Inspired by Xu Bing’s the Book from the Sky, in which he used strokes of the Chinese character to create over 4,000 fake Chinese characters, this project aimed to find a way of generating Kanji characters by using sketchRNN. I hope this project can serve as an interesting way for the audience to feel the beauty of Chinese characters and create something new.
Technique
To achieve my goal, I used sketchRNN. By adopting the Quick Draw! dataset, sketchRNN showed an amazing performance in reconstructing different types of doodle works created by users. The unique part of sketchRNN is that it has a sequence-by-sequence autoencoder, which is able to predict the next stroke based on the last one. When combining this feature with the p5.js library using magenta.js, it can draw doodles line by line like a real person.
The dataset I choose is called Kanji Dataset, which contains 10000 characters for training, 600 for validation and 500 for testing. The reason why I chose that dataset is that all the sketches in this dataset are vector drawings which are the perfect form for training sketchRNN. Once plugin with this model, of course, the sketchRNN will not be able to understand the meaning behind those characters but it will try to use different types of stroke I learned to recompose characters. This process is quite similar to what Xu Bing did in the Book From the Sky.
Overview
In general, this project is made by three parts: Kanji generator, Kanji Sketch Board and the description part.
Kanji Generator
This is the first page the audience will see once they open the project. The generator will keep creating new characters in the background from top to the button. Once it researches the button, it will start a new line from the right side. It feels like there is a real person who is writing on the blank page, and it’s quite funny to watch. Few of the characters it writes are real ones, but most of them are entirely new characters. The shape of those characters varies a lot. Some have existing elements in it while some are completely made from no-sense strokes. The writing process echoes to my experience when I forgot how to write certain characters. It can be seen that sometimes the AI is quite confident with its memory, it composed elements in a nice form, but when it’s going to complete the rest of the character, it kind of forgets how to do it and randomly put some strokes on it. Once the characters fill all the screen, it will clean the full screen and start over. This part serves as a blurred background of the whole project, and in the middle of the project, it will be shown again.
Kanji Sketch Board
The sketch board will be presented to the user once they have gone through a brief introduction, it and also be directly accessed by clicking the brush shape button below the screen.
On this sketch board, the user will be able to create their own characters by drawing on it. Once they accomplish several strokes, the AI will help their finish the rest of it. There are three buttons on the top right. The most left will clear the whole screen, and the middle one will let the AI rewrite the stroke that it just wrote, the right one allows the user to save their work to their devices. The writing process is quite interesting. I found that the AI won’t respond to every stroke I wrote. For instance, if I wrote the Chinese character of NYU SH IMA department (上海紐約大學交互媒體與藝術) in the traditional form, only the character 紐, 約, 互 will trigger the AI to write the rest strokes. After a few experiments, I found some strokes become quite easy to trigger the AI, as I showed in the presentation. And it also requires some writing techniques. If using the mouse to write, it’s very hard to trigger the AI since the input should be rather smooth. So I used the iPad as the sketch board, which I will mention in the Other Works part. This might because the percentage of different Chinese character elements in the dataset is unbalanced, there are some elements have been used to train way more times compared to others, which makes them become more easily to be recognized.
Description Part
In this part, I gave some introduction of the Kanji’s history and my inspirations. I applied some web animation to present the content by using an editor called hype which allows me to create those animation effect and generate the html page.
Other Works
I posted the website to Github so it can be openly accessed by this link. The Chrome can achieve the best effect and the user need to scroll at the side of the page. My initial thought was that the user can access this page with their iPad so the drawing process can be done in a smoother way, but I then figured out that the borrowers on iPad will cash every time when I open this site while it works pretty well on my laptop. It seems that the compatibility of the magenta framework is not that good with iPad. So I removed part of its function and just kept the sketch board part. This time it works for iPad. So as Aven has shown in one of our classes, I saved this page to my iPad’s desktop so it looks like an app and the user can write with the Apple Pencil.
Future Works
The performance of the sketchRNN still has space to improve. The dataset is relatively small compared to Quick Draw! dataset. So when the user is trying to generate Kanji characters, there are certain limitations. First, the users’ writing must follow the style in the dataset but the fact is that each different people has their own style of writing Chinese characters. And also some strokes are hard to be recognized by the AI since their data size might be very small in the Kanji dataset. The best way to improve this part is to have a bigger dataset which has the collection of characters wrote by different people. To gather the data, the way used to collect the Quick Draw! dataset, which is to use a game to collect users’ drawing, can also be used to collect the writing of Chinese characters. Amazon’s AMT can be another way to collect those data. The shape of the strokes can also be improved. It could be better if those strokes can resemble the real Chinese brush style. And by using the style transfer network, the user can transfer their work into a real Chinese calligraphy work.
RePictionary is a fun 2 player game (read: Reverse Pictionary) in which users type in descirptions of images that are generated by an attnGAN and guess each other’s image descriptions. The scoring is done using sentence similarity with spaCy‘s word vectors.
How it looks like
Here are some images of the interface of the game. I used some retro fonts and the age-old marquee tags to give it a very nostalgic feel. Follow along as two great minds try to play the game.
Choose basic game setting to begin
First player gets to type in a caption to generate an image
Second player must guess the image that was GANarated
Scores are assigned based on how similar the guess was to the original caption
The model uses MS CoCo dataset, a popular dataset of images used for object and image recognition along with a range of other topics related to computer vision.
The scoring
For the scoring part, I used the age-old sentence similarity provided by spaCy. It uses word vectors to provide cosine similarity of the average vectors of the entire sentence. To avoid giving high scores to semantic similarity and place more importance of the actual content, I modified the input to the similarity function as described in this StackOverflow answer. The results looked pretty promising to me.
The web interface
The entire web interface was created using Flask. The picture below is a rough sketch of the artitecture and the game logic specific to the web application.
Details that are lacking here can be found by reading through the code, most of the relavant stuff is written in app.py. There are various routes and majority of the game data is passed using POST requests to the server. There is no database and game data such as scores are store as global variables, mostly since the project was a short term project for which I did not really need to create a database to do many things.
