For my final project, I wanted to create an interactive yoga teaching application for people unfamiliar with yoga. The project layout was that users had to choose from 6 different images of yoga poses, and guess which of those poses matched the background on the screen and the pose name at the bottom. Users were able to pick from either cobra, tree, chair, corpse, downwards dog, and cat pose.
The goal of my project was to not only get users to draw the connection between the yoga pose name and the animal/object it was named after, but also feel immersed in the natural environment that these poses are typically found in.
Inspiration
I was thinking of games and body movement/positions, and remembered one of my favorite childhood games, WarioWare Smooth Moves. One of the moments that stuck the most with me in the game, was the pose imitation levels. The point of the game was to complete simple tasks within 3 seconds. It very easily got stressful and fast-paced, so the random “Let’s Pose” breaks where gamers had to simply follow the pose on the screen was peaceful. Thus, the idea came to me where I wanted people to also do yoga poses.
As I was doing research on what poses I could incorporate into my project, I found it interesting that all the poses were named after objects, animals, etc. As I looked into it more, I found that one of yoga’s main principles is to really embrace nature and the environment you’re in. This point of information, in addition to enjoying my midterm project immersive environment, was what made me want to make users feel immersed in the environment and truly understand the context in which these poses were named after. Continue reading “MLNI Final Project – Jessica Chon”
The main inspiration for my project is a video I saw. It’s an “interactive” wall where the silhouette of Disney characters will be imprinted on people passing by.
First I thought this was an interactive project where the silhouette was generated by some kind of programming. I was amazed by how vivid the visuals looked. But in the end, they revealed that it was actually performers in Disney costumes dancing behind the wall. To be honest, I was a little disappointed.
While we were learning Posenet and movement detection in class, it reminded me of this project. And I thought, why don’t I create a “smart” version of this project for my final? So that’s when I decided my final project for this class would be, an interactive program that would generate Disney characters’ features onto the user’s bodies.
The choosing of the characters
The first step to start off this project was to choose the characters I would use for my project. I kept two things in mind while I researched on what characters I should use. First, it should be human-like, as in they would use two legs to walk. It would be hard to shadow a human with Bambi features. Second, since I am using partial features, I need the character to be noticeable and well-known. So for people who aren’t that familiar with Disney, they might still know which character it is. So based on these standards, I narrowed my options to five characters. They are Mickey Mouse, Minnie Mouse, Baymax, Tinker Bell and Elsa.
Visual Elements Design
I had an idea o the visual and animation design of each and every character. For Mickey and Minnie, the ears, the gloves, and the shorts/skirt are the most important features. For Baymax, basically the entire outline of his body. For Tinker Bell, it would be the wings, And for Elsa, it’s the magic power she has to snow and the long dress that identifies her. With these features in mind, I started off with creating the still visual elements first.
Still image visual elements
I thought it would authentic if I just draw all the character features using p5.js. So here is the first version of the Mickey and Minnie ear I drew in p5. I used ellipse and curveVertex to draw these two graphics. When I combined it with Posenet, it turns out it was slowing down the detection.
Professor Moon then suggested that it would be better if I just use already existing PNG images for all the still visual parts. So I took his advice and searched online for images of all these characters. At first, I was searching for images of the exact front of the character and tried to use it as a whole. But it turned out to be dull and too much. Then I thought I would cut out parts of the character that would represent the feature. And then just leave the rest of the parts to show the user’s own body. With this thought in mind, I started cutting up all the features for the characters. In the end, these are all the still images I used for visuals.
In between, I did try to add other still images into the visual elements. For example, I tried to add shoes for Mickey and Minnie, I tried to add the long dress for Elsa, and I tried to use the entire silhouette of Baymax (not having the two arms separate). But I ultimately didn’t use them because it was not well inserted and messed up the visuals.
Another still visual I added was the red nose for Mickey and Minnie. It was a surprise addition. I originally used the red ellipse to mark the nose position while using Posenet. While I was meeting up with Professor Moon, he suggested that it would be great if I actually keep the red nose, looking like Rudolf. I also received well feedback on the red nose while others played with my project. So I kept it. And even though it’s not really related to the character, since Mickey and Minnie do have a nose tip, and it would be hard to show it when the user is facing front, this ellipse adds on. It fits perfectly!
Animation visual elements
After I’ve solved all the problems I had with still images, I started designing the animation for each and every character. The original idea I had was to only have the animation for Elsa, for her magic powers. So I started off with that.
– Elsa’s magic powers
While designing the animation for Elsa, I rewatched the clip from the music video “Let it go” where she uses her powers several times. There were a lot of things going on when she uses her magic. I decided to simplify it. While doing some research online, I saw a code from the p5.js example library, called Snowflake. I thought it would be perfect for this animation. So I started to switch the position of the snowflakes falling according to the mouse position. Then I remembered Eszter drew a lot of rotating lines for her midterm project. So I asked her how she did those and took it as inspiration to also add some rotating strokes to the animation. And then I got my first version of the Elsa animation.
