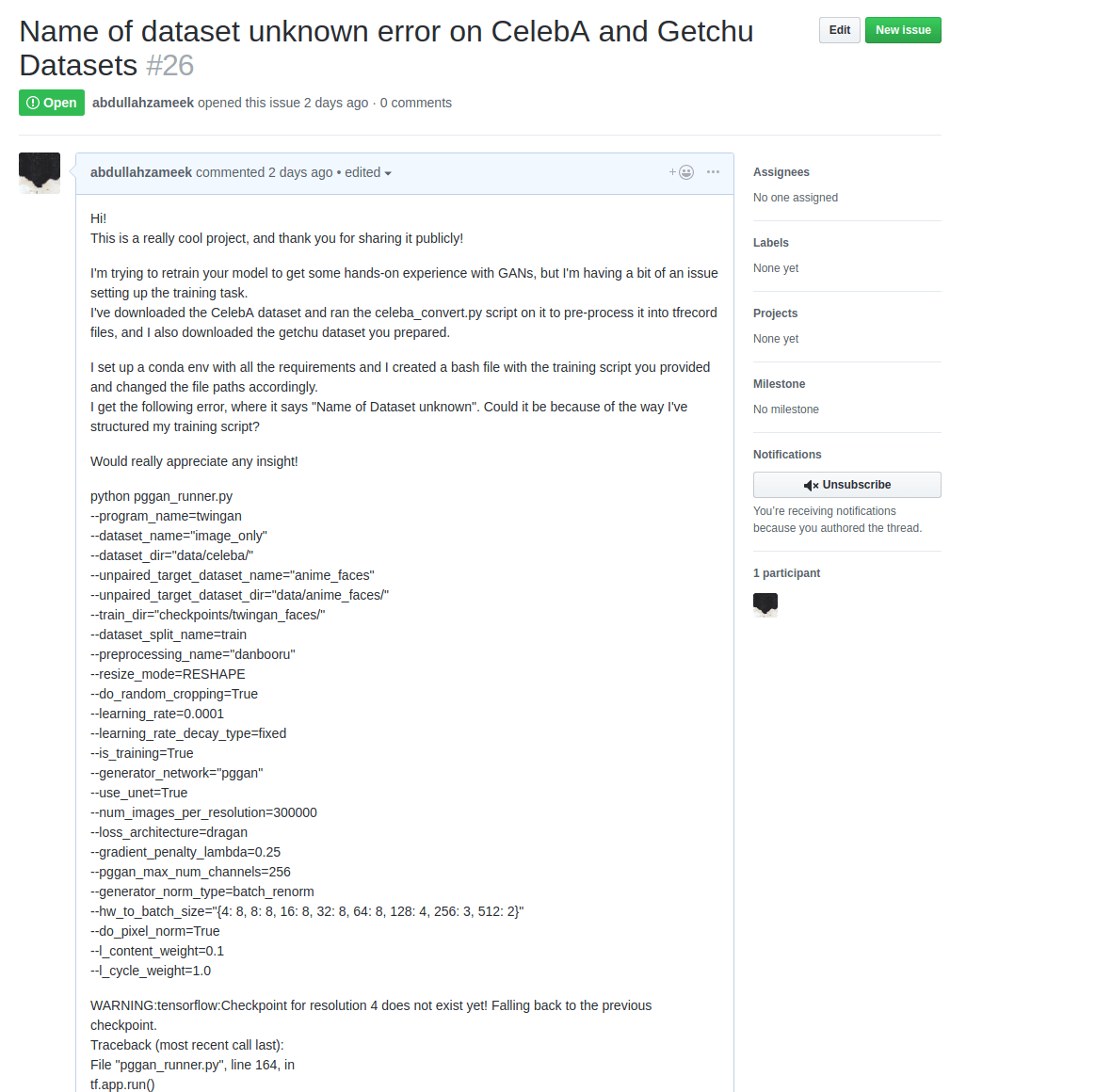
At the time of writing this post, two days have past since I opened the issue, but I haven’t received any feedback as of yet.
