For my project, I used the KNN we made in class and combined it with randomly appearing squares that would disappear when you went back into place.
I copied some of the code I used from the poseNet and Object Creation work that we had done to make the squares. When the picture is close enough to the original the squares will disappear.
Initially, I wanted to make ellipses pop out of the bottom like confetti or fireworks, but the camera image kept covering it up. I think if I made the squares/rect smaller and more rectangular I could create that confetti feel.
The mechanism of this game is intuitive: users are asked to control the traffic light by clicking their mouse so that the car from different directions won’t bump with each other when passing through the intersection.
My project
So my expectation is to create a traffic light controller project implementing the concept of KNN Classification. By recognizing input gestures, the traffic light can be changed accordingly. Understand the KNN classification mechanism is definitely not easy, I did some experiments before creating my own project but still had a hard time manipulating the code. I reached out to my friend Wei and she had helped me a lot.
Input: real-time camera image
Neurons: three pre-loaded snapshots representing the three traffic lights. The snapshots are recorded in an array after pressing three specific keys on the keyboard.
Interface: the traffic light drew using p5
I had encountered some problems regarding using the result and triggering the expected effect. As I have three neurons, I was a little bit confused by how to call each of them out. I will solve this problem as soon as and improve the interface as well.
For my project, I decided to use the KNNClassification_PoseNet code Professor Moon sent to us in order to make text responsive to the distance between your face and the camera. I was inspired by my parents, who whenever I show them things on my phone, they have to move their faces further/closer to see what I show them.
The way my project works is that I have two different font-sized sentences. Below the sentences are buttons that the user clicks to gather samples on how close/far their face needs to be in order to read that font size. After they gather the samples, the user clicks a button that says “start reading” and then part of the first chapter of the first book of Harry Potter shows up. The font size changes based on the distance between the users face and camera that was gathered from the previous samples.
Process
There was definitely a learning curve with understanding how the code works at first. I had to analyze how each function was triggered and where the data was being gathered/reset. But after looking at the code for a while, I was able to understand. I dealt with a lot of css for this assignment because I wanted to organize the page more neatly so that the reading and steps would feel more intuitive to users. I also included bootstrap to move the first two buttons into two columns. In the script, it was mostly just using document.getElementById(“”).style.fontSize to change the font size. The rest was fairly simple.
Final Thoughts
My intial goal for this assignment was to make an interface that allows people to adjust the text to their eyesight. I think if I were to work more on this project, I would make the font size changes feel smoother. Right now, they just abruptly change between the face distance changes. I would also probably add images and change the sizes. Aside from that, I would probably just make the interface look neater and more professional.
I rode the metro with two ladies speaking sign language. I barely know enough Chinese to function, let alone Chinese Sign Language. So I did some research!
Semi-WorkingSemi-WorkingSemi-Working
Turns out, just like China has many Chinese dialects, they have more than one sing language. Chinese sign language is split into North and South. Northern Chinese Sign Language is based off of American sign language, and Southern Chinese Sign Language is based off of French sign language.
Since we live in Shanghai, in this case I am looking at Southern Chinese Sign language. I trained 20 different hand gestures basically using the Rock,Paper, Scissors base KNN.
It kind of works? I works for one iteration and then stops. So I think this is because I have too many buttons but I cannot be sure! It’s okay! It is progress. At least the recognition is very accurate.
It worked with the three buttons. I didn’t change any of the code other than adding additional buttons. Because I can’t get the confidence to work it is harder to get additional interface things to work. I am hoping to get the issues sorted out as soon as possible.
Once those issues are sorted I will come back to this post and adjust with the final product. This issue with the code seems to be common. I want to see why it happens, as adding additional buttons seems rather straightforward.
UPDATE
My Lovely Interface
So, upon meeting with Moon, I worked through the issue, discovering that the broken HTML was due to a single spelling error in terms of confidence detection with one of the signs. I subsequently fixed it and retrained the entire data set, with about… 100+ examples each. Some signs work standing up, others work sitting.
I worked on some simple CSS to make the interaction clear, in this way it makes it less cluttered as well. The emojis are meant to be hints, and the detection is meant to show people that their actions, their hand gestures have meaning.
I was going to add a guessing element… to have a randomized emoji appear, but I thought the learning part of this should happen with the video I included above. This is more just to practice different signs.
That is something I would further improve if I were to make this into an actual project beyond just a homework.
Demo (there’s music so please turn on your speaker):
Concept:
This week we are assigned to build an interface utilizing KNN Classification. I was messing around with the example code provided by the professor and found using video as input very interesting. I followed the codes and developed a themed webpage for children to play with. A lot of children are interested in superheroes, they often imitate their gestures and movements. Thinking of that, I chose six difference superheroes from Marvel and DC to be my characters. They’re Superman, Iron Man, Batman, Spiderman, the Hulk, and Captain America.
Design:
These superheroes all have a signature pose where people could instantly think of. Using that, I recorded these movements and poses into the dataset, and loaded into the webpage. All of the poses I recorded are similar to the ones shown in the picture, so people could easily figure out what poses could trigger each character when they are messing around.
Since I added more class to the code, the webpage was too long to show the webcam and the “Confidence in …” text for every character at the same time. To make it more clear of which superhero was the user’s movement classified as, I added a div to show the image of the character being triggers.
All of the pictures I chose for each character are from the cartoon or the original comic design. To match the aesthetic, I chose the theme song from the tv show or cartoon, where most of them are produces in the 1960s, to be played whenever the character comes up.
Code:
I used the example code from class, KNNClassification_video to train and get the dataset. Then I changed the layout for each class using HTML.
To add the audio, I first added the source audio in HTML and gave it an id, then I called it in Javascript.
To appear the corresponding image under the webcam, I added a div in HTML, styled it in CSS, and changed the image in Javascript by changing its source image.
Difficulties:
I was trying to let it appear gifs from modern-day films of the superhero under the webcam, but it wasn’t working that well. The gif froze and slowed down the entire site. I think it might be because it was unable to process that much at the same time.
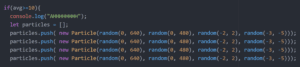




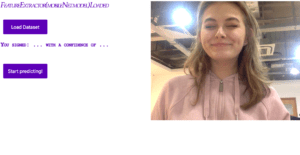

 Since I added more class to the code, the webpage was too long to show the webcam and the “Confidence in …” text for every character at the same time. To make it more clear of which superhero was the user’s movement classified as, I added a div to show the image of the character being triggers.
Since I added more class to the code, the webpage was too long to show the webcam and the “Confidence in …” text for every character at the same time. To make it more clear of which superhero was the user’s movement classified as, I added a div to show the image of the character being triggers.
