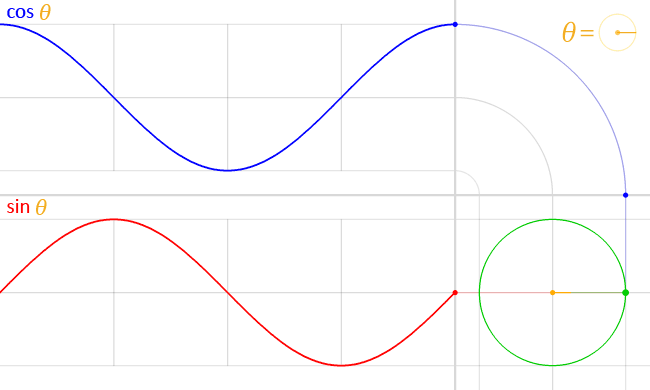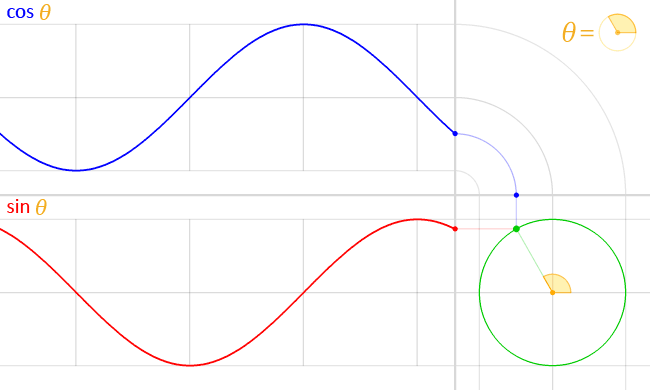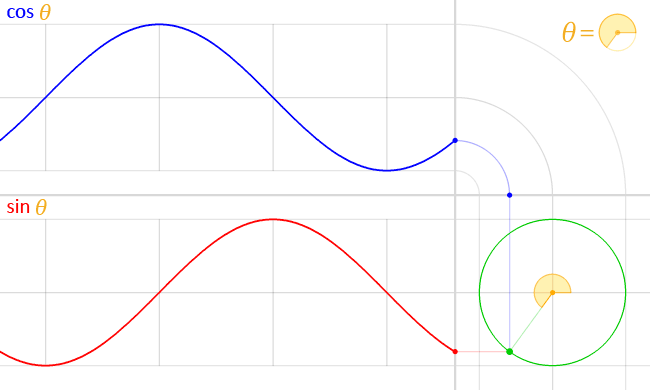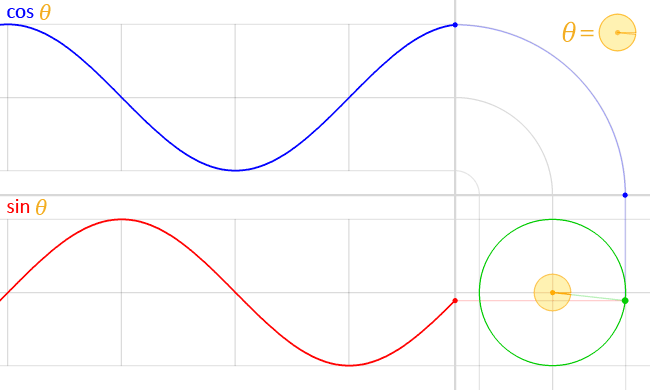
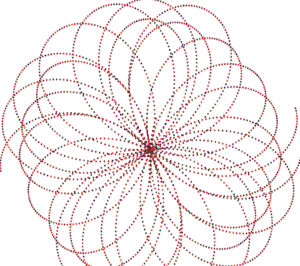
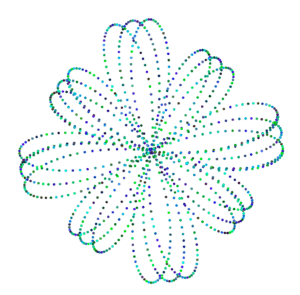
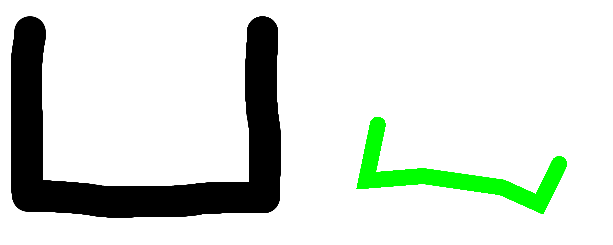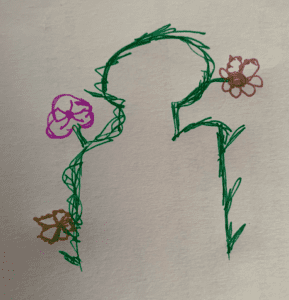I started off knowing what I wanted to build. Thanks to the ideation presentation at the beginning of the semester, I thought of an idea to improve the live music event experience by integrating generative graphics.