Seeing that I wasn’t making much progress with this model, I decided to move onto another one. This time around, I tried using LynnHo’s cycleGAN (which I believe is the base of the model that Aven used in class). The latest version of his CycleGAN uses Tensorflow 2, but it turned out Tensorflow 2 required the latest CUDA 10.0 and various other requirements that the current build I set up didnt have. However, Lynn also had a model previously built with an older version of Tensorflow so I opted to use that instead.
I took a look at the structure of the training and test sets and modified the data that I had to fit the model.
So, the data had to be broken down into 4 parts : testA, testB, trainA, trainB.
A is the domain you’re translating from, and B is the domain you’re translating too.
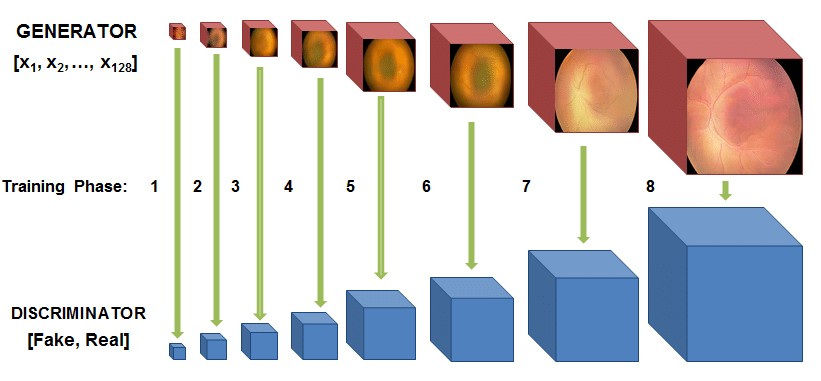
For the sake of completeness, here’s a illustration of how CycleGAN works.
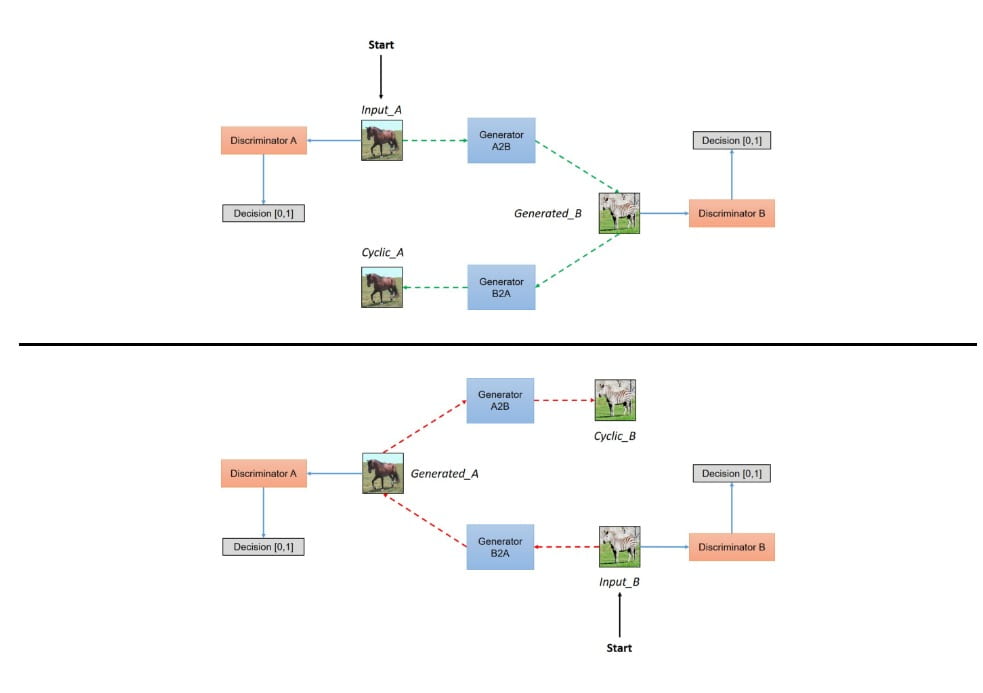
The next step was set up the environment and make sure it was working. Here are the requirements for this environment:
- tensorflow r1.7
- python 2.7
I looked fairly straightforward and I thought to myself, “What can go wrong this time?” Shortly after, I went through another cycle of dependency/library hell as many packages seemed to be clashing with each other again.