But I still think that there’s something missing for this animation. I rewatched the music video and noticed that there’re snowflakes being created every single time she does magic. So I did some research some more and found this video created by The Coding Train on Youtube, where they used processing to draw a snowflake. I followed his tutorial and completed a drawing snowflake in p5.js. Then I tried to add it with the previous version of the animation. But for some reason, the rotating strokes could not be combined together with everything else. In the end, I only kept the snowing particles and the drawing snowflake. For the final version, the snow will fall down based on the wrist position on one side, and the other side of the wrist will first draw the snowflake, and then fall snow.
– Mickey and Minnie’s glove rotation
I was only to add animation for Elsa. But while meeting up with Professor Moon, he suggested that it would be great if the glove of Mickey and Minnie will rotate based on the direction the user is waving their hand. He also said I could try using it based on the angle between the position of the wrist and the elbow. I thought it was wonderful advice. So I added the elbow as a key point to detect. Then I researched online on how should I calculate the angle between and relate to the angle the image is rotating. I first developed a code for a square to rotate based on the mouse movement angle. And then I tried to transfer it using the Posenet key points. It worked. Then I tried to adjust the image to rotate with the angle. But since the image’s size was weird. It was difficult to find an exact calculation that worked exactly well with the hand rotating. I tried using sine, cos, and tan to calculate. And I tried mapping it. After several times of retrying and adjusting, I finally fount a similar result for the calculation to match. In the end, I just applied this glove rotate animation to both hands for the Mickey and Minnie character.
– Baymax’s arm rotation
After designing the glove rotate for Mickey and Minnie, I thought, why not add some animation to all the characters? So when it comes to Baymax, I thought I would apply the similar glove rotating animation to his arms. Before, I said I was going to use the entire outline of Baymx. But it turned to be too stiff and dull. And since I’m thinking about adding this animation, I cut off both of his arms and made them into separate images. And I applied the similar code for the glove rotate to the arm rotate. Of course, it did take me a lot of time to adjust it and trying to find the perfect mathematic calculation to match the angle between the user’s shoulder and wrist. But It sort of worked in the end.
– Tinker Bell’s floating sparkles
Now, everybody besides Tinker Bell they all have some kind of animation with them. I thought I would find a suitable animation for her too. I googled some images of Tinker Bell in her movies. I noticed that she has magic sparkling particles glowing around her when she flys. So I thought I would add this as an animation for her character. To achieve the floating particle effect, I first created a code to add random ellipse floating in a certain area. in p5.js. Then I added it with the wings I have for Tinker Bell. To achieve the glowing effect for the particles, I used the code I have for my midterm project, which is basically layering ellipses with increasing radius and blend them together. I did try to make the particle move according to the wings position detected through Posenet. But for some reason, every time I tried to add it, it breaks down. So I just settled for it to have a certain area for the particles to float.
Camera filter visual element
When I first started the project, I know I wanted to still show the shadow of the user instead of having a colorful image. I first thought of using BodyPix. But that would slow down the Posenet detection. Then Professor Moon suggested that I could try using filters to adjust it making it look like only the shadow is showing. I first explored with the filter function. Then Professor suggested that I could explore with image pixelation, which is a much better way. I used the white wall in room 818 to adjust the filter several times until I got the exact filter I wanted. During the IMA Show, another professor said that the esthetics of the filter combines with the Disney characters actually reminded her of Banksy‘s style of art.
During coding
The use of Posenet
The machine learning I’m using for my final project is Posenet. The most use I get out of it is to detect the key points of the user. In order to complete all the characters, I detect several key points of the user’s body. It’s easy to detect, it’s difficult to make it work fast and stop glitching so easily. When I tried just the standard coding of Posenet myself, it was not stable and the detection was oftentimes incorrect. So I met with Professor Moon again to discuss what’s a better way to improve the code. And he introduced me to using three separate functions “create vector( )”, “map position( )” and “update position( )”. While using these three functions to update the coordinates of the key points, it fastens the detection making it running normally even added several draw functions.
After I use the function to fasten it, the next step was to stabilize it. Since I am inserting images based on the key points detected, it glitched moves wiggling like crazy when there is any distraction in the camera. Then Professor again helped me with a function called lerp. This function will smooth the action when an image is trying to get from one point to another. So I used this function several times with one point and it does smooth the flow of all the images movement.
Scale
The project basically realizes the vision I have for it. But I wanted to perfect it more. I decided to add a scale function to all the character’s features, where the images would increase or decrease according to the distance between the user and the camera. To do this, I used the detection of the distance between the two shoulders of the user. Then through console logging the distance, I tried to take a few groups of numbers and figure out the math relations between them. I did this scaling function for the features of Mickey, Minnie, Baymax and Tinker Bell. For Elsa, since it’s all animation, I didn’t apply this function to her features.
