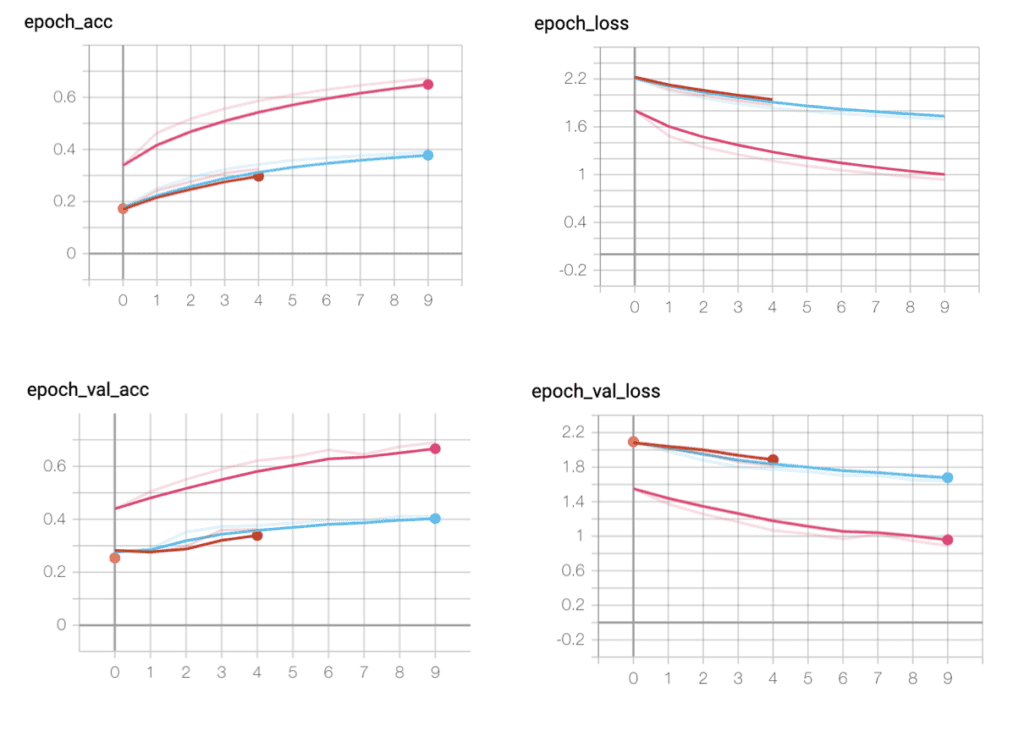
For the midterm project, I developed an interactive experimental art project: Dancing with a stranger.
Background:
Dancing with a stranger is an interactive experiment art project that requires two users to participate. The idea is that user A and B’s limb movements will be detected. User A will be in control of the figure A’s arms and figure B’s legs, user B will be in control of figure A’s legs and figure B’s arms. The result will be presented on the screen with a dark starry night background with two glowy figures dancing. Ideally, the webcam can also detect the speed of the users’ feet movements and switch through a set of different songs that match distinctive speeds.
The following photoshopped image illustrates the project. The white dots are used here to demonstrate the joints that will be detected on the users, and they will not appear in the final result.
The yellow figure’s arms and the pink figure’s legs are the movements of one user; the yellow figure’s legs and the pink figure’s arms are the movements of the other user.

Motivation:
The idea of this project was inspired by Sam Smith and Normani’s song “Dancing with a stranger”. When I’m listening to this song, it presents me with a picture that even though the two people are not familiar with each other, they are bonded by the music and therefore create a tacit, mutual understanding. In most dual games/ interactive designs, each player is asked to take full control of his/her character, I decided to pursue a different way. What if a person can only control half of the character, and only with the cooperation with another person, can they successfully create a beautiful dance together? That’s how this came to mind.
Methodology
To create this project: Dancing With a Stranger, I need the Posenet Model to detect two people and record their coordinates simultaneously but separately. The model records the left and right shoulders, left and right elbows, left and right wrists, left and right hips, left and right knees and left and right feet. After storing all the coordinates in the parameters, I create bezier through every three dots and simulates the limbs of the two users. I further used the nose coordinates of the two users to represent the face positions. When the body structure has been formed, I trace the trail of the figure’s body movement, so that when the figure moves on the screen, there will be colored trails tracing the movement. The last step for this project was to detect the speed of the two movements and switch between the fast and the slow song according to the average speed of the two people.