After I installed Tensorflow v.1.7, I verified the installation, it seemed to be working fine.
 

However, after I installed Python 2.7, the Tensorflow installation broke.
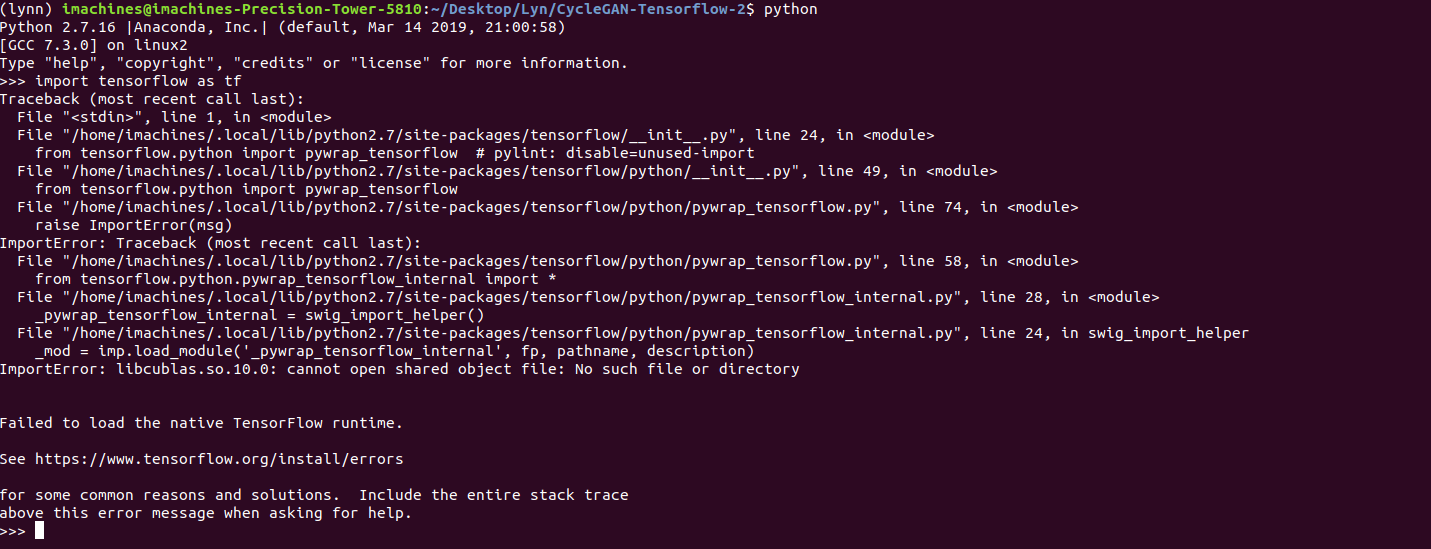
Once again, I had to deal with mismatched packages, but this time, it was incompatibilities between Tensorflow and Python. After looking up what
“ImportError: libcublas.so.10.0: cannot open shared object file: No such file or directory”, I then learnt that it was because Tensorflow was looking for the latest version of CUDA and CuDNN. One solution was to install CUDA and CuDNN through conda and once I did that, I tried to verify Tensorflow once again. This time, I got another error.