Why I did this
I knew I wanted to try and explore the domain of text-to-image synthesis. Instead of making a rudimentary interface to just wow users with the fact that computers nowadays are making strides in text-to-image generation with GANs, I decided to gamify this. It’s a twist on a classic game we’ve all played as kids. Although the images generated are sometimes (highly) inaccurate, I’m happy that I’ve created a framework to potentially take this game further and make the image generation more accurate using a specific domain of images. Since the images were a bit off, I obviously followed the age old philosophy “it is not a bug, it is a feature” and came up with the whole jig about the AI being trippy.
Also, if you remember, I had the idea of generating Pokemon with this kind of model. After much reading and figuring out, I came to realise it might actually be possible. I intend to pursue this project on my own during the summer. I couldn’t really do much for the final project in this direction because it was too complex to train and I did not have a rich dataset. However, I’ve found some nice websites from which I could scrape some data and potentially use that to train the pokemon generator. I’m quite excited to see how it would turn out.
Potential Improvements
Obviously, the image generation is very sloppy. I would like to train the model using a specific domain of images. For example, only food images would be a fun way to proceed, given that I am able to find a decent dataset or compile one on my own.
The generation of the image takes roughly 2 seconds or so. I don’t think there’s a way to speed that part up but maybe it’d be nice to have a GIF or animation play while the image is being generated.
Add a live score-tracking snippet on the side of the webpage to let users keep track of their scores on all pages.
Try out other GAN models and see how they perform in text-to-image generation. Of particular interest would be the StackGAN++, an earlier iteration of the AttnGAN.
All the code is available on GitHub. The documentation is the same as the one on GitHub, with additional details and modifications.
Project: GPT2 Model trained on reddit titles – Andrew Huang
Motivation
After working in primarily image data for the semester, I thought it would be interesting to start working on text data for my final project. Initially I wanted to present my final thesis about vocal sentiment analysis, but I was not sure if IMA policy would allow me to do so, and also the contents of that may be outside the scope of this course, and not really in the spirit of IMA and more in the spirit of CS courses. After seeing a model on Hackernoon about GPT2 and how good it is at generating coherent titles from it’s own website, I thought about creating and training my own model so that I can generate my own titles. Because it is near graduation time, I have been spending a lot of my time on r/cscareerquestions looking at my (not) so hopeful future. I realized most of the threads have a common theme and I realized, what if a machine learning system can generalize and help me make my own titles? I also have tried a model called char-rnn in the past, and I have seen language models work decently with machine learning at text generation. So I decided after looking online about how great the GPT-2 Model made by OpenAI was at generating text with good context awareness, I decided to train my own model which was good at generating computer science oriented titles.
Process
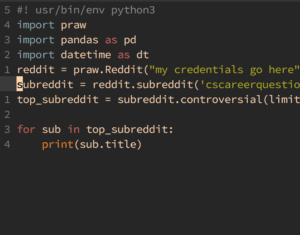
To start I extracted several thousand subreddit titles using a tool called praw. I did not have much trouble getting this code to work online for me, and all of the APIs were very clear to use.
With this I made a user application, and was able to get to get the top 1000 posts from all the respective categories, (top, controversial, etc). Once I had sufficient model, I loaded the code onto jupyter notebook from the local model initially. I discovered from the original author (Max Praw) that he had his model code in a Google Notebook called Colab. I found out that the compute performance on these notebook environments are very powerful and additionally I did not have to deal with awful dependency issues across different systems (NYUSH HPC vs INTEL Cluster) etc, so I decided to start training on there and the speed on those servers would be much faster than on both HPC and the intel cluster. I trained my dataset on the 117M parameter version of the model, as I thought that would not take too much time as the larger version of the model.
After 1000 epochs and an hour and a half of training, the model was trained. The notebooks that google offers have a Nvidia Tesla T4 GPU built for machine learning, so the models that were trained there trained very quickly.
Results
The results from my experiments were decent. I think I may have needed to get my titles from a more diverse pool of subreddit content, but because I wanted all of the generated titles to be from one central theme, I did not explore other options. As with training on all machine learning tasks, there is always that issue of “overfitting”. I believe I ran into this issue. I google’d a lot of the titles generated by the model and lot of them were direct copy of the titles that I had in the original source training set, so this is an indication of overfitting. However, it did a good job in creating coherent generation because none of the samples had cut off words or any malformed words.
Conclusion
The GPT2 Python Apis provide us users with a high level way to train an advanced language text model on any dataset with pretty good results. I would like to understand for myself in the future how GPT2 works on a deeper level, while working on my capstone project I did look into attention models and transformer, and I know that GPT2 is a variant of those models with a large number of model parameters, and the implications of this model are pretty good. I see a use of this as a good start for building a chatbot when you have a large corpus of human – human interactions for example in call centers when humans commonly resolve tasks that employees find extremely repetitive. These tasks can be automated away in favor of more productive tasks. Perhaps my GPT2 models can also be trained on the body of the posts, and I know that GPT2 models can be “seeded” so I feel a lazy user could input their own title and have a relevant user generated from it from key advice that it may wish to know, instead of using the search bar which may just use keyword matching and link it to irrelevant information. If I had more time, I would definitely make a frontend/backend using these weights and allow the user to use these prompts (consider it future work) In this use case, text generation could also be a kind of a search engine. Overall, this project was a success for me and taught me a lot about IML and how helpful interactive text generation can be for all sorts of different use cases, and how adaptive and robust these models can be.
For those who are interested the code is attached below :
As described in my previous post, I wished to explore GANs and generative art in my final project. In particular, I was very interested in cross-domain translation, and since then, I feel I’ve come a decent way in terms of understanding what sort of GAN model is used for what purposes.
After doing some initial research, I came across multiple different possibilities in terms of the possible datasets I could use.
