For my final project, I will keep working on the my midterm project: the immersive museum viewer.
There are mainly four parts in my final project:
First of all, I will change the method of calculating the coordinate. Instead of using one variable, I will employ the vector which will indicated the angle of face and the ratio of the distance between two eyes and the nose.
Secondly, I will add an distance sensor. The mechanism is to use the poseNet detect the distance between the user’s left and right eye. When the user move close to the camera, the distance increase, and then the background image will amplify and vice versa.
Thirdly, I will add the audio guide and background music when the user navigate in the scene.
Finally, there will be some interaction point. For example, when the user points at the thing, the introduction will jump out.
The aim of my project is to create a complete immersive and keyboard free experience for the users.
For my final, I wanted to improve on my midterm to make it more similar to what I originally wanted. When I was working on my final, I wasn’t able to treat letters like particles and got stuck, but now, with more time and knowledge I think I will be able to.
While letters falling out of my ears to me represents the loss of information, I want to make something that is more up to interpretation since I think there are lots of meanings that could be pulled from it depending on how I execute it.
I went to a workshop held by Konrad. At first, I really wasn’t sure what I wanted to do for my final. It’s one thing to say, “Oh, I’ll just continue to work on my midterm”, but in practice it doesn’t always work like that.
I was disappointed with my midterm, it wasn’t nearly as polished as I wanted it to be when it came to presenting it. I think after that project, quite honestly I am in a creative slump with little motivation to do anything. When it comes to this class… I couldn’t think of anything I really felt connected to, or motivated even to explore for a final.
I knew what I wanted to do for CDV and AI ARTS almost instantly… and this final for whatever reason is just not coming to me. The closest I have come to inspiration is this new form of floral art.
It felt more delicate, more me. I think I just need to rework my midterm completely. Maybe these floral creations are on joint points, accessible through PoseNet… I like the idea of a completely white background and maybe sound input changes the hue of the florals. I feel like I need to use KNN to get top marks, but it doesn’t make sense to use it unless I am changing the florals’ hue based on pose.
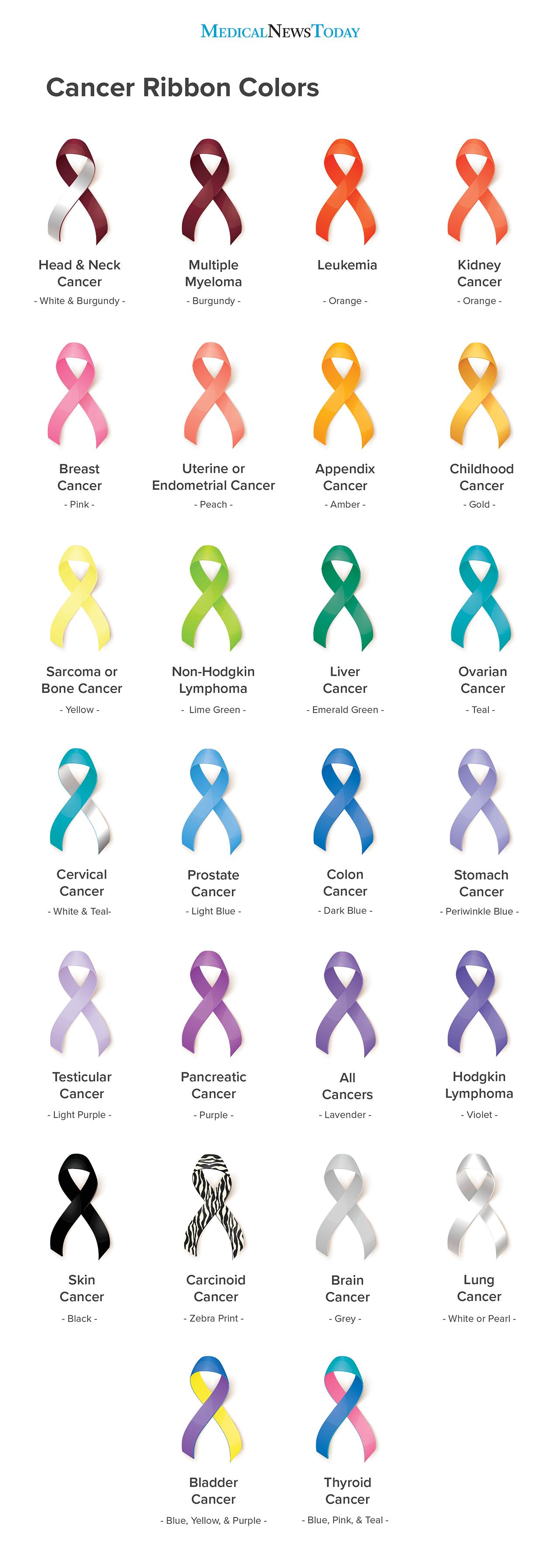
The poses could correlate to something… secret. I had done my KNN homework, semi-successfully on Southern Chinese Sign Language. What if certain poses… correlated to cancer ribbons. (Way to go Eszter, another morbid topic!). It’s subtle. As you can see, the design I have right now has the vibe of water color flowers.