Switch modes
I first completed all five character’s filters separately in five javascript files. Then there’s the question of how am I supposed to mix them into one project. I considered using KNN, but I didn’t want to make it into a guessing game. So again, Professor Moon helped me by introducing the function of switching modes. Basically I do this in the draw function, I have a variable called “mode”, and by using keypress to change the number of the mode, it will trigger different functions. When the professor demonstrated it, he used keypress. I did consider switching it to changing the filter according to time increase, but I really want the user to explore the character they like as much as possible. But according to the IMA Show, it didn’t really work well with the keypress. So I might improve it in the future.
Webpage layout and music
Originally, I had an image of the Disney castle as a background image for the background. But before the IMA Show, I think it doesn’t really match with the filter and art esthetic. So I then switched the background into all white. I like it more this way, fewer distractions.
For the background music, I added a piano version of “When You Wish Upon a Star” by Jon Sarta. I think the light and calming music matches the general vibe of the project.
Future improvements
Multiple users are able to be detected and added features in the same shot.
Auto-switch between character.
Adding more characters.
Hopefully adjusting the detection to be more stabilized.
Making the glowing particles follow Tinker Bell’s wings.
Perfecting the animation.
Special thanks to:
Professor Moon! Thanks to all the help Professor Moon gave me during the development of this project, for staying really late in the lab helping all of us with our work, and for the fried chicken. I’ve truly learned so much by completing this project. Thank you so much!
All my friends and classmates who helped me train the detection of Posenet and record the video demo.
All the user’s who tried out my project at the IMA Show and gave feedback. It truly made my day.
Nowadays, in society, people are always being controlled by the outside world, acting against their wishes. Some who tired of being cooped up struggled to free themselves from the control, but finally accepted their fate and submit to the pressure. Inspired by the wooden marionette, we came up with the idea of simulating this situation in a funny way using a physical puppet and machine learning model (bodyPix and poseNet).
Development
1. Stage 1: Puppet Interaction
In the beginning, we drew a digital puppet using p5 and placed it in the middle of the screen as the interface.
For interaction, users can control the movement of a physical puppet’s arm and leg using two control bars that connected to a physical puppet’s arms and legs.
Original Puppet
By using the machine learning model poseNet, the body segment’s position will be detected accordingly and based on the user’s control, some protest sounds and movements will be triggered on the virtual one that showed on the screen. To be specific, the virtual puppet’s arm will be raised accordingly to the user’s control to the physical one, and this applied to the other arm and of course the two legs.
To simulated the protest, we created the effects that if the position of the arm is raised up to the level of its eyes, the segments will be thrown away in an attempt to get out of control but will be regenerated again after a few seconds. Here is the demo of this stage.
2. Stage 2: Human Interaction
After building up the general framework of our project, we moved on to revising the interface. After getting feedbacks, we decided to take advantage of the bodyPix, and redesign the interface using not p5 elements but pictures from the users. We first designed a stage to guide the user to take a webcam image of themselves with their full-body including head, torso, arms, and legs. We placed an outline of the human body in the middle of the screen and when the users successfully pose as the gesture, a snapshot will be taken automatically. By using bodyPix, different body segments of the user’s body will be saved based on the maximum and minimum values of x and y of different body parts. We then grouped different segments together, fixed the position of the head and torso while the user’s hands and legs can be moved accordingly with the user’s real-time position detected by poseNet. Here is the demo of this stage.
3. Stage 3: Puppet and Human Interaction
After the developed of the body the interaction we combined them together. After the user takes the snapshot, others can use the puppet to control their movements and if the movements are too intensive, the virtual image of the user will be angry and screamed some dirty words and thrown that part of its body away. However, since poseNet doesn’t really work well on the puppet, we did some manipulation which greatly increases the confidence score.
Modified Puppet
4. Stage 4: Further Development
We also continue to revise the interface by using bodyPix. We improved the image segmentation with pixel iteration. In this stage, different body segments are extracted out not based on the maximum and minimum value of x and y anymore, but just the pure segments image. Due to the time constraint, this version is not fully complete with the protesting sound and movements, so we exclude this from the final presentation. Here is a demo of this stage.
Coding
The machine learning model we used for the first stage is bodyPix, and for the following stages, we used both bodyPix and poseNet. We haven’t encountered any difficulties when extracting positions (x and y value of different body segments), however, we have some difficulties when using those values.
1. Getting the user’s body segments image using bodyPix
Bodypix detects both the front and the back of the human body. As the id listed below, for instance, PartId 3, 4, 7, 8, 13, 15, 16, 19, 20 are all the back surfaces of the human body.
Since we don’t want to keep the interface as clean as possible, we only want to get the segments we need. Based on this idea, we construct a new array with a group of 0s and 1s at the length of 24 (the length of the list that bodyPix can detect). When 1 at the corresponding index of the array, we take the segment and copy the image, while 0 means that this segment result can be ignored.