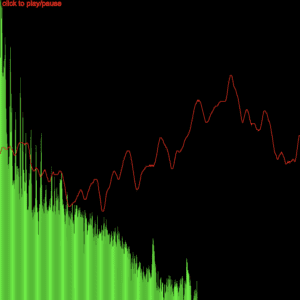
I immediately thought of the machine learning pitch detection model. The graphic we made in class was two dimensional and consists of two parts. The green representing the scale and the red wave displaying the sound waveform.
I recognized a few challenges. First I have to change the input from the computer microphone to an mp3 music file. Second, I have to find multiple ways of inputting information to the generative graphics for it to change according to the music. At last, there is the graphic itself. The first issue was very easy to address with a simple load function. So I spent the majority of my time dealing with the last two issues.
I started off by creating the visuals. Professor moon recommended me to check out WEBGL and the rotating box. After making a simple box and changing the usual 2D p5 canvas to 3D I was quite amazed by the results.
After seeing the effects of 3d in p5 I wanted to explore what else I can do to the graphics. So I searched up some 3D models I can add to the graphics to make it look nicer.
By adding in a human-shaped model and sine graphic, after some adjustments, I was quite happy with the results.
Meanwhile, professor Moon told me to observe the sound waves and see if I can find any patterns. I realized that certain parts of the waves are reactive towards the base and others are more reactive towards the treble. I also realized that vocals make the waves move in an intense fashion. Most of all the peaking of the base is very rhythmic and shows a very consistent pattern.
In my second meeting with professor moon, we created a function that sets a threshold for the value of a certain region of the sound wave that is the most reactive towards the base. Seeing the graphics change according to the music, I was mind blown by the results.
Though the results are noticeable the previous detection method was still not sensitive enough. Then I proposed the possibility of measuring the velocity of the change in the scale. By setting a threshold for the change we were able to achieve a better effect and it is also more compatible with different genres of music.
At last, I made some adjustments to the graphics to math graphics with the bass sounds without having too much going on.
I was so happy with the results I showed it to all my friends and also my parents paired with their preferred type of music. The response was the best for hip hop and EDM music. Mainly because of the style of the graphics.
These are the notes I’ve made from setting goals to new learnings and possibilities after each meeting with professor Moon.
I see myself further developing this project in the future and I also gave this project a name. Project META, Because it sounds cool and comes from the word metamorphosis that resembles change.
Since the majority of the graphics right now are based on the visuals of the actual sound waves, professor moon suggested improving this project by making all the graphics responsive to the actual music itself. I believe taking this advice would take the project to another level and improve my understanding of both code and sound. So I will definitely take this direction. Along with professor Moons suggestion, Tristan also gave very good advice about using lerp to sooth out the graphics.
This is an interactive webpage allow users to interact with images using their faces.
Usage
There are plenty of movements to interact with the image.
Move face forward/backward: Change the scale of the image.
Move face left/right: Change the brightness of the image.
Tilt head: Rotate the image.
Turn head left/right: Switch image.
Nod: Switch image style.