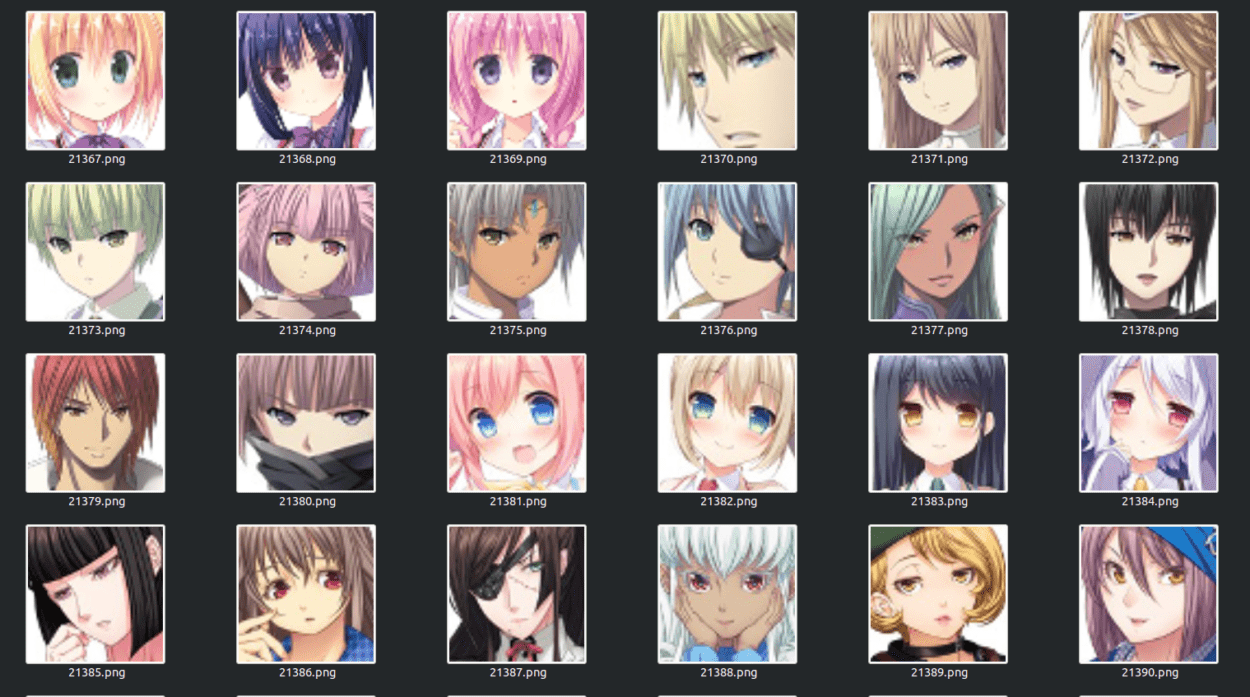
Since this involves two domains, I need two datasets, namely human faces and anime faces. Getting the human faces dataset was quite easy, I used the popular CelebA dataset. Since this set came with over 250000 images, I decided to just use 25000 since that would speed up training time. (Later, I found out that 25,000 is way too much and would still be extremely slow, so I opted for a much, much more smaller set)
For the anime faces dataset, I had a few options to pick from.
Getchu Dataset – This dataset came with roughly 21000 64×64 images Danbooru Donmai – This dataset had roughly 143,000 images Anime Faces – This had another 100,000 or so images.
I decided to go with the Getchu dataset since that would mean an equal load on each GAN in the cycleGAN model.
Here is a sample from both datasets.
Getchu DatasetCelebA Dataset
Having done the cycleGAN exercise in class, I came to understand how slow the Intel AI cluster was ,and proceeded to find other means to train my final project model. Aven mentioned that some of the computers in the IMA Lab have NVIDIA GTX1080 cards and are very well suited for training ML models. I then went on to dual-boot Ubuntu 18.04 onto one of them. Once that was done, I needed to install the necessary nvidia drivers as well as CUDA, which allows you to use TensorFlow-GPU. I severely underestimated how long it would take to set up the GPU on the computer to run Tensorflow. This stems from the fact there is no fixed configuration for setting up the GPU. It requires three main components – the Nvidia driver, the CUDA toolkit and CuDNN. Each of these have multiple different versions, and each of those different versions have different support capabilities for different versions of TensorFlow and The key idea is to grow both the generator and discriminator progressively: starting from a low resolution, we add new layers that model increasingly fine details as training progresses. This both speeds the training up and greatly stabilizes it, allowing us to produce images of unprecedented quality_Ubuntu. So, setting up the GPU system took multiple re-tries, some of which resulted in horrendous results like losing access to the Linux GUI, and control over the keyboard and mouse. After recovering the operating system and going through multiple Youtube videos like this, as well as Medium articles and tutorials, I was finally able to set up the necessary GPU drivers that can work
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2with Tensorflow-gpu.
Once, I had my datasets, I proceeded to look for suitable model architectures to use my images on. I came across multiple different models, and came down to a question of which one would be most suitable.
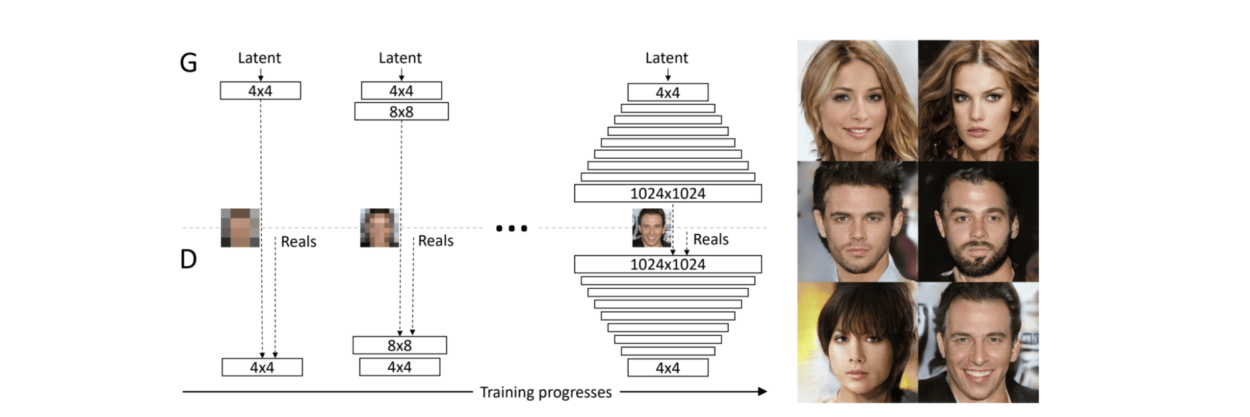
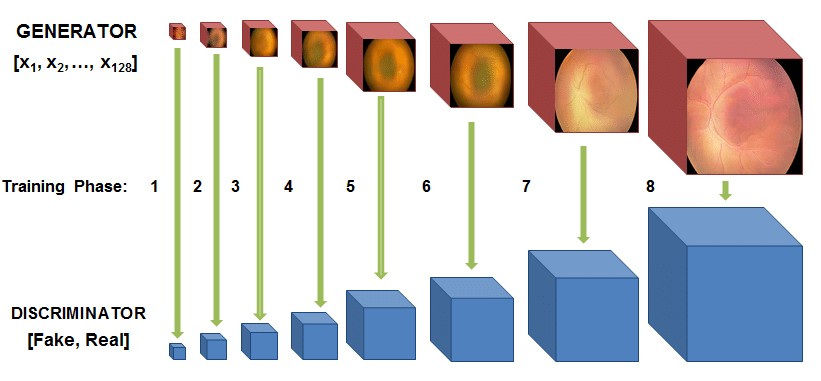
The first model I came across was called TwinGAN which the author described as “Unpaired Cross-Domain Image Translation with Weight-Sharing GANs.” This particular model of GAN is based on an architecture called a Progressively Growing GAN or PCGAN. The author describes the architecture as “to grow both the generator and discriminator progressively: starting from a low resolution, we add new layers that model increasingly fine details as training progresses. This both speeds the training up and greatly stabilizes it, allowing us to produce images of unprecedented quality.” It is clear that this architecture would allow for higher resolution outputs as opposed to the classic cycleGAN.
