Introduction
For my final project, I wanted to explore audio generation with Magenta. My original idea was to use NASA data to generate sounds based on data collected on the universe, but I came up with a better idea shortly after. Having played the violin for ten years, I have found that the violin is difficult to play because it requires accurate finger positions and complex bow technique. I wanted to create an interface for people to make music without musical experience. My inspiration for this project also came from the Piano Genie project that Google made, which allows for improvisation on the piano.
Process
The goal of this project was to use notes played from the violin to produce a sequence of notes on the computer. Below are the steps I needed to complete in order to make the project come to life.
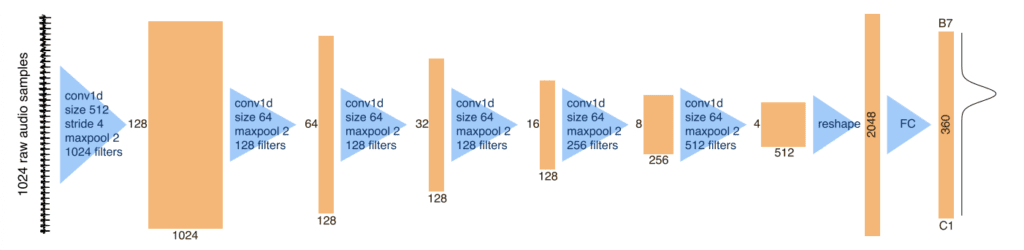
I began by experimenting with a variety of pitch detection algorithms, which included McLeod pitch, YIN(-FFT), Probabilistic YIN, and Probabilistic MPM. I ultimately decided to use a machine learning algorithm included in the ml5.js library. The ml5.js pitch detection algorithm uses CREPE, which is a deep convolutional neural network which translates the audio signal into a pitch estimate. Below is a diagram of the layers and dimensions of the model included in the paper.
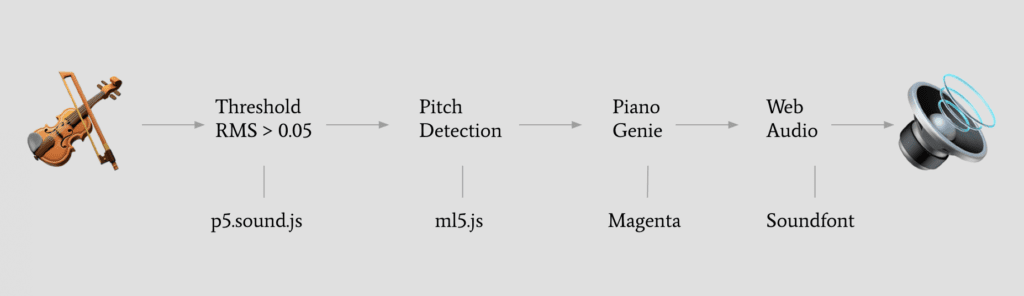
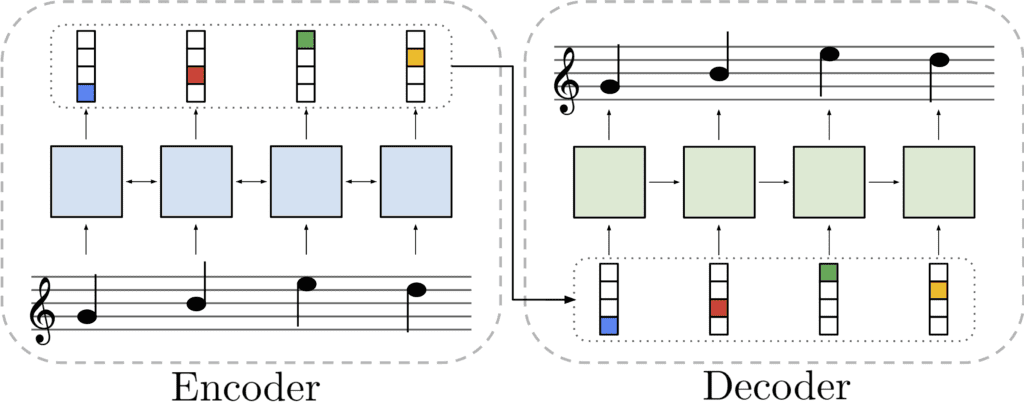
After running the pitch detection and checking that the RMS level is greater than 0.05, we call a function in Piano Genie that asks for a prediction based on the model. This can also be done by moving the bow across the violin or typing 1-8 on the keyboard. I created a mapping based on the string that is played. For example, G will call 1 and 4 on the model, D will call 2 and 5, A will call 3 and 6, and E will call 4 and 7. These are chords that are usually spaced an octave apart from each other. Most of the time the notes played are harmonious, but occasionally they sound awful. Below is an explanation of the Piano Genie model from their website.