Inspiration
Before midterm, I found that the Style Transfer was really cool, so I decided to do my midterm project with it. However, the project would lack interaction if I only used Style Transfer. Finally I integrated Style Transfer with PoseNet to develop a project with sufficient interaction and cool visual effects.
Typically, people interact with images in websites using mouse and keyboard. With the help of machine learning technology, we can make images reactive. In this project, it seems that images can “see” our faces and change their status based on our faces.
Development
Code Split
To organize my code well, I used TypeScript + parcel to code the project.
TypeScript is superset of JavaScript, it has all features that JavaScript has. Besides, it has static type check, which can prevent a large number of errors before during editing period.
Parcel is a tool to bundle my code. I split my code into different modules during development, but in the end all the code would be bundled into one HTML file, one CSS file, one JS file and some static asset files.
Structure of my source code
Structure of my distribution code
Face
In the project, I used a singleton class Face to detect user interaction.
Basically, it retrieves data from PoseNet every frame to update the position of different facial parts and compute the state of the face.
I used a callback style programming method to trigger functions when users nod or turn their heads.
To prevent image shaking, I set some thresholds. Therefore the image will update only if the difference between two sequential frames exceeds a certain value.
Update Image
I used Style Transfer to add special effects to the image. Other properties of the image, such as size and direction are all implemented by CSS.
Difficulties
At the early stage of this project, I spent a lot of time trying to make Style Transfer work. The biggest problem I had was that Style Transfer never got the correct path of my model resources.
Finally I solved this problem by looking at the source code of ml5.
When we use Style Transfer, we usually pass a relative path of the model as the first parameter. In the source code, I learned that during execution, it will send a HTTP request to get the model. That is the reason why we must use a live server to host the webpage in class.
The previous failure was that the development server treat the path of the resource file as a path of the router, instead of a request to a static file hosted by the server. To solve the problem, I added a .model extension to all model files. In this way, the server will recognize it correctly.
Future Improvement
This project proves the feasibility of making websites interactive by equipping them with machine learning libraries.
In the future, I want to develop some well-functional applications with the same methodology I used in this project.
First:For my midterm project, I got this idea through my final project idea. I have a clear project I want to create that would be too much for the midterm project. So I thought I would do that for the final project. I thought my midterm project could be a foundational step or a preparation for my final project. So I worked on coming up with ideas in this direction.
Since my final project idea is an interactive screen, I did it for my midterm project as well. I did some research online. And was inspired by the Intel RealSense Interactive Wall. While thinking of the particles I would want to use for my project, the first thing that came to my head was fireflies. My roommate has firefly lights in our room and it gives us a cozy and calm feeling. So I decided on creating an interactive screen using fireflies as particles
After the midterm presentation:I realized that my project was a little too simple and the firefly effect did not work out that great. While trying to think of something to do to polish this project, I noticed how the particles I created, that were meant to look like fireflies, reminds me of LED screens. So, I decided to change my idea into creating an LED screen.
Visual elements design:
Firefly particles:
For the firefly particles, to test out if the interaction was working, I first used yellow ellipse to represent the particles. After making sure it was working, I then searched for tutorials online on how to make them glow. I learned a way to make things have a neon glow using CSS. But since I was drawing the particle as ellipse using javascript, I had trouble linking the two together. So I turned to the professor for help. He taught me to add some circles to the outside of the particle and change up the transparency. In the final code, I drew several ellipses with different transparency and blended them together.
Background particles:At first when I was still trying to create the firefly theme, I chose an image from the woods as the background image. But after the midterm presentation, I received some feedback that it would be better to keep the background simple and different so we could see more of the movement of the glowing particles.
So then I got the idea of changing it into an LED screen. I decided to create a glowing background with different colors to contrast from the user’s reflection. In the end, I used the color purple. And to achieve a glowing effect for the background, I used random to make the background” move”.
For the coding of the background particles, I just added ellipse to the background where the user’s body is not detected, in other words, when “data[index] == -1”. For the color code, I noticed that all purple colors have the last value all at 255 with the first two values varying in a certain range. I took advantage of it and used random to change the color randomly yet still in a purple tone.