Here’s an illustration of how PGGAN (the model that TwinGAN is based on) works.
The first step was to prepare the datasets, and the author of the TwinGAN model had structured the code in such a way that the code takes in .tfrecord files as inputs instead of regular images. This meant there was an additional pre-processing step but that was fairly easy using the scripts provided.

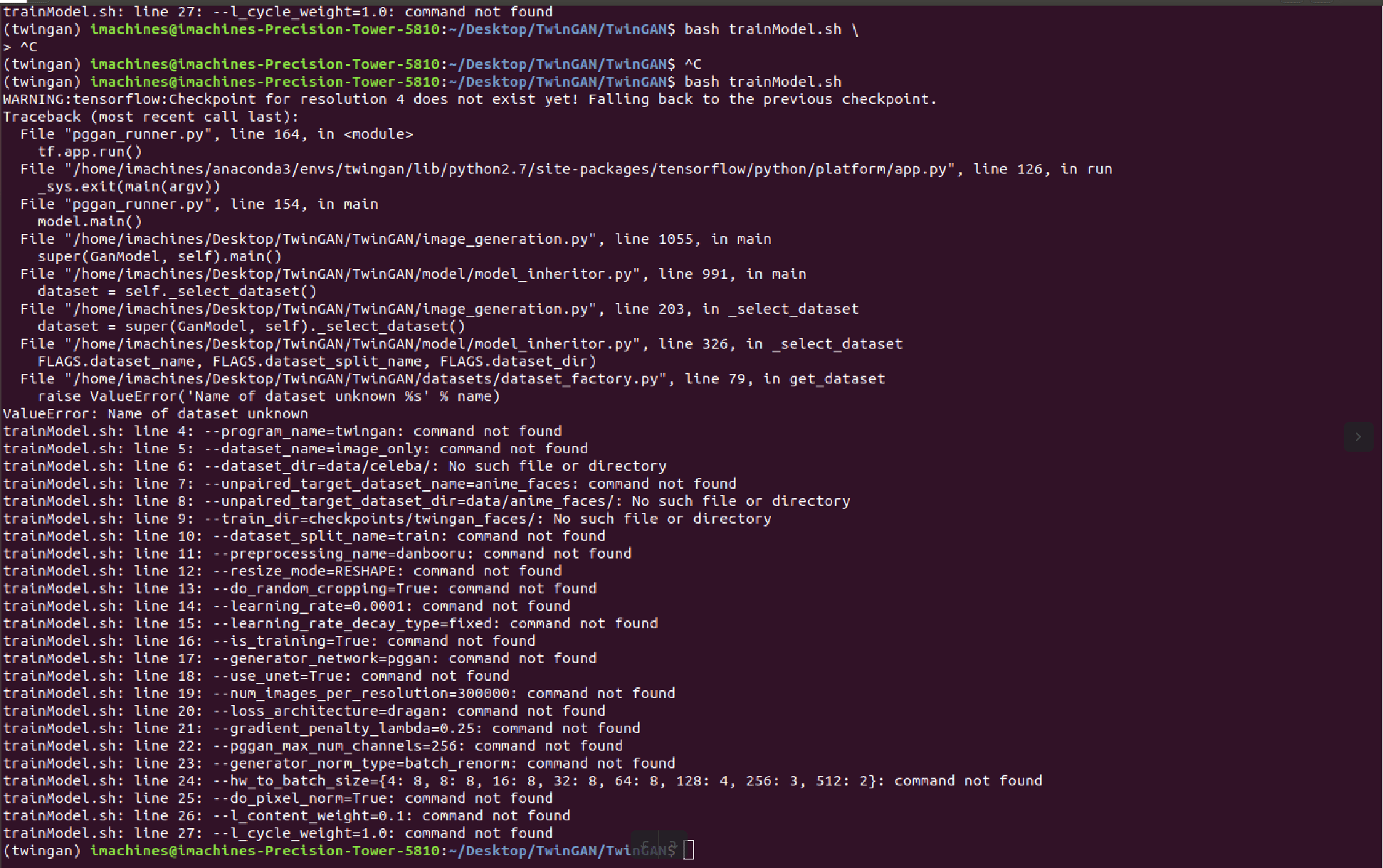
After that was done, it was a matter of setting up the training scripting script with the updated datasets and relative paths with the new training sets. Once that was set up, it was just a matter of launching the script and hoping that it would start the training task. However, it turned out that that wouldn’t be the case. I was presented with errors such as these.

Initially, I was presented with a few “module not found” errors but that was resolved fairly easily after installing the relevant module through pip/conda.
With errors such as the one above it is difficult to determine from where they began propagating far since I had a very limited understanding of the code base.
Prior to running the code, I set up a conda environment with the packages as described by the author. This meant installing very specific versions of specific packages. His requirements.txt is below:
tensorflow==1.8
Pillow==5.2
scipy==1.1.0
However, he did not mention which version of Linux he had been using, nor had he mentioned whether or not the code was CUDA-enabled, and if it was, which version of CUDA it was running on at the time. This made it difficult to
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2determine which version of CUDA/Tensorflow-GPU/etc would be most compatible with this particular codebase.