Once we get the body segments that we want, we constrained the image and subtract out the image of a person with segments. We saved the values of minimum and maximum Xs and Ys to bound the segment as a rectangle, copied the image in the bounded area to a predefined square and then arranged the orientation after scaling them to the respective position.
2. Triggering sound and movement
To trigger the protesting sound and movement, we added a time count.
In order to play the sound as an alert before the movement is triggered, we input two different if statements and with a different value ranges of the time count. For instance, here is an example of triggering the movement and sound of the right arm. Whenever the Y value of the right wrist is smaller than the Y value of the right eye, the time count started increasing on a plus 1 base. As the time count value reaches 3, the sound will be displayed, and when it reaches 5, the movement will be triggered.
To match the virtual image’s movement according to the physical movement, we decided to calculate the angles between the position of arms/legs and shoulders/hips. We searched online and used atan()(returns the arctangent (in radians) of a number) function in p5 to calculate the degree based on different x and y values that we got from poseNet.
We used translate() function to make the limbs follow users’ movement, rotate around shoulders and hips accordingly. However, this system of coordination doesn’t really work for the throwing process since they rotate around perspective center points. Therefore, we designed another coordination system and recalculated the translating center which point should be calculated from rotation with the midpoints with the simultaneous angle.
Apparently our project has a large room to be improved, not only the interaction but also the interface. During the Final IMA Show, we also found out that the snapshot took too easily and the whole project needs to be refreshed constantly. We wound definitely like to add with a time count to make users sense the way of interaction and have enough time to make the pose in front of the webcam. Restart the project is another problem that needs to be fixed so that another gesture recognition should be added to the project for restarting the process.
Reflection
We had learned a lot through this process and had a better understanding of both bodyPix and poseNet. Using a physical puppet really increase the user experience and during the IMA Show, we received a lot of resonance from the visitor of our project’s concept.
My final project is called “Dr. Manhattan”. It’s basically an application of combining different machine learning techniques together to create an interactive art project. The idea is to create a sense of post-explosion chaos vibe within the interface where users will see themselves looking as if they’re composed of nothing but the hydrogen atoms, and their body parts are scattered into pieces and floating in disorder. Then a screenshot will be taken and the users will be asked to find a way to rebuild that screenshot image to prove that they can take control over the chaos and try to find a way back to the past. The meaning behind this project is to show the fragility of human lives, the will power of mankind to seek control in the constantly changing chaotic world, and the futility of the attempt to dwell upon the past. Because however likely the image the user manipulates is to the screenshot image, there will always be a slight difference.
Inspiration:
My inspiration for this project is the superhero character “Dr. Manhattan” from the comics Watchman. In comics, this character experienced a tragic physics explosion where his body was scattered into atomic pieces. However, he eventually managed to rebuild himself atom by atom according to the basic physics law and his experience with the atoms allowed him to acquire the power of seeing his past, present, and future simultaneously. The design of this character is rather philosophical in the sense that a man who can see through the chaos of the universe and rebuild himself from atoms following the universe’s rule can’t really do anything about the chaos of the world itself. This character gives me the idea of designing a project where the users can see themselves in a very chaotic and disordered form and giving them the sense that they can actually control the chaos and return to the organized world by giving them an almost impossible task to rebuild the past moment in a constantly changing chaotic world. I also named this project after the character.
The Process of Developing with Machine Learning Techniques
In order to create a post-explosion chaotic vibe for the interface to fit the theme of the project, I first used Colfax to train several style transfer models. I tried several different images as the input and sample for the model to train on to see the outputs and eventually decided to use the one with the interstellar theme, for it gives the output give the webcam image look like everything is composed of blue dots, like hydrogen atoms. This process was relatively smooth. I uploaded the train.sh file and sample image to Colfax and then downloaded the transferred results. Each training took about 20 hours.
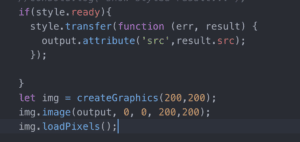
However, when I tried to use BodyPix manipulate the pixels of the style transferred images, I met with a lot of difficulties. First, I found that the output of the style transferred model can’t use the function “.loadPixels()”. After I consulted professor Moon, he told me that the output of the model was actually an Html element, thus I need to first turn these outputs into a pixel image.
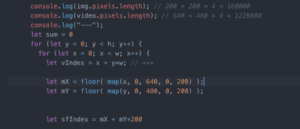
Then, I found that even though the transferred output becomes a pixel image, I still failed to effectively manipulate them with pixel iteration. The segmentation often appears repeatedly on the canvas. For instance, when I tried to manipulate the position of the left face pixels, the canvas showed four left faces of mine, which covers half of the canvas, and is not really what I was aiming for. When I asked professor Moon about this, he pointed out that since the pixel length of the pixel image after style transferred and the pixel length of the webcam image is different. Thus, I need to first learn the pixel lengths of each image and mapped the index accordingly so that I can manipulate them correctly.