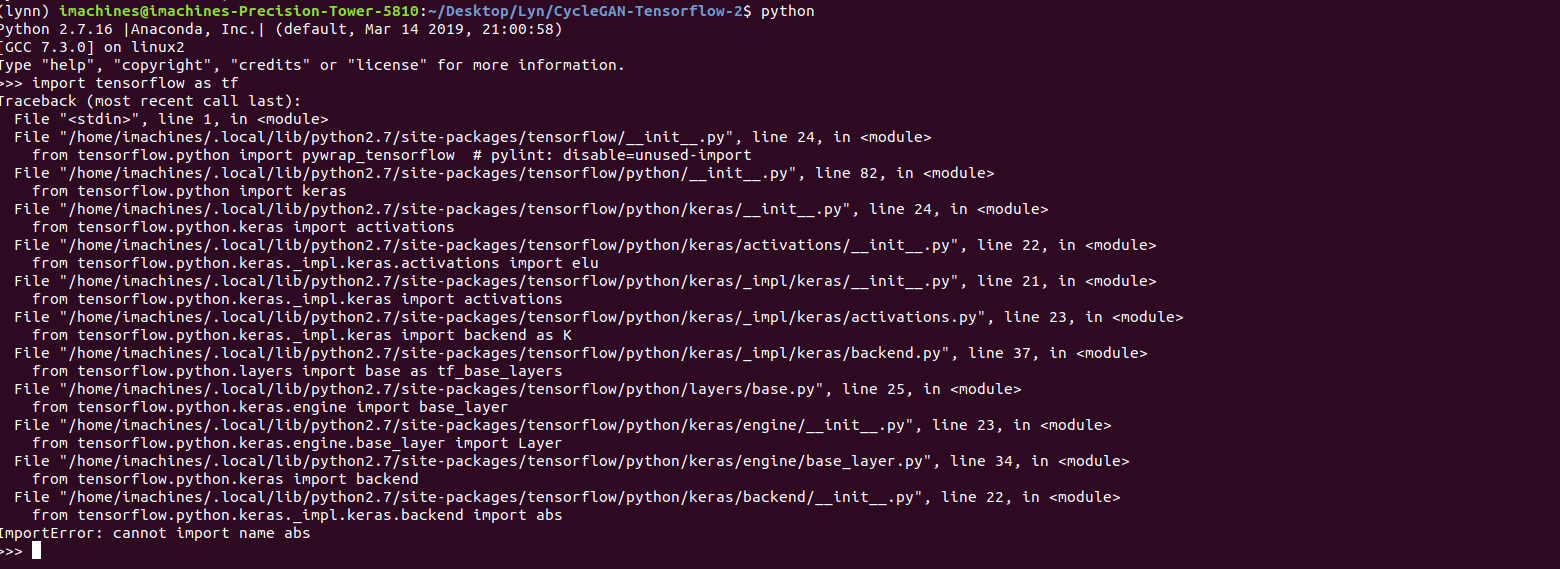 

The error this time read, “ImportError: cannot import name abs” and it was spawned by tensorflow.python.keras which from my very brief experience with TF, was a generally troublesome module. After going through multiple fixes, the environment itself was ridden with many inconsistencies and it got to a point where the Python terminal couldn’t even recognize the keyword “Tensorflow”
 

At this point, I hit a complete dead end, so I cleaned out the conda cache, deleted all the environments, and tried again. Once again, I was met with the same set of errors.
Since it looked as if I wasn’t making much progress on these other models, I opted to use Aven’s Intel-AI cluster model since it was already tried and tested. Note that the reason why I opted to use another model was because my intention was to train it on a GPU and that would allow me to use a larger dataset to obtain weights in a relatively shorter amount of time. Additionally, it gave me the ability to explore more computationally complex models such as PGGAN that require way more resources than regular cycleGAN models.
In any case, I began configuring the AI cluster optimized model with my dataset, and initially, I set it to run with 21,000 images (not intentionally). The outcome however, was quite amusing. After roughly 16 hours, the model had barely gone through one and a half epochs.