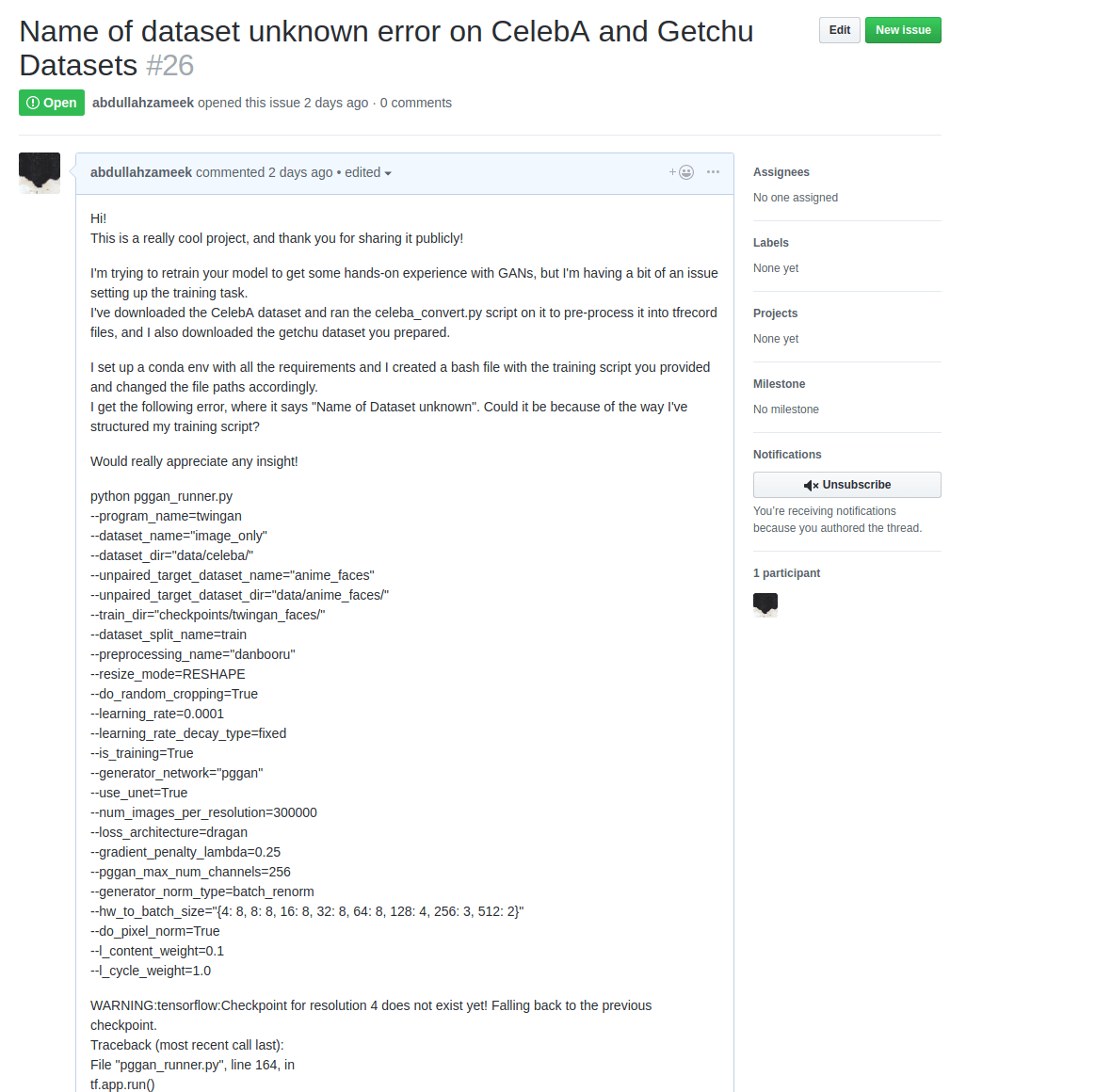
I went through the past issues on his Github repo, but could not find any leads on what the issue might have been, so I decided to open up an issue on his repo. 
At the time of writing this post, two days have past since I opened the issue, but I haven’t received any feedback as of yet.
Seeing that I wasn’t making much progress with this model, I decided to move onto another one. This time around, I tried using LynnHo’s cycleGAN (which I believe is the base of the model that Aven used in class). The latest version of his CycleGAN uses Tensorflow 2, but it turned out Tensorflow 2 required the latest CUDA 10.0 and various other requirements that the current build I set up didnt have. However, Lynn also had a model previously built with an older version of Tensorflow so I opted to use that instead.
I took a look at the structure of the training and test sets and modified the data that I had to fit the model.
So, the data had to be broken down into 4 parts : testA, testB, trainA, trainB.
A is the domain you’re translating from, and B is the domain you’re translating too.
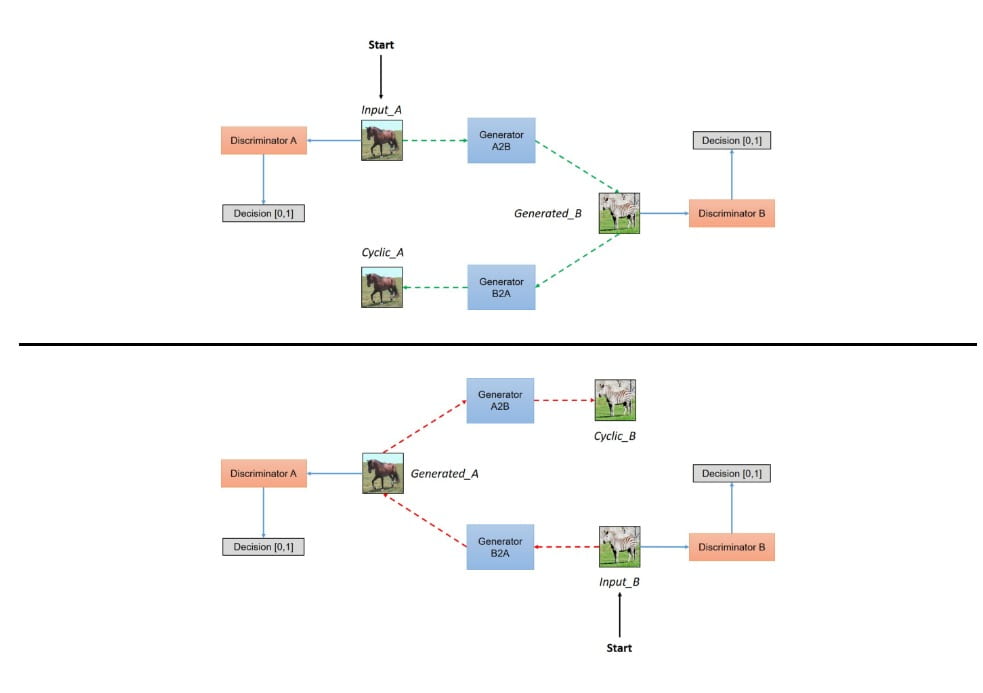
For the sake of completeness, here’s a illustration of how CycleGAN works.