However, when I managed to manipulate the pixels of the segmented body parts away from the body and make them float around the canvas, it appeared that the original part was still on the original body, even if I tried to cover those with different pixels. Professor Moon later told me that I should get another value “displayImg” to store the pixel of the “img”, and display this value.
After I used BodyPix to segment the body parts, the image on canvas showed that the person’s face is cut into half and appear in various places and the arms, shoulders, and hands are all tearing away from the body and also showing up in different places. Then, I utilized KNN to compare the current image with the screenshot image, so that the user can know how well they are rebuilding the screenshot. During the presentation, I used the save() function which can get a screenshot of the current frame and then downloaded it. However, Moon later taught me that getting a screenshot and reloading it could be done simply with the function get(). In addition, I also added the bgm to make the project seems more related to the chaos and scattering theme.
As is pointed out by the critics during the presentation, more ways of manipulating the style transferred body pixels remain to be explored. Currently, in order to make the scattered images recognizable as body parts, I took the whole arm connecting the elbow and hand apart from the body together. However, such a way of manipulating these pixels makes the scattering effect less obvious. In the future, I can try to separate the arm and hand too and manipulate those segmentations better to make them both recognizable as body parts and also more artistic. In addition, as Tristan pointed out, the way I utilized KNN in my project didn’t really contribute to the presentation of the idea I wanted to spread. Illustrating the idea of struggling in the chaos and dwelling on the past by asking the users to imitate one screenshot seems a little indirect. Thus, I should try documenting the users’ actual coordination of their body parts and let them interact with the images on canvas to trigger more different output, such as the rebuilding of part of the body, or even more serious scattering.
Many people, in current society, are under many sources of control, either physically or psychologically. And often, we find ourselves, acting against original wishes, “manipulated” by the outside world, the media, works, surrounding people, etc. Therefore, our project explores the potential to simulate this process with machine learning and a puppet, which is a typical representation of the concept of “control”.





 Professor Moon then suggested that it would be better if I just use already existing PNG images for all the still visual parts. So I took his advice and searched online for images of all these characters. At first, I was searching for images of the exact front of the character and tried to use it as a whole. But it turned out to be dull and too much. Then I thought I would cut out parts of the character that would represent the feature. And then just leave the rest of the parts to show the user’s own body. With this thought in mind, I started cutting up all the features for the characters. In the end, these are all the still images I used for visuals.