Cancer Ribbons
You practically have the entire rainbow here. The project can just be a case of practicing anatomy and training a rather complex KNN. It’s just a delicate education tool. I could print little cards with this same information, I know the school prints business cards, why not print the ribbons on it too, just as a small reminder.
At the end of the day, I want to create something really beautiful and delicate, still based off my midterm, but more polished. The last thing I want is for anyone to think of this as just another snapchat filter. I don’t want to target my work at children, I really want to target this project for users that are older, looking for a more refined way to educate.
(What you see above, is my entire thought process trying to develop this idea. I literally had no idea what I wanted to do when I sat down to write this post. Amazing how looking through my p5 library and thinking through my past assignments changed that).
A couple of months ago, while I was browsing through the internet, I saw this video on Youtube.
Disney has had such a big influence on me as I grew up. And I’m sure it’s the same with a lot of people. This project has brought joy to the passengers and that’s what I want my projects to achieve. At the end of the video, it reveals that it’s actually people in costumes acting behind the screen. But while we were learning PoseNet in class, I thought it would be possible to use the knowledge I’ve learned in this class to recreate an actual program interactive version of this project. So I’ve decided to give it a shot for my final project.
Project Idea:
For my own version of this project, I’m creating a program that will detect the user’s body movement and link it to Disney characters. The output is presenting the character’s shadow triggered by the movement. My project is called, “Have a Magical Day”.
The main model I will be using for this project is PoseNet. I will use it to detect the user’s body movement and link the points to the Disney character’s body points. I originally wanted to design different stages for the program, where the character will stop detecting when the user stops walking. But I think it will complicate the program and I want the users to move as much as they can to discover the program and the characters on their own. So I decided to keep it a simple detection of the user’s body and “cover” the shadow onto it.
The Characters:
Since I’ve decided to draw the character’s shadows on my own, it would be a lot of work if I chose I lot of characters. I chose all these characters following two rules. First, it has to be human-like, meaning it walks like a human, so I ruled out characters like Dumbo and Simba. Second, it has to be iconic, meaning most people would recognize this character through only its shadow. So I finalized the following ones in the end. Elsa, Olaf, Tinker Bell, Donald Duck, Mickey Mouse, and Minnie Mouse.
Another element I thought of when I was designing these characters was the gender of these characters. In the original project, the performers knew the user’s gender so they chose characters that matched. I originally wanted to add some type of classification program to my project so it could detect. But I thought it wouldn’t make sense that users only could interact with characters of the same gender. So I would keep it random on which character would appear.
For my final project, I was thinking of creating an interactive website where users can learn yoga themselves and have a greater appreciation for the practice of it. Essentially, users can choose from several images of yoga poses and try to imitate them. Based on how accurate their poses are, parts of their environment will change to match the pose name. If their pose is completely accurate, they themselves will become the animal/object the pose is named after.
For example, “downwards dog” is a famous yoga pose. If a users pose is 50% accurate, perhaps only the background image on the web screen will become a backyard, but at 100% accurate, the user will become a downwards facing dog.
Inspiration
I was inspired by both the names of certain yoga poses and by one of my favorite childhood Wii games, WarioWare Smooth Moves. I always found the names of certain yoga poses really interesting/amusing, such as “downwards dog”, “cat”, etc. and always wondered if these poses were actually similar to the animals/objects they were named after. As for the Wii game, there is a part in the game where players have to follow designated poses in order to earn a point. The game is typically fast paced but there are random “yoga” poses that are thrown in to give users a break. Here is a link to a game play to understand (skip to 3:30).
Developing the Project
Yoga comes from India, which is a country that heavily believes in Hinduism. After looking into Hinduism, it really values nature and respects it which is why I want to make users grow their appreciation and understanding of the poses. Because yoga is often very calm and spiritual, I want to try and keep the environment/user changes serene and very nature-like.
Technically speaking, I would like to follow the code that Professor Moon provided our class, which uses the KNN classification, mobileNet, and webcame iamges. This means that I’m going to need to gather a database of images of people’s poses for the yoga poses. Because my project would involve a lot of body movement, I realized it would be difficult for users to capture an image of themselves without breaking the pose. So, I will also try to incorporate voice recognition to trigger a image capture. Aside from the KNN classification, mobileNet, and voice recognition, I think the remainder of the project will just be very css heavy.


 Since I’ve decided to draw the character’s shadows on my own, it would be a lot of work if I chose I lot of characters. I chose all these characters following two rules. First, it has to be human-like, meaning it walks like a human, so I ruled out characters like Dumbo and Simba. Second, it has to be iconic, meaning most people would recognize this character through only its shadow. So I finalized the following ones in the end. Elsa, Olaf, Tinker Bell, Donald Duck, Mickey Mouse, and Minnie Mouse.
Since I’ve decided to draw the character’s shadows on my own, it would be a lot of work if I chose I lot of characters. I chose all these characters following two rules. First, it has to be human-like, meaning it walks like a human, so I ruled out characters like Dumbo and Simba. Second, it has to be iconic, meaning most people would recognize this character through only its shadow. So I finalized the following ones in the end. Elsa, Olaf, Tinker Bell, Donald Duck, Mickey Mouse, and Minnie Mouse. 