Interactions design:
For the interaction of the project, besides using body pix to detect the user’s body movement, I wanted to add some other interaction. While I had the idea of making a firefly project, I thought it would be fun to make some sound and the lights will go away. It remained me of a sound-controlled light we have. So while presenting my project at first, I used mic input as a trigger to “turn off” the fireflies. It worked pretty well. So when I changed my idea to an LED screen, I thought it made sense keeping the same interaction method. Because when I created the Led screen, it gave me a feeling as if the user is a rockstar performing on stage with all the light on him/her. And now, when the lights turn off, it’s kind of like the show or performance has ended.
How I code this was to use the mic as input and then set the color of the ellipse fill to change when the sound level is over a certain value.
Obstacles through completing the project:
Designing a completed project: since my midterm project is a foundational step for my final project, my main goal is to get familiar with the use of different models. So I did not have a lot of creative ideas on what complete project I should do. I first came up with the fireflies cause I’ve seen similar projects. But then I had trouble making it complete and fun. I later changed it to the LED screen but still feeling like there’s something missing. This was the main obstacle.
Making the particles glow: I found a way to make the content to create a neon glow through CSS. But since I created the ellipse one by one, it was impossible to change the style of it in p5. After consulting with ima fellow, he taught me to create multiple ellipse layer on top of each other and changing the transparency.
As I was coming up with the project idea, I wanted to make something that I could continuously build on even past the midterm, and stay true to ‘machine learning’ as a core part of the project. I recalled one of the videos we watched early on in the semester where a man spoke a made-up language and they would generate subtitles animated according to his speech pattern. Unfortunately I could not locate the video but this inspired my idea of matching gestures to the English alphabet. After starting the project I quickly realized that this would be hard to accomplish, due to the physical limitations of the body to create shapes that resemble letters. I would have preferred to use leap motion or the kinect to trace the fingers, which would offer more flexibility in terms of representing the characters but I figured it might have been a better idea to stick with poseNet as I hadn’t worked with either leap motion nor kinect for over a year.