Professor Moon then suggested that it would be better if I just use already existing PNG images for all the still visual parts. So I took his advice and searched online for images of all these characters. At first, I was searching for images of the exact front of the character and tried to use it as a whole. But it turned out to be dull and too much. Then I thought I would cut out parts of the character that would represent the feature. And then just leave the rest of the parts to show the user’s own body. With this thought in mind, I started cutting up all the features for the characters. In the end, these are all the still images I used for visuals. 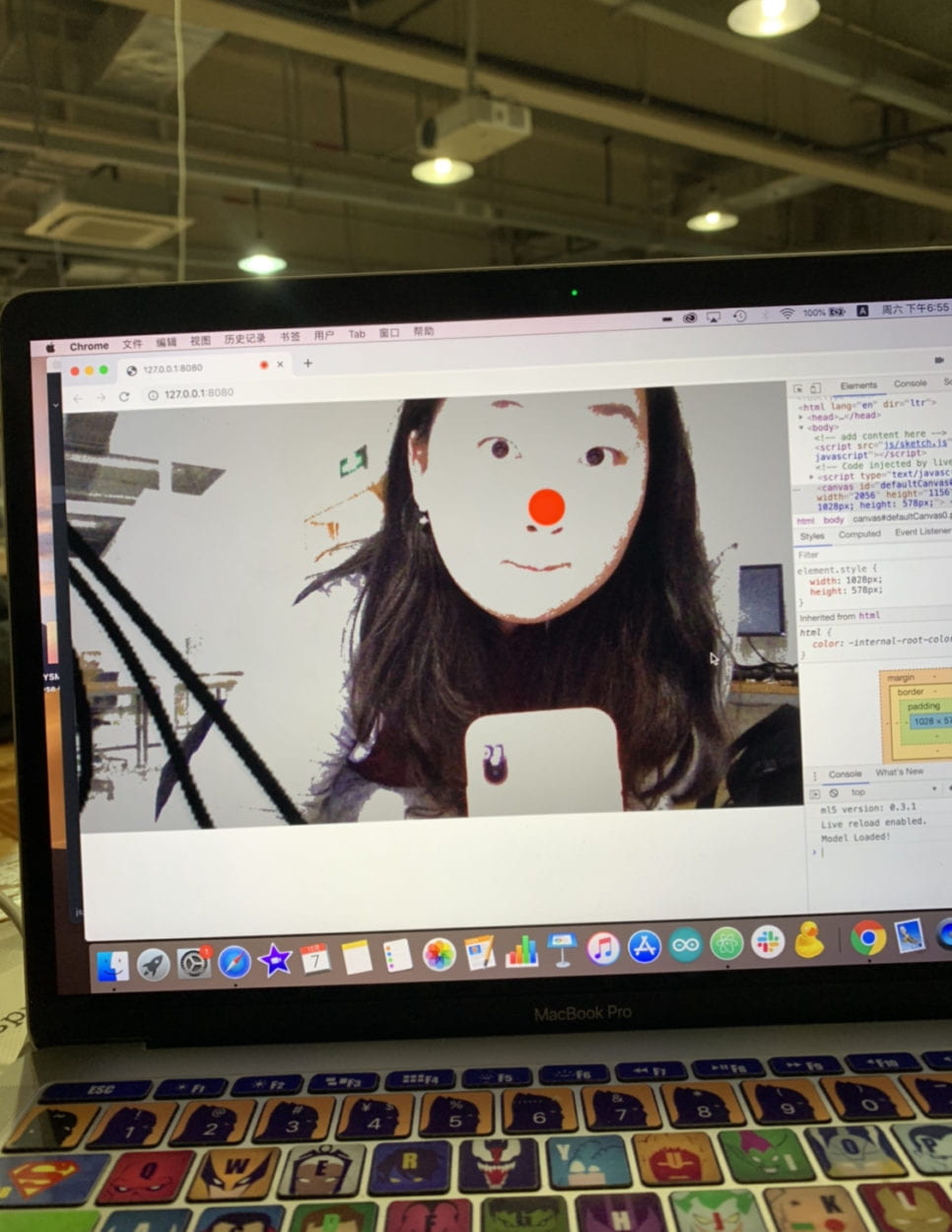 Another still visual I added was the red nose for Mickey and Minnie. It was a surprise addition. I originally used the red ellipse to mark the nose position while using Posenet. While I was meeting up with Professor Moon, he suggested that it would be great if I actually keep the red nose, looking like Rudolf. I also received well feedback on the red nose while others played with my project. So I kept it. And even though it’s not really related to the character, since Mickey and Minnie do have a nose tip, and it would be hard to show it when the user is facing front, this ellipse adds on. It fits perfectly!
Another still visual I added was the red nose for Mickey and Minnie. It was a surprise addition. I originally used the red ellipse to mark the nose position while using Posenet. While I was meeting up with Professor Moon, he suggested that it would be great if I actually keep the red nose, looking like Rudolf. I also received well feedback on the red nose while others played with my project. So I kept it. And even though it’s not really related to the character, since Mickey and Minnie do have a nose tip, and it would be hard to show it when the user is facing front, this ellipse adds on. It fits perfectly! While designing the animation for Elsa, I rewatched the clip from the music video “Let it go” where she uses her powers several times. There were a lot of things going on when she uses her magic. I decided to simplify it. While doing some research online, I saw a code from the p5.js example library, called
While designing the animation for Elsa, I rewatched the clip from the music video “Let it go” where she uses her powers several times. There were a lot of things going on when she uses her magic. I decided to simplify it. While doing some research online, I saw a code from the p5.js example library, called  But I still think that there’s something missing for this animation. I rewatched the music video and noticed that there’re snowflakes being created every single time she does magic. So I did some research some more and found this video created by
But I still think that there’s something missing for this animation. I rewatched the music video and noticed that there’re snowflakes being created every single time she does magic. So I did some research some more and found this video created by 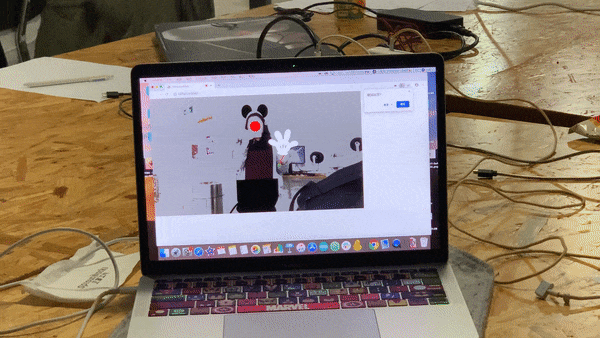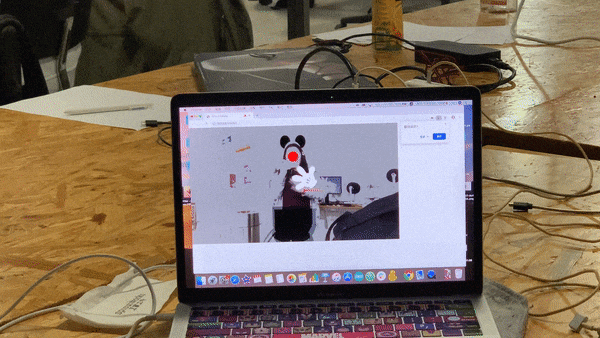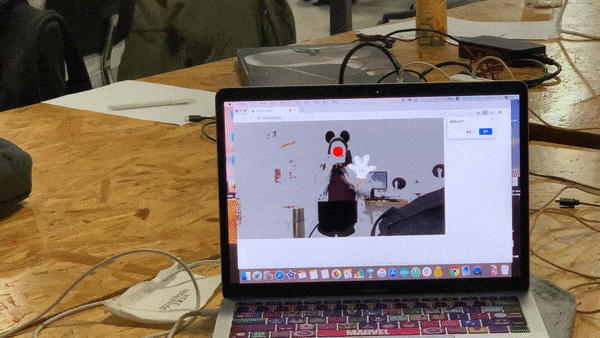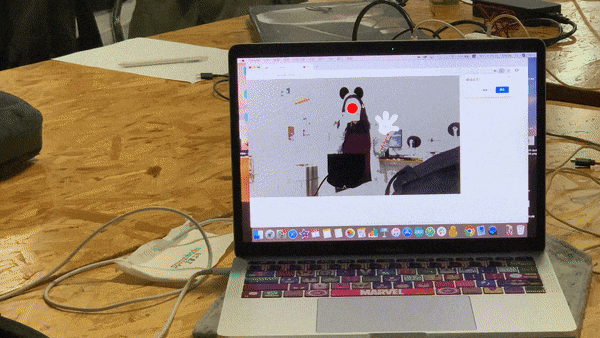
 between and relate to the angle the image is rotating. I first developed
between and relate to the angle the image is rotating. I first developed 
 Before, I said I was going to use the entire outline of Baymx. But it turned to be too stiff and dull. And since I’m thinking about adding this animation, I cut off both of his arms and made them into separate images. And I applied the similar code for the glove rotate to the arm rotate. Of course, it did take me a lot of time to adjust it and trying to find the perfect mathematic calculation to match the angle between the user’s shoulder and wrist. But It sort of worked in the end.