Experiments
This is the video of a single person demonstration (sound on):
This is a screenshot of the two people model:

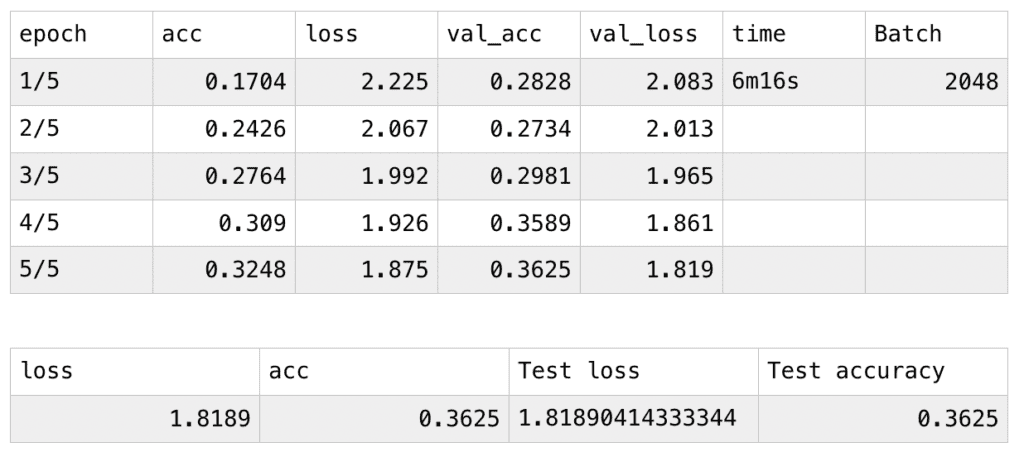
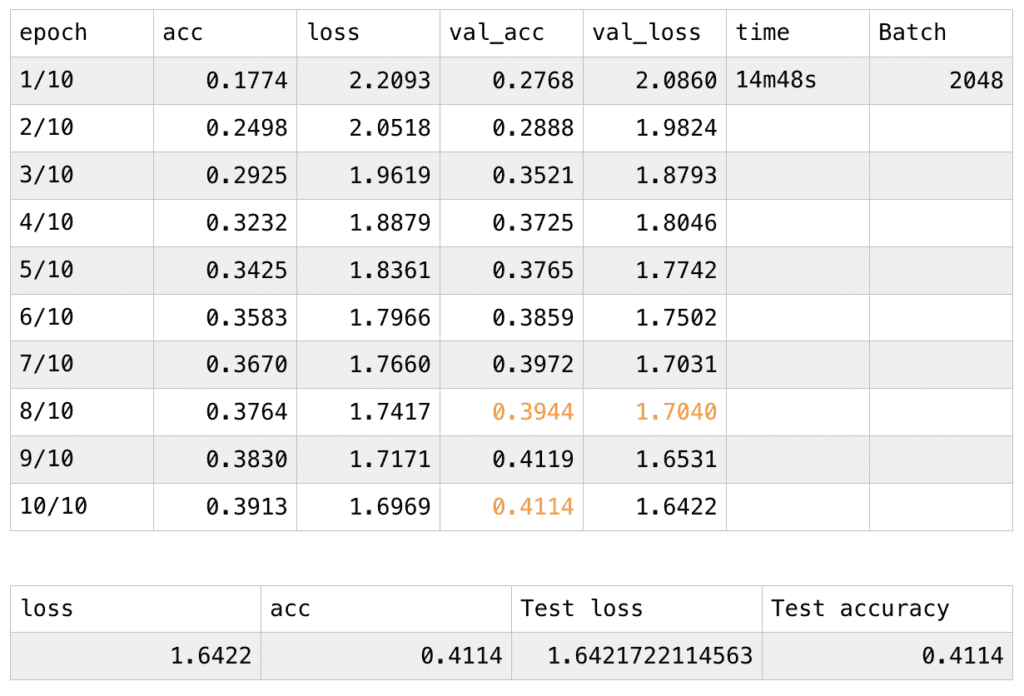
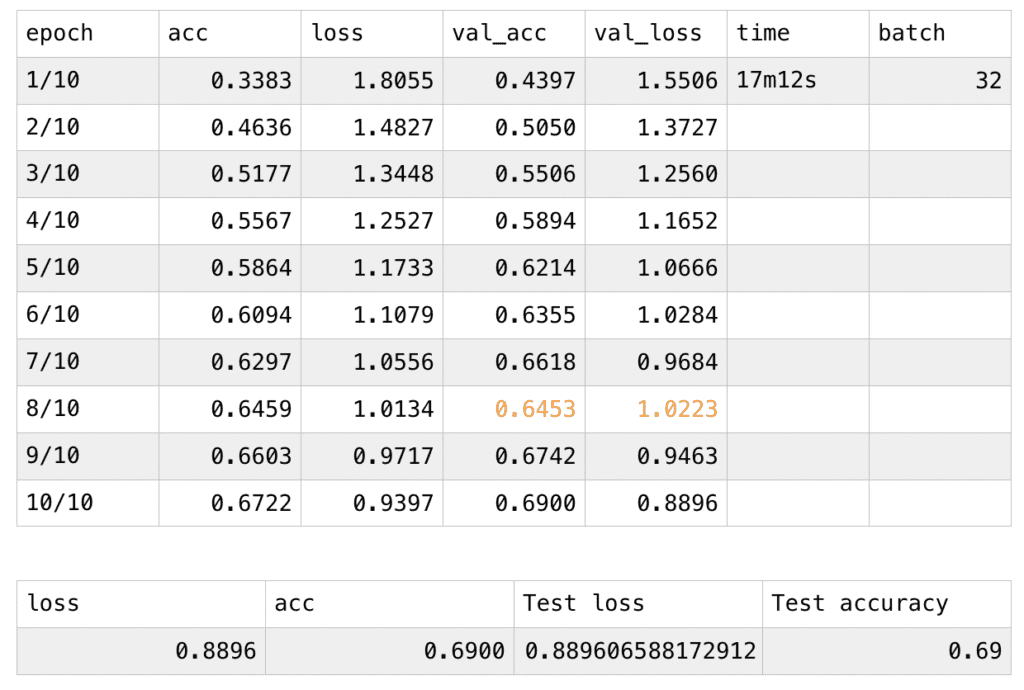
I started with accessing two sets of body coordinates in Posenet model. By console.log(poses), I am able to access all the data stored as objects inside different arrays within the poses array. Even though Posenet is distinguishing subject by subject, which means that they are classifying a full set of bodyparts’ coordinates within the array of subject 1 and another set for subject 2 and so on, it fails to be completely accurate when there are overlap bodyparts between different subjects. This is a huge obstacle for me since my primary goal was to apply a pair of arms of one person on the pair of legs of another person, without distinguishing the bodyparts clearly, the effect can’t be achieved and the same arms of the person will be on his/her own pair of legs. After I planted the bezier coordinates separately and attached them to the nose position, theoretically the model would work as I imagined. I then started a single-person-demo to work on the time-lapse effect.
Originally, I thought about building arrays that would store the previous 100 coordinates of each body part and display the 100 beziers at the same time, only in different opacity, but as I started to work on it, I discovered that the dataset is huge and confusing. I then consider changing the background opacity to create the fading effect, but somehow it doesn’t work on canvas, the areas that are covered by the trail becomes dark gray and remains on the canvas. I, therefore, decided to take the model down from the canvas and build it directly on p5.js. By using the function background(0,20), the opacity change successfully worked for p5. The movement of the figure leaves the trace behind it and it would fade away as time goes on.
I then started to work on the nose speed, I stored the coordinates of the nose 100 loops before and compare the distance between the two coordinates, this may seem not too accurate since the person can go back and forth then return to the previous coordinates in really fast speed, but since the interval is controlled as 100 loops, the possibility of this is very low. To refine this system, I can shorten the intervals and adjust the constant. To apply this to the two people model, I only need to calculate the average distance of the two distances and build the conditions upon the speed (defined by distance). When the average speed is above a number, the movingFast() is executed, vice versa. However, it didn’t perform well because every time the movingFast function is performed, the song starts to play, and it therefore constantly does the starting action. I then revise it to recognize whether the song is playing or not, if it’s already