Original Goal:

Build a project that takes audio input and matches that audio input to the closest equivalent quotation from a movie, yielding the video clip as output.
Original Plan: Use WordtoVec to complete this with SoundClassification.
Completed Tasks:
- Acquired the entire film
- Acquired the subtitles
- Realized Word2Vec didn’t work
- Found an example of something that COULD work (if I can get the API to actually work for me too)
- Started playing with Sound Classification
- Spliced the entire movie by sentences… (ready for output!)
Discoveries:
WordtoVec doesn’t work with phrases. The sole functionality is mapping individual words to other words. And even then, it does such a horrific job that barely as of the movie plot is distinguishable by searching these related terms. Half the associated words just are not usable after training the model on the script from Detective Pikachu.
I’ll talk through the examples and how I was able to train the model on the subtitle script.
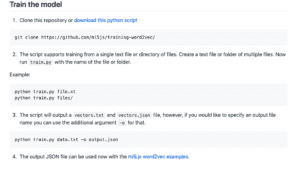
In order to train the model, I had to get the script into a usable format, because straight up the first time I did it, I left all the time stamps and line numbers in the subtitle document, so when it trained, the entire response list was just numbers that didn’t actually correlate to the words I typed into the sample in a meaningful way.
TEST 1: SUBTITLES INTO TRAINER WITH TIME STAMPS + LINE NUMBERS
Results:
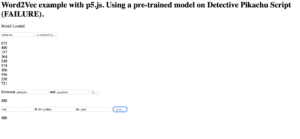

I took the numbers that were outputted and compared it to the subtitles… then, since the subtitles don’t clarify which character said what, I went into the movie… which honestly… yielded mixed results. Leading me to conclude that there was no actual meaningful correlation between this output and the script itself.








Conclusion:

So is this data usable? Not really… it’s usually connecting words that yield that high correlation… so I decided to go back to the drawing board with testing. Which is really unfortunate considering how long this initial test took start to finish.
TEST 2: SUBTITLES INTO TRAINER WITHOUT TIME STAMPS + LINE NUMBERS
Results:
I went back and edited out all the time stamps and line numbers… and the results were still mixed in terms of giving me relevant words.









Is this usable information? Not even remotely. Most of the outputs are poor and it is next to impossible to draw any sort of meaningful connection that is not just a plain connector word. My conclusion here was that Word2Vec was not the best option for my project. It simply couldn’t even get meaningful word connections… and it did not possess the capability to analyze sentences as sentences.
Conclusion:

I asked Aven if I could quit Word2Vec… he said as long as I documented all my failures and tests… it would be fine… so that’s exactly what I did before starting completely over again! It was… needless to say incredibly frustrating to realize this very easily trainable model didn’t work for my project.
TEST 3: SENTENCE ANALYZER

So… this is was probably the saddest test I have seen. Seeing as I had nothing to work with… I went back to Medium to see if I could gain some sort of new insights into ml5… I stumbled upon this article about an ITP student’s project and thought I could go about my project in a similar way. He also references Word2Vec… but then explains that there is this other TensorFlow model that works for paragraphs and sentences! That’s exactly what I need! But as you can tell from above… it didn’t work out for me… after I had finally inputted the entire script. Hindsight is 20/20, I probably should have tested the base code BEFORE I inputted and retyped the script… it’s fine you know, you live and you learn.
This is the link to the GitHub Repo which is supposed to guide you just as the link from the ml5 website to the Word2Vec example, unfortunately there seems to be an issue even in their code, even after I downloaded everything necessary to run it (supposedly).
Conclusion:

Well… sometimes Holy Grail answers are too good to be true. I still haven’t given up on this one… I think maybe with enough work and office hours I can get the issue sorted, but this is definitely a potential solution to my issue… especially considering the ITP project, I definitely think this is the right way to go.
TEST 4: SOUND CLASSIFIER
This was one of the parts of my project, meant to be sort of a last step, making it the sole interaction. This is really something I only plan on implementing if I get the rest of the project functional! But I thought since I was experimenting as much as I was, it was time to explore this other element as well.
So what did I do?



This is nice. I think however, it’s incredibly difficult to get it trained based on your voice, considering HOW MANY LINES ARE IN A SINGLE FILM… it seems rather inefficient to do this. So I was thinking… is there a better method… or a method to help me train this Sound Classifier. And… I think I found something useful.

Conclusion:

I am not a computer science student… I don’t think I have the capabilities to build something from scratch… so I have really looked into this. And, should the main functionality of my project work with the Sentence Encoder… this could work to make the interaction smoother.
Progress Report:
I know what I need to use, it’s now just a matter of learning how to use things that are beyond the scope of the class. Or at the very least, beyond my current capabilities. This is a good start and I hope to have a better actually working project for the final. For now the experimentation has led to a clearer path.
Social Impact + Further Development:
In the case of this project, I see it developing into a sort of piece that serves as a social commentary on what we remember, what we really enjoy about media. I think there are so many different ways in which we consume media. We, as consumers all understand and really value different elements, characters, etc out of movies. There is something to be said about our favorite characters and lines, and why we remember them. Is your favorite character your favorite because it reminds you of someone you care about? Do you hate another character and not like their quotes because they play up on stereotypes you don’t believe in?
There is much to be said about who we like and why we like them. For the sake of my midterm, I think it’s best to say this project needs to go. I think in terms of developing on this social impact piece further, I want to maybe look at the psychological aspect of advertising. Are good movies foreshadowed by certain colorings and text? Is there basically an algorithm or recipe to pick out a good movie versus a mad movie? Are we as consumers based against low budget or movies created/acted in by minority actors?
I see that as the direction in which I can make this “Fun” gif generator a more serious work.