Before, I said I was going to use the entire outline of Baymx. But it turned to be too stiff and dull. And since I’m thinking about adding this animation, I cut off both of his arms and made them into separate images. And I applied the similar code for the glove rotate to the arm rotate. Of course, it did take me a lot of time to adjust it and trying to find the perfect mathematic calculation to match the angle between the user’s shoulder and wrist. But It sort of worked in the end. 
 project, which is basically layering ellipses with increasing radius and blend them together. I did try to make the particle move according to the wings position detected through Posenet. But for some reason, every time I tried to add it, it breaks down. So I just settled for it to have a certain area for the particles to float.
project, which is basically layering ellipses with increasing radius and blend them together. I did try to make the particle move according to the wings position detected through Posenet. But for some reason, every time I tried to add it, it breaks down. So I just settled for it to have a certain area for the particles to float. 
 But that would slow down the Posenet detection. Then Professor Moon suggested that I could try using filters to adjust it making it look like only the shadow is showing. I first explored with the filter function. Then Professor suggested that I could explore with image pixelation, which is a much better way. I used the white wall in room 818 to adjust the filter several times until I got the exact filter I wanted. During the IMA Show, another professor said that the esthetics of the filter combines with the Disney characters actually reminded her of
But that would slow down the Posenet detection. Then Professor Moon suggested that I could try using filters to adjust it making it look like only the shadow is showing. I first explored with the filter function. Then Professor suggested that I could explore with image pixelation, which is a much better way. I used the white wall in room 818 to adjust the filter several times until I got the exact filter I wanted. During the IMA Show, another professor said that the esthetics of the filter combines with the Disney characters actually reminded her of 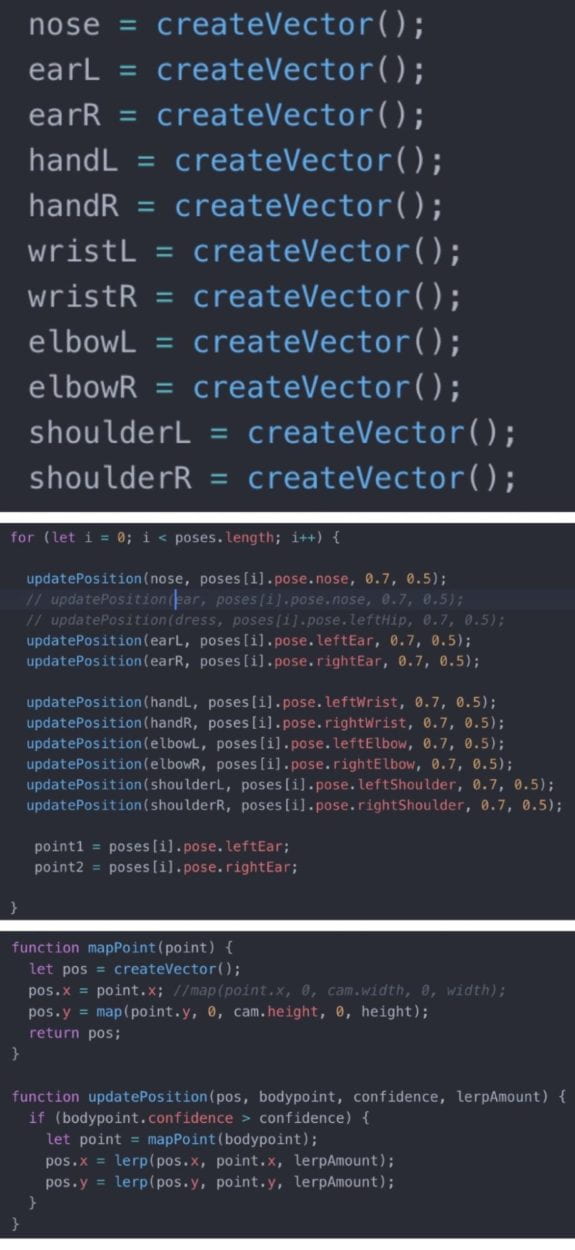 The machine learning I’m using for my final project is Posenet. The most use I get out of it is to detect the key points of the user. In order to complete all the characters, I detect several key points of the user’s body. It’s easy to detect, it’s difficult to make it work fast and stop glitching so easily. When I tried just the standard coding of Posenet myself, it was not stable and the detection was oftentimes incorrect. So I met with Professor Moon again to discuss what’s a better way to improve the code. And he introduced me to using three separate functions “create vector( )”, “map position( )” and “update position( )”. While using these three functions to update the coordinates of the key points, it fastens the detection making it running normally even added several draw functions.
The machine learning I’m using for my final project is Posenet. The most use I get out of it is to detect the key points of the user. In order to complete all the characters, I detect several key points of the user’s body. It’s easy to detect, it’s difficult to make it work fast and stop glitching so easily. When I tried just the standard coding of Posenet myself, it was not stable and the detection was oftentimes incorrect. So I met with Professor Moon again to discuss what’s a better way to improve the code. And he introduced me to using three separate functions “create vector( )”, “map position( )” and “update position( )”. While using these three functions to update the coordinates of the key points, it fastens the detection making it running normally even added several draw functions.  