The full arc of my project was to include tracing of the arms, saving it as an image, comparing the image to a library of the English characters, and then detecting which one of the letters most closely matched the gesture. This would become a basis for visuals similar to the aforementioned video that inspired me. The letter would appear and would be animated according to either sound or movement, however, in the end I did not manage to add this section.
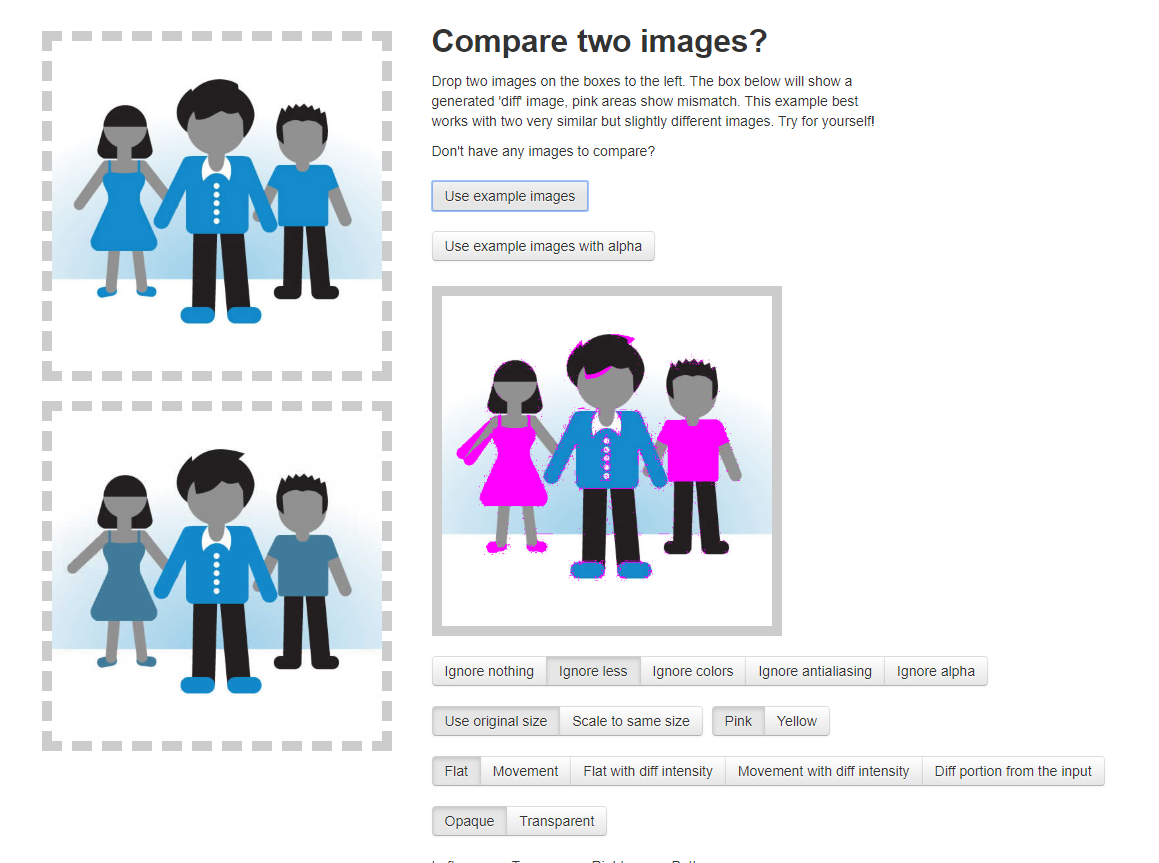
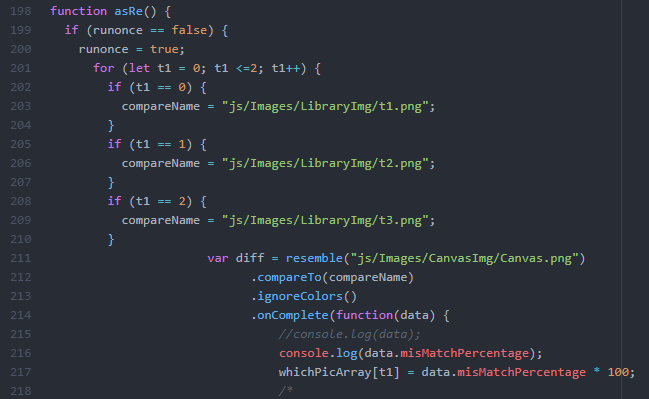
For image comparison I found a library called resemble.js.
Unfortunately, I ran into quite a few problems while using this. They only had one demo that incorporated jQuery, so I needed to take a decent amount of time distinguishing the syntax of jQuery from the library. I also had problem referencing the library as an external script, so I ended up directly copy and pasting it into the main sketch.js which ended up working out.
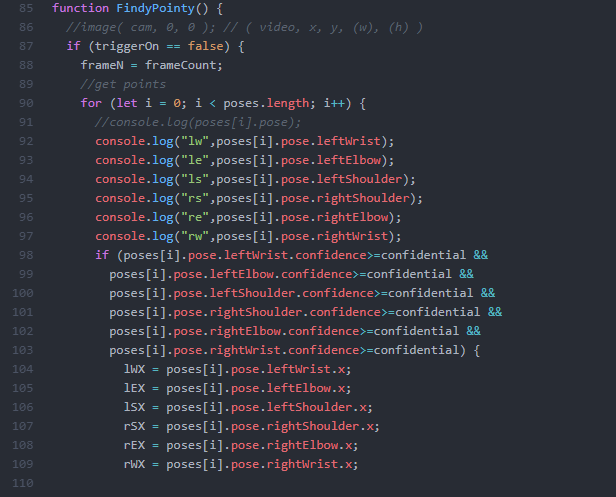
I wanted to create some specific parameters for controlling when and how p5/poseNet detected the arms and dictated when it was time to save the canvas for comparison. Knowing that poseNet has a tendency to ‘stutter,’ I wanted to make sure that it only ran when specifically triggered, and ended with another trigger. I used the confidence markers that poseNet offers in order to dictate this, only starting when all the wrist, elbow, and shoulder points stayed relatively stable with a high confidence level for a certain amount of frames( utilizing two sets of variables tracking the last frame’s positions and the current frame’s),
or resetting when the confidence level of the hands dropped below a certain point (signifying the hands dropping out of frame). Due to the unreliability of the confidence levels fed by poseNet, I had to keep the threshold very low (0.1 out of 1) just so that it could track the arms more reliably, at the cost of this “off” trigger, so I decided to remove it until I could find a better way to trigger the reset.