The next step was set up the environment and make sure it was working. Here are the requirements for this environment:
tensorflow r1.7
python 2.7
I looked fairly straightforward and I thought to myself, “What can go wrong this time?” Shortly after, I went through another cycle of dependency/library hell as many packages seemed to be clashing with each other again.
After I installed Tensorflow v.1.7, I verified the installation, it seemed to be working fine.

However, after I installed Python 2.7, the Tensorflow installation broke.
Once again, I had to deal with mismatched packages, but this time, it was incompatibilities between Tensorflow and Python. After looking up what
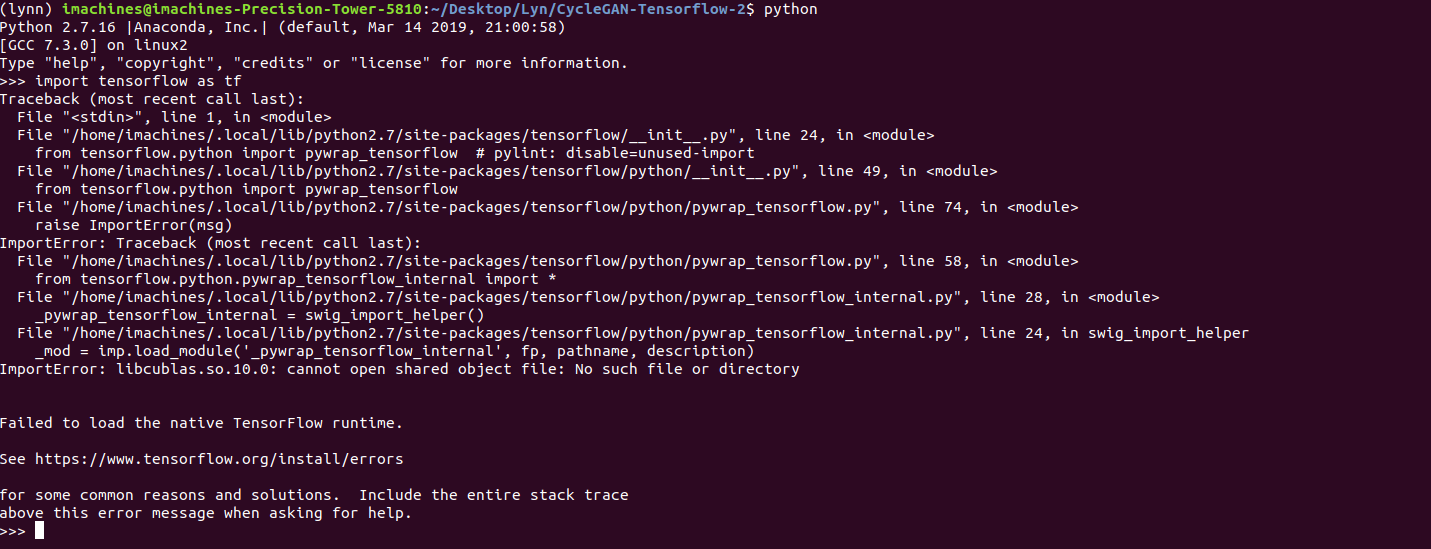
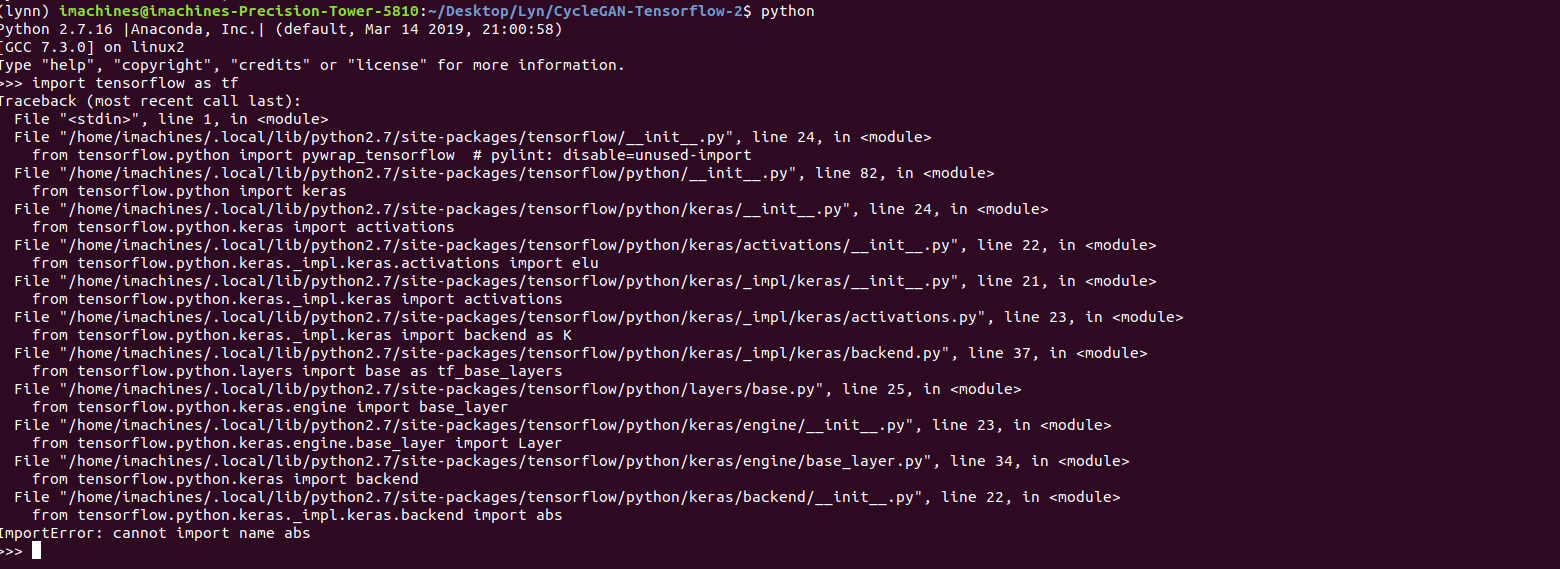
“ImportError: libcublas.so.10.0: cannot open shared object file: No such file or directory”, I then learnt that it was because Tensorflow was looking for the latest version of CUDA and CuDNN. One solution was to install CUDA and CuDNN through conda and once I did that, I tried to verify Tensorflow once again. This time, I got another error. 