am inserting images based on the key points detected, it glitched moves wiggling like crazy when there is any distraction in the camera. Then Professor again helped me with a function called lerp. This function will smooth the action when an image is trying to get from one point to another. So I used this function several times with one point and it does smooth the flow of all the images movement.
am inserting images based on the key points detected, it glitched moves wiggling like crazy when there is any distraction in the camera. Then Professor again helped me with a function called lerp. This function will smooth the action when an image is trying to get from one point to another. So I used this function several times with one point and it does smooth the flow of all the images movement.  it more. I decided to add a scale function to all the character’s features, where the images would increase or decrease according to the distance between the user and the camera. To do this, I used the detection of the distance between the two shoulders of the user. Then through console logging the distance, I tried to take a few groups of numbers and figure out the math relations between them. I did this scaling function for the features of Mickey, Minnie, Baymax and Tinker Bell. For Elsa, since it’s all animation, I didn’t apply this function to her features.
it more. I decided to add a scale function to all the character’s features, where the images would increase or decrease according to the distance between the user and the camera. To do this, I used the detection of the distance between the two shoulders of the user. Then through console logging the distance, I tried to take a few groups of numbers and figure out the math relations between them. I did this scaling function for the features of Mickey, Minnie, Baymax and Tinker Bell. For Elsa, since it’s all animation, I didn’t apply this function to her features.  Then there’s the question of how am I supposed to mix them into one project. I considered using KNN, but I didn’t want to make it into a guessing game. So again, Professor Moon helped me by introducing the function of switching modes. Basically I do this in the draw function, I have a variable called “mode”, and by using keypress to change the number of the mode, it will trigger different functions. When the professor demonstrated it, he used keypress. I did consider switching it to changing the filter according to time increase, but I really want the user to explore the character they like as much as possible. But according to the IMA Show, it didn’t really work well with the keypress. So I might improve it in the future.
Then there’s the question of how am I supposed to mix them into one project. I considered using KNN, but I didn’t want to make it into a guessing game. So again, Professor Moon helped me by introducing the function of switching modes. Basically I do this in the draw function, I have a variable called “mode”, and by using keypress to change the number of the mode, it will trigger different functions. When the professor demonstrated it, he used keypress. I did consider switching it to changing the filter according to time increase, but I really want the user to explore the character they like as much as possible. But according to the IMA Show, it didn’t really work well with the keypress. So I might improve it in the future. 
 Future improvements
Future improvements