Training
I trained the data on the following songs from classicalarchives.com, which had violin and piano parts:
Sonata No.1 for Solo Violin in G-, BWV1001
Partita No.1 for Solo Violin in B-, BWV1002
Sonata No.2 for Solo Violin in A-, BWV1003
Partita No.2 for Solo Violin in D-, BWV1004
Sonata No.3 for Solo Violin in C, BWV1005
Partita No.3 for Solo Violin in E, BWV1006
Violin Sonatas and Other Violin Works, BWV1014-1026
Violin Sonata in G, BWV1019a (alternate movements of BWV1019)
Violin Sonata in G-, BWV1020 (doubtful, perhaps by C.P.E. Bach)
Violin Suite in A, BWV1025 (after S.L. Weiss)
Below is a sample of a Bach Sonata:
I ran the included model training code which can be found here. I attempted to the training script on the Intel AI Devcloud, but the mangeta library requires libasound2-dev and libjack-dev to work. This cannot be installed since apt-get is blocked on the server. I scraped the files off the classical archives website and converted it into a notesequence which can be read by tensorflow. I then evaluated the model and converted it using a tensorflow.js model. When I was converting the tensorflow model into a tensorflow.js model, I ran into some dependency trouble. The script wanted me to use a tensorflow 2.0 nightly build but it wasn’t available for mac. I had to create a new python 3.6 environment and install dependencies manually.
Challenges
Along the way, I ran into a couple issues that I was mostly able to resolve or work around. First, I had an issues with AudioContext in Chrome. Ever since the autoplay changes introduces a few years ago, microphone input and audio output is restricted as a result of obnoxious video advertisements. Generally, this is good, but in my case the microphone would not work 50% of the time in Chrome, even when audioContext.resume() was called. This could be because p5.js or ml5.js has not been updated to support these changes, or it could be my own fault. Ultimately, I used Firefox, which has more open policies and fixed the issue.
Another issue I had was that Ml5.js and Magenta were conflicting with each other when run together. I could not figure out why this was occurring, I assume this was because they used the same tensorflow.js backend which may have caused issues with the graphics. Rather than fixing the error, my only real option was to silence it.
Results
Live Demo: https://thomastai.com/magicviolin
Source Code: https://github.com/thomastai1666/IML-Final

I was generally pretty happy about the results that I produced. The model is not very good at generating rhythm but it does a good job at generating Bach style chords. The pitch detection model also needs some modifications to pick up notes more accurately. Much of the work was already done by the Piano Genie team who created the model, I only adapted it to work for the violin. The violin is rarely used in any machine learning experiments because it is difficult to receive notes, whereas the Piano has midi support which allows it to work universally. I hope that as machine learning grows, more instruments will be supported.
Sources
Magenta Piano Genie – https://magenta.tensorflow.org/pianogenie
Piano Genie Source Code – https://glitch.com/edit/#!/piano-genie
Violin Soundfont – https://github.com/gleitz/midi-js-soundfonts
Pitch Detection – https://ml5js.org/docs/PitchDetection
Bach Dataset – https://www.classicalarchives.com/midi.html
P5.js – https://p5js.org/examples/sound-mic-input.html
ML5.js – https://ml5js.org/docs/PitchDetection
Webaudio – https://webaudiodemos.appspot.com/input/index.html