At this point I realized that I could not count on poseNet tracking reliably enough to distinguish a whole set of 26 different characters from each other, especially with the limitations of how we can move our arms. Instead, I replaced this library with 3 basic images that were generally achievable through poseNet.
Knowing PNGs automatically resize depending on the amount of empty space, I made sure to keep everything as that file type, so that no matter what part of the canvas your body took up with poseNet, it’ll automatically center crop out the sides so that the image sizes can match better.
Ex.
The peak of my hardship came after I managed to figure out the individual steps of the project and began to integrate them with each other. While P5 has the ability to save the canvas, I needed it to be able to replace an existing image with the same name. I came to realize that this was only possible using a html5 canvas, while p5 would just keep saving with a sequence number after (eg. CanvasImg(1).png). I had largely forgotten how to utilize the workflow between html and javascript, so I decided to keep using P5 out of time constraints, but this would mean that I would need to manually delete the saved Canvas image each time I wanted to make a new comparison. Another problem was that in order to register the saved images, atom live server had to reload, which would restart the pose detection. Luckily, loadImage() has a two extra parameters, a success callback function, and a fail callback function. I turned the two segments of the project into functions,
ran through the single call to load the saved canvas image.
In order to run the function that calculates the resemblance of the two images, you would need to reload the page. I never figured out why that is.
I ended up hard coding the call for the three images in the library but I had plans to use for loops in order to run through folders categorizing the different shapes from each other, then append saved canvas images to their corresponding categories, allowing the library to expand therefore ‘training’ the model. While I may have had a much easier time not downloading and uploading images, I wanted to keep it this way as a strong base for further development, since I wanted this library to permanently expand, rather than resetting to the base library each time I reran the code.
I wanted to have generative art that mimicked the step by step creation of the henna designs.
Inspiration:
So growing up, a lot of the women in my family on my father’s side got diagnosed with cancer. My aunt nearly died of cervical cancer when I was eight. My cousin was in and out of remission for stomach and liver cancer from the time I was about seven till I was fifteen when she ultimately passed away. The four year anniversary of my cousin Judit’s death was September 28th, so I had been thinking of her a lot prior to the midterm. When it came to creating something for the class, I knew I wanted to do something that honored her and sort of helped me work through what I was feeling.
Project Inspiration (that awesome lady to my left)
Sure, there is risk in doing something deeply personal. But it also helps you understand the level of interaction and helps you make it tailored to your target audience.
Background:
The ultimate goal (probably achievable by the time finals roll around)
So, ideally I want to use ml5 to find the edge of a person’s head and then draw flowers that generate on that edge… now I think realistically it would make sense to generate some of those vines around the edge, just to make the image look less pixelated around the edge. So outline of the person is vines.. then at the end of these vines there is a flower that is made out of dots and kind of mimics the henna dot designs.
Vine and Floral Ideal
Please excuse my drawing ability. But essentially this is what I want the final to look like in some capacity. I’ll show how close to this I got in the midterm and also explain the critiques and what I hope to accomplish for the final.
The Process:
This plan… didn’t include a ton of other steps that popped up as a result of this steps..
Using BodyPix or UNET find the edge
Count the pixel area of the body
Average the pixels to find the midpoint, so that the vines are all relative to the midpoint.
Draw all of the flowers and the vines in p5
Place the p5 elements in the ml5 sketch
Have the vine draw first
Add the flowers to the endpoint of the vine
Celebrate because this seems feasible in one week!