The error this time read, “ImportError: cannot import name abs” and it was spawned by tensorflow.python.keras which from my very brief experience with TF, was a generally troublesome module. After going through multiple fixes, the environment itself was ridden with many inconsistencies and it got to a point where the Python terminal couldn’t even recognize the keyword “Tensorflow” 
At this point, I hit a complete dead end, so I cleaned out the conda cache, deleted all the environments, and tried again. Once again, I was met with the same set of errors.
Since it looked as if I wasn’t making much progress on these other models, I opted to use Aven’s Intel-AI cluster model since it was already tried and tested. Note that the reason why I opted to use another model was because my intention was to train it on a GPU and that would allow me to use a larger dataset to obtain weights in a relatively shorter amount of time. Additionally, it gave me the ability to explore more computationally complex models such as PGGAN that require way more resources than regular cycleGAN models.
In any case, I began configuring the AI cluster optimized model with my dataset, and initially, I set it to run with 21,000 images (not intentionally). The outcome however, was quite amusing. After roughly 16 hours, the model had barely gone through one and a half epochs.
Afterwards, I trimmed the dataset down greatly as follows:
Train A : 402
Train B : 5001
Test A : 189
Test B: 169
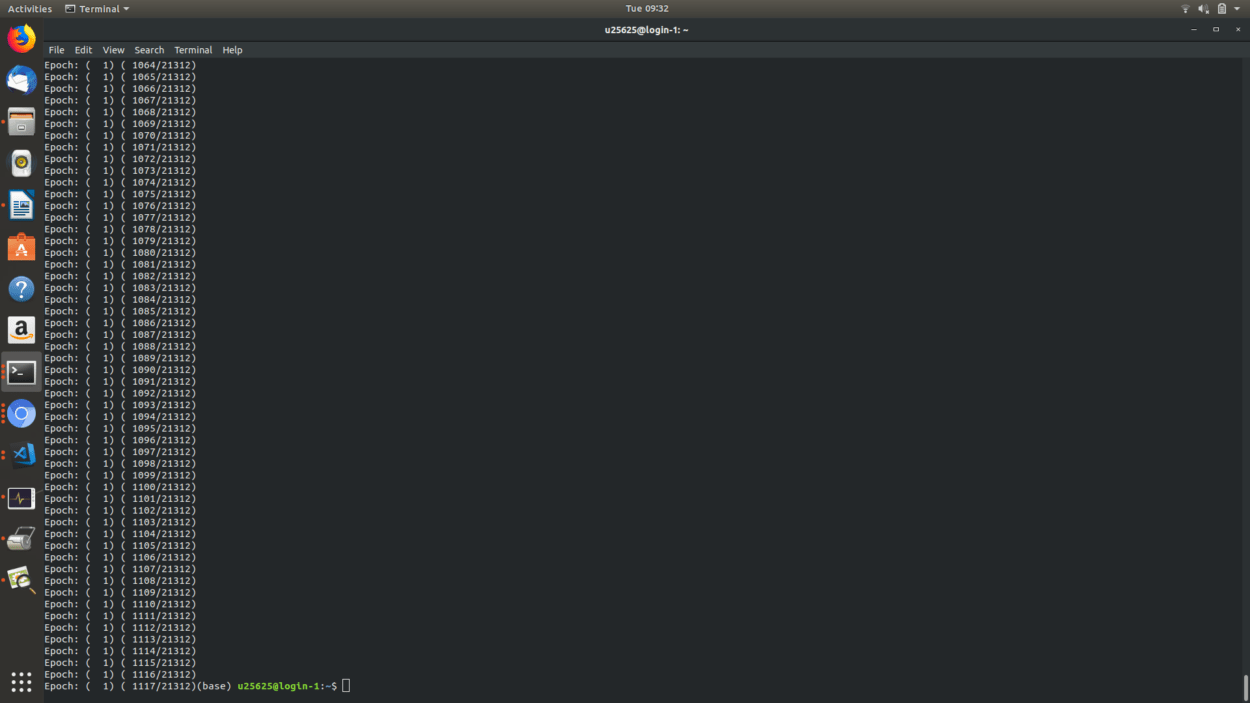
With this set, I was able to train the model to 200 epochs in just over two days. Once I copied the weights over and converted the checkpoints to Tensorflow.js, I put the weights through the inference code to see the output, and this is what I got.
The result is not what I expected because of the fact that I did not train on a large enough dataset, and I did not train for enough epochs. But, judging by the amount of time I had plus the computation resources at my disposal, I feel that this is the best model I could have put up. At the time of writing this post, another dataset is currently training on the Dev Cloud, which will hopefully render better results.