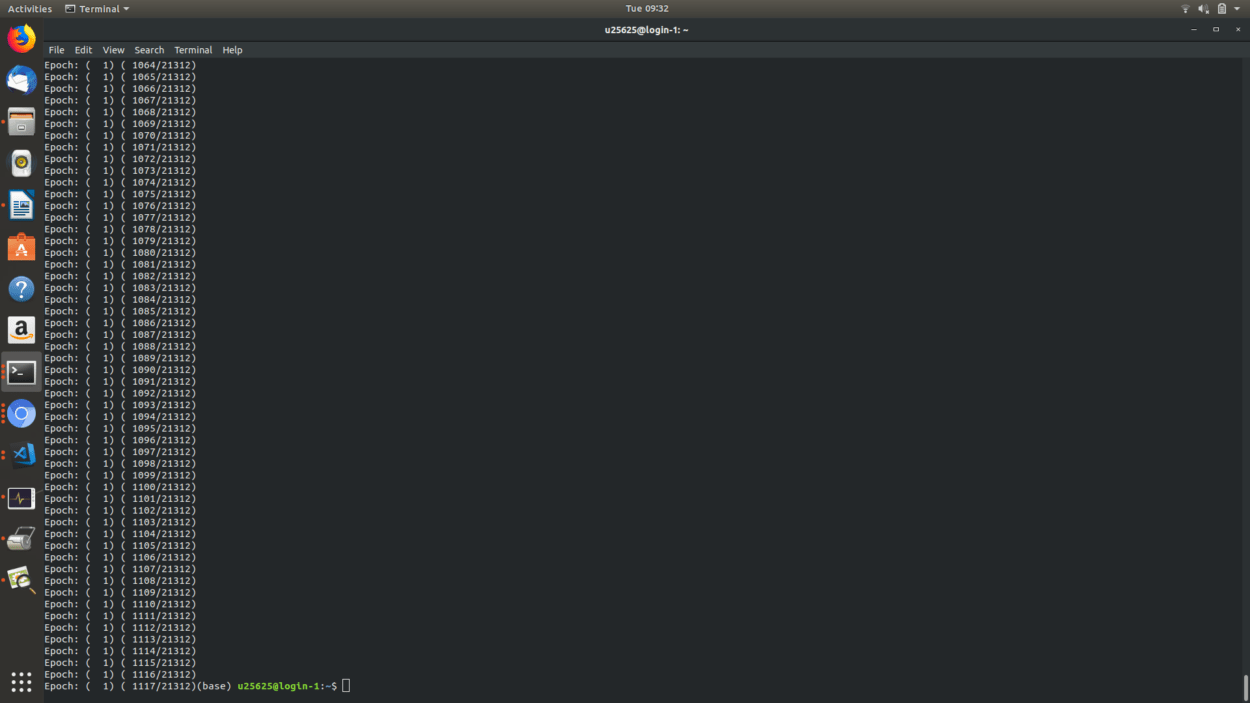
Afterwards, I trimmed the dataset down greatly as follows:
Train A : 402
Train B : 5001
Test A : 189
Test B: 169
With this set, I was able to train the model to 200 epochs in just over two days. Once I copied the weights over and converted the checkpoints to Tensorflow.js, I put the weights through the inference code to see the output, and this is what I got.

The result is not what I expected because of the fact that I did not train on a large enough dataset, and I did not train for enough epochs. But, judging by the amount of time I had plus the computation resources at my disposal, I feel that this is the best model I could have put up. At the time of writing this post, another dataset is currently training on the Dev Cloud, which will hopefully render better results.
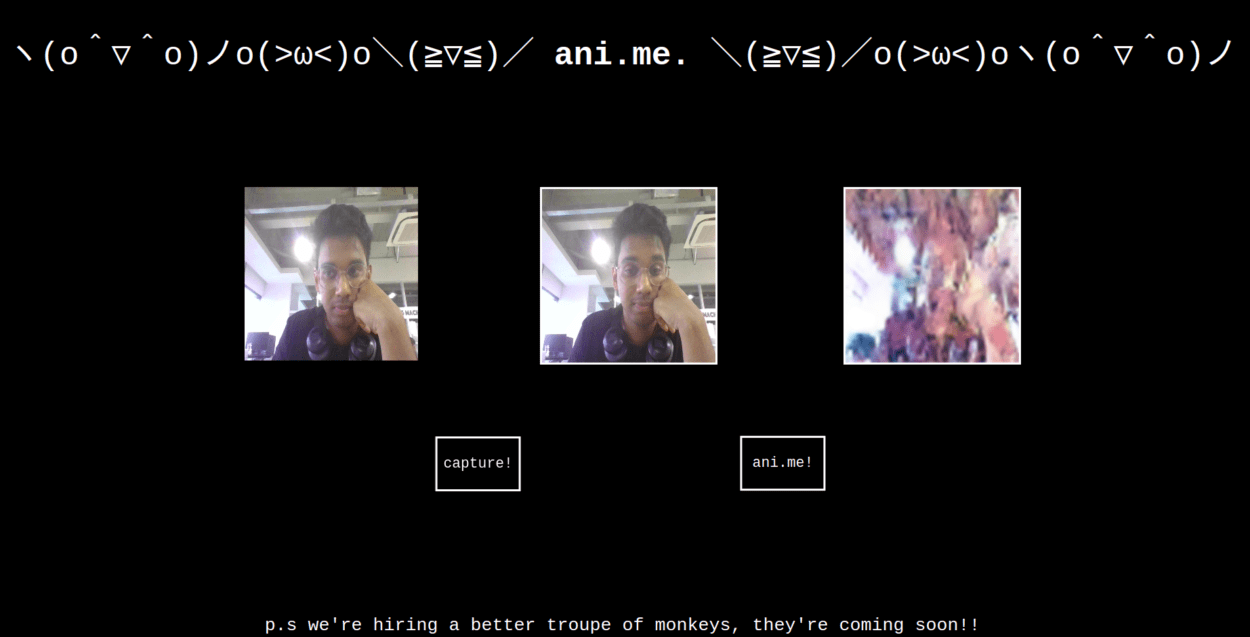
With regards to the actual interface, my idea was that the user should be able to interact with the model directly, so integrating a real-time camera/video feed was essential. Enter p5js.
