Experiment
This week’s assignment is to train the model. The first step for me is to understand the meaning and the function of the key concept. And then I will validate them by practicing.
- Epoch:
According to Sagar Sharma’s article on Medium, an epoch is when an entire dataset is passed forward and backward through the neural network only once. According to my trials, the more the time of epoch, the more accurate the result.
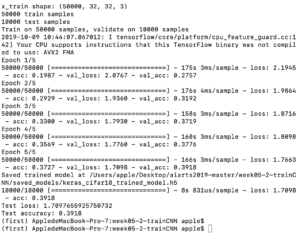
When the epoch is 5, as other variables are the same, the accuracy is 0.34.
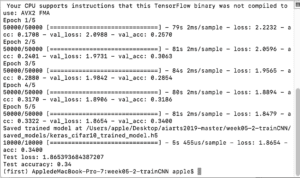
When the epoch is 8, the accuracy is 0.3964.
- Batch size:
The batch size means the number of samples that will be propagated through the network. Since one epoch is too big to feed to the computer at once we divide it into several smaller batches. For example, if the batch size is 50, the algorithm will divide every 50 samples into groups and use these groups of data to train the model. The larger the batch size, the faster the training.
In my experiment, the smaller the batch size, the more accurate the result.
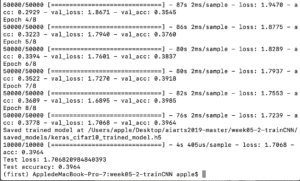
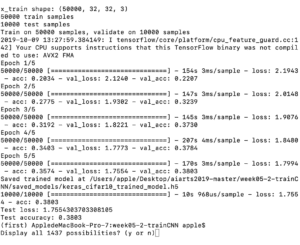
when the batch size is 1024, the accuracy is 0.4188 (epoch=5). The time it took is 409s.

when the batch size is 512, the accuracy is 0.4427(epoch=5). The time it took is 399s.
3.Dropout:
Dropout is a technique where randomly selected neurons are ignored during training. If some random neurons are dropped out during the training, others will replace them in the training. The result is that the network will be less sensitive to the specific weight of neurons and then get better generalization and to some extend avoid overfitting the training data.
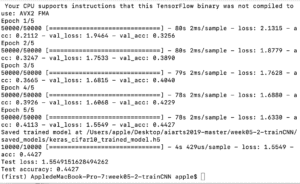
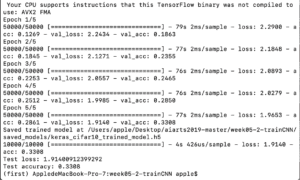
I changed the data of the dropout from 0.25 to 0.50 but the accuracy decreased from 0.34 to 0.3308. I’m still not so sure whether there’s specific and close relationship between the dropout and the accuracy since I did’t find clear explanation on the internet.
4. Size:
Confusion&Thought
I was confused about the relationship between the batch size and the accuracy. Since I have searched batch size before and the articles said that compared with the number of all the sample, the use of batch size will decrease the accuracy of the estimation of the gradient. According to this idea, I thought that the larger the batch size, the more accuracy the result. However, the real case is totally opposite. Then I did some deeper researches and found that the smaller batch size can help the model training better by adding a little bit of noise into the search. But the bigger batch can help run faster although it has to sacrifice the accuracy. So it is important to set up a proper batch size based on the total number of samples to keep the balance of the speed and the accuracy.