Step 1: BODYPIX OR UNET
BodyPix– “Bodypix is an open-source machine learning model which allows for person and body-part segmentation in the browser with TensorFlow.js. In computer vision, image segmentation refers to the technique of grouping pixels in an image into semantic areas typically to locate objects and boundaries. The BodyPix model is trained to do this for a person and twenty-four body parts (parts such as the left hand, front right lower leg, or back torso). In other words, BodyPix can classify the pixels of an image into two categories: 1) pixels that represent a person and 2) pixels that represent background. It can further classify pixels representing a person into any one of twenty-four body parts.” (ml5js.org)
UNET– “The U-Net is a convolutional neural network that was developed for biomedical image segmentation at the Computer Science Department of the University of Freiburg, Germany.[1] The network is based on the fully convolutional network [2] and its architecture was modified and extended to work with fewer training images and to yield more precise segmentations. “(ml5js.org)
So… I was going off of these definitions (that’s why I put them above)… it made more sense to use BodyPix since that’s a) what I used for my last coding homework, b) seems like it would be better at finding the overall area (I’m not looking for individual parts… which seems to be what UNET is tailored to do). Moon also agreed that BodyPix was better… at first I thought maybe it would be worth to do both in order to make the output outline of the person less pixelated, but if I am covering the edge up with a vine later anyway, do I really need UNET? I decided I didn’t and moved forward with BodyPix.
Step 2+3: BODYPIX CALCULATIONS
Segment does not mean Segment with Parts
What does it mean to segment? Segment means you are looking for the body outline itself, so not the individual arm, face, etc.
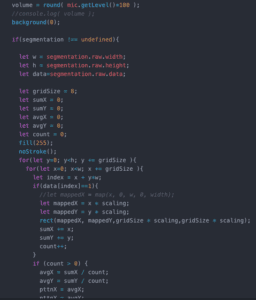
Drawing the actual gird size and scaling it… the scaling ruined everything
It looked great… up until it was scaled, then I had these big ugly square edges, but at the time I thought, eh not a big deal since I’m covering this with a vine. But the image had to be bigger, so I had to do what I did.
Step 4: DRAWING FLOWERS + VINES
Throwback to Calculus
My favorite part of Calculus is not doing Calculus. But of course, flowers are circular, therefore it was time to revisit the Unit Circle. Below I’ll link all of the raw p5 code so you can see that the variation really come from adjusting the angles at which the sketch starts and ends.
The key difference between the vine and the other flowers is the mention of “noise” in the vine code. This means that the vine is different nearly every time you run the sketch and allows for a more organic, not nearly as neat and arced style as the flower have.
As I was admiring the vine, I realized it would be interesting to have it become sort of a necklace. I remember that one of the issues my cousin was facing towards the end of her life was shortness of breath, I thought maybe placing the vine there would be symbolic. This meant I wasn’t going to actually draw the vines around the body.
Now, a note on how to draw these graphics. This is apart of the create grpahics/PGraphics method present in both p5 and processing. Now the point of doing this… is the whole pixelated body outline is on the bottom most layer of the sketch. In this case, I drew another layer on top of this with the vine and the flowers. This method makes it possible to clear the sketch… this is a functionality I will explain in a little bit. The only thing that’s very odd still about this whole PGraphics thing is the fact that the canvas for that has to be large, and actually larger than the video output itself in this case. (This is another reason why I had to scale up the video and make the background pixelated)
STEP 5+6+7: PLACING ELEMENTS INTO THE ML5 SKETCH
Individualized FrameCounts for All!
So, it became apparent that using just plain frame count was going to be a problem. The issue was the flowers and vines couldn’t be drawn forever because that would eventually just yield a circle. So I was using frame count to control how many times the sketch would run. The issue was because the vine and the flowers were using frame count too, the sketch would stop before the flower reached maturity. This seemed to fix the issue almost completely.
The vine was in a function completely independent from the flower drawing function which took the ending point of the vine as an input.
