For this project, I chose to look at a game, Semantris developed by Google’s Research Team which makes use of AI technology.
This game is based on word-association, and has two different modes which create different challenges. The premise of the game is that you have to guess word which the game AI will relate to the keyword given. Throughout my play of Semantris, I found that the relations are mostly natural, but there were a few unexpected results.
The word association training of Semantris was focused on conversational language, and relations. Therefore, Google tried to implement common questions and answers seen in human conversations. In order to gain data to use for Semantris, Google Research also looked back a to their project Talk To Books, a project which connects user input to passages from books.
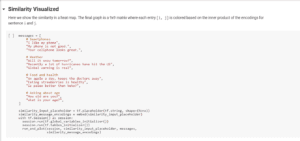
Seen below is a sample of code for the project which was used to help the AI understand some common conversational questions and their corresponding answers.
Semantris makes use of tensorflow’s word2vec model (link here), which is used to graph the semantic similarities between words. I found this to be an interesting way to gain quantitative data of a qualitative thought. As when you train an AI model, you need your data to be in a format which can be understood by a computer. Therefore, this model needed to move on from simply comparing strings by the characters they contain, and rather focus on the meaning of the word. Personally, I think that this would be incredibly difficult to graph, but Tensorflow has some examples of how they accomplished this (pictured below).
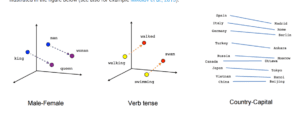 (just one example of how words can be related)
(just one example of how words can be related)
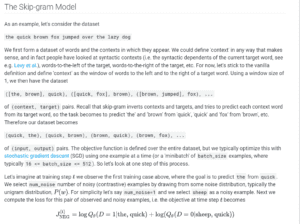 (another way to highlight how data sets can be formed)
(another way to highlight how data sets can be formed)
Along with this, when training this project, it was semi-supervised, so that the word pairs could be more conversational and natural, according to Google. When you play the game, the AI also understands pop culture references, and some word-relations which are only understood in conversation.
Outside of the boundaries of a game, Semantris could have other practical uses, especially when it comes to those who are learning to speak English. Along with this, the techniques used to code the game could be implemented in other text-AI to create more natural results. However, there is still some polishing which could be done.