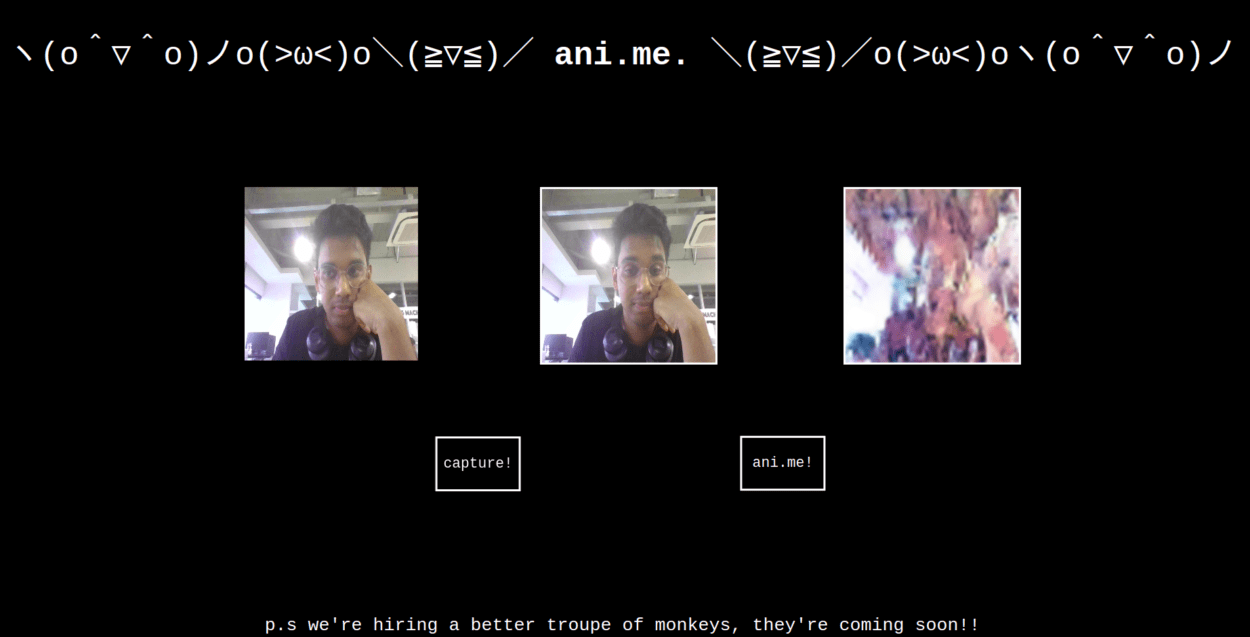
With regards to the actual interface, my idea was that the user should be able to interact with the model directly, so integrating a real-time camera/video feed was essential. Enter p5js.
I wanted to present the user with three frames – a live video feed, a frame that will hold the picture that they click, and the GAN generated picture. Going from the second to the third frame was really easy, we had done it already in class, so doing that was really easy. The problem was going from the first frame to the second. I thought it would be fairly easy, but turns out it was actually a tad bit more complicated. This is because while p5js has the capability to “take a picture”, there is no direct way to actually render that picture back to the DOM. The solution was to extract the pixels from the necessary frame and then convert those to base64, and pass it through the src of the second frame using plain, vanilla JS,
The actual layout is very simple, The page has the three frames, and 2 buttons. One button allows the user to take a picture and the other initiates the GAN output. I’m really fond of monochromatic, and plain layouts, which is why I opted for a simple and clean black and white interface. I’ve grown quite fond of monospace, so that’s been my font of choice.
Additionally, I decided to host the entire sketch on Heroku, with the help of a simple Node server. The link to the site is here . (You can also view my second ML-based project for Communications Lab, sent.ai.rt, over here )
However, please do exercise a bit of caution before using the sites. While I can almost certainly guarantee that the site is fully functional, I have had multiple occasions where the site causes the browser to become unresponsive and/or clog up with computer RAM. This is almost certainly because of the fact that all the processing is done on the client side, including the loading of the large weights that make up the machine learning model.
The main code base can be found here and the code for the Heroku version can be found on the same repository but under the branch named “heroku”
Post-Mortem:
All in all, I quite enjoyed the entire experience from start to end. Not only did I gain familiarity with GAN models (upto some extent), I also learnt how to configure Linux machines, work with GPUs, deal with the frustrations of missing/deprecated/conflicting packages in Tensorflow, Python, CUDA, CuDNN and the rest, learning how to make code in different frameworks (Tensorflow.js and p5.js , in this case) talk to each other smoothly as well as figure out how to deploy my work to a publicly view-able platform. If there were things I would have done differently, I would have definitely opted to use PGGAN rather than CycleGAN since it is way better suited for the task. And, even with CycleGAN, I wish I had more time to actually train the model more to get a much cleaner output.
On the note of hosting and sharing ML-powered projects on the web, I am still yet to find a proper host where I can deploy my projects. The reason why I opted for Heroku (other than the fact that it is free) is because I am reasonably familiar with setting up a Heroku app, and in the past, its proven to be quite reliable. On another note, I think it is important to rethink the workflow of web-based ML projects seeing that
a) Most free services are really slow at sending the model weights across to the client
b) The actual processing on the browser seems to be taking a great toll on the browser itself, making overloading the memory and crashing the browser very likely.
I think that, in an ideal scenario, there would be some mechanism whereby the ML-related processing is done on the server side, and the results are sent over and rendered on the front end. My knowledge related to server side scripting is very, very limited, but had I had some extra time, I think I would have liked to have tried setting up the workflow in such a way that the heavy lifting was not done on the browser. That would not only lift the burden off the browser but would also make the user-experience a lot better.
This week I was playing with the Cycle GAN to generate some interesting images. However, due to the time limit and my access to the Intel AI DevCloud has been canceled. I tested Cycle GAN using the model we transferred during the class and here shows some of the results:
The images transferred from the original one make me feel like the content had been blurred. And their color scheme also changed a little bit and became more similar to the real-world color. In other words, the contrast of the color had been reduced. This model preformed quite well in dealing with water color and the sky, but it performed less well in transferring the figures of building, trees and the bridge in the first image. Two possible reason might be count for this result. First, if the transfer logic is that the real-world image is smoother in their texture and the network is trying to blur the art piece in order to achieve the similar effect, the water and the sky are certain more easy to deal with. Second, the training set might be more images related to the water or the sky and those figures are more easy for the network to extract their characteristic.
Then I tested another network with Monet’s painting. This model is a convolutional network which can transfer style of one image to another. I found an image from the web which is the real spot where Monet put in his work. The reason that I chose this one is because this might be the best picture that perfectly represent the light and the color in Monet’s painting, so we can have a comparison between this one and the circle GAN based on the output. So here is what I got:
The input image, the first one is the real-world figure:
The output:
It looks like model only tried to combine the two different styles instead of transferring one’s style to another one. And this network can also combine two styles so I had a try but the output was quite the same. The circle GAN achieved a better performance without any doubts.