STEP 8 + 9: BETTER USER EXPERIENCE WITH PAGE CLEARING + VOICE CONTROL
New Flower Draws When I Clear it OutNew Flower Draws When I Clear it OutClearing ItNew Start
So I was thinking about how to clear the sketch as painlessly as possible. To me it made sense to clear it if there wasn’t enough of a person in the camera field. That’s exactly what I did with pixel counting, setting a reasonable threshold to clear the vine and the flowers, an example of which can be seen above.
When it came to growing the vine, it made sense considering the user has the vine positioned around the neck that speech, specifically volume controls the growth of the vine. Almost like this idea, that the more you struggle the worse it gets… this is also something that is possible for cancer patients to use even because it doesn’t require significant effort like movement would.
STEP 10: ACTUALLY CELEBRATING (BUT CRITIQUING MY WORK)
So what’s wrong with my project? Many things. I think I want to rework the vines to work around the outline and then have the background and the filling of the body be the same color.
The style just isn’t the same
The other issue is that I didn’t like the sizing of the graphics, but if I changed the size of the dots or the sketch it would have taken down the quality several notches, which was a clear design aspect I wanted to maintain. It just felt very… elementary and not as delicate as henna is.
So if I work through the issues with resizing then I think the vine issue is resolvable as well, but that goes back into fixing all of the frame count issues for the vine all over again.
The other critique I got related to this idea that my project was not… “fun” enough, which I really don’t want it to turn into a Snapchat filter, or something as superficial as a photo like that. I really want to be focused on this idea of positive growth coming out of decay. I see this as a more serious piece. Then again I’m a really serious person. Maybe I’ll make the colors a little more fun, but I really still want the detail and the beauty… the delicacy almost to remain as I keep working on this project.





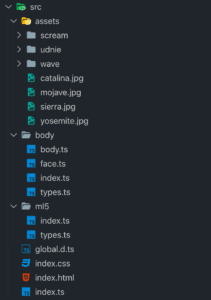 Structure of my source code
Structure of my source code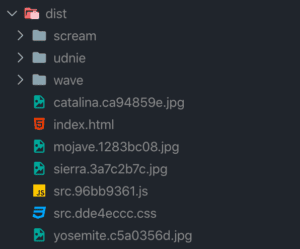 Structure of my distribution code
Structure of my distribution code For my midterm project, I got this idea through my final project idea. I have a clear project I want to create that would be too much for the midterm project. So I thought I would do that for the final project. I thought my midterm project could be a foundational step or a preparation for my final project. So I worked on coming up with ideas in this direction.
For my midterm project, I got this idea through my final project idea. I have a clear project I want to create that would be too much for the midterm project. So I thought I would do that for the final project. I thought my midterm project could be a foundational step or a preparation for my final project. So I worked on coming up with ideas in this direction.
 After the midterm presentation:
After the midterm presentation:
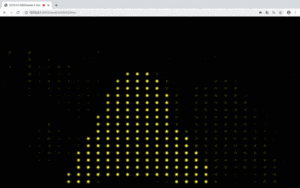

 I decided to create a glowing background with different colors to contrast from the user’s reflection. In the end, I used the color purple. And to achieve a glowing effect for the background, I used random to make the background” move”.
I decided to create a glowing background with different colors to contrast from the user’s reflection. In the end, I used the color purple. And to achieve a glowing effect for the background, I used random to make the background” move”.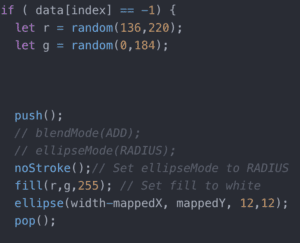 I just added ellipse to the background where the user’s body is not detected, in other words, when “data[index] == -1”. For the color code, I noticed that all purple colors have the last value all at 255 with the first two values varying in a certain range. I took advantage of it and used random to change the color randomly yet still in a purple tone.
I just added ellipse to the background where the user’s body is not detected, in other words, when “data[index] == -1”. For the color code, I noticed that all purple colors have the last value all at 255 with the first two values varying in a certain range. I took advantage of it and used random to change the color randomly yet still in a purple tone.