I wanted to present the user with three frames – a live video feed, a frame that will hold the picture that they click, and the GAN generated picture. Going from the second to the third frame was really easy, we had done it already in class, so doing that was really easy. The problem was going from the first frame to the second. I thought it would be fairly easy, but turns out it was actually a tad bit more complicated. This is because while p5js has the capability to “take a picture”, there is no direct way to actually render that picture back to the DOM. The solution was to extract the pixels from the necessary frame and then convert those to base64, and pass it through the src of the second frame using plain, vanilla JS,
The actual layout is very simple, The page has the three frames, and 2 buttons. One button allows the user to take a picture and the other initiates the GAN output. I’m really fond of monochromatic, and plain layouts, which is why I opted for a simple and clean black and white interface. I’ve grown quite fond of monospace, so that’s been my font of choice.
Additionally, I decided to host the entire sketch on Heroku, with the help of a simple Node server. The link to the site is here . (You can also view my second ML-based project for Communications Lab, sent.ai.rt, over here )
However, please do exercise a bit of caution before using the sites. While I can almost certainly guarantee that the site is fully functional, I have had multiple occasions where the site causes the browser to become unresponsive and/or clog up with computer RAM. This is almost certainly because of the fact that all the processing is done on the client side, including the loading of the large weights that make up the machine learning model.
The main code base can be found here and the code for the Heroku version can be found on the same repository but under the branch named “heroku”
Post-Mortem:
All in all, I quite enjoyed the entire experience from start to end. Not only did I gain familiarity with GAN models (upto some extent), I also learnt how to configure Linux machines, work with GPUs, deal with the frustrations of missing/deprecated/conflicting packages in Tensorflow, Python, CUDA, CuDNN and the rest, learning how to make code in different frameworks (Tensorflow.js and p5.js , in this case) talk to each other smoothly as well as figure out how to deploy my work to a publicly view-able platform. If there were things I would have done differently, I would have definitely opted to use PGGAN rather than CycleGAN since it is way better suited for the task. And, even with CycleGAN, I wish I had more time to actually train the model more to get a much cleaner output.
On the note of hosting and sharing ML-powered projects on the web, I am still yet to find a proper host where I can deploy my projects. The reason why I opted for Heroku (other than the fact that it is free) is because I am reasonably familiar with setting up a Heroku app, and in the past, its proven to be quite reliable. On another note, I think it is important to rethink the workflow of web-based ML projects seeing that
a) Most free services are really slow at sending the model weights across to the client
b) The actual processing on the browser seems to be taking a great toll on the browser itself, making overloading the memory and crashing the browser very likely.
I think that, in an ideal scenario, there would be some mechanism whereby the ML-related processing is done on the server side, and the results are sent over and rendered on the front end. My knowledge related to server side scripting is very, very limited, but had I had some extra time, I think I would have liked to have tried setting up the workflow in such a way that the heavy lifting was not done on the browser. That would not only lift the burden off the browser but would also make the user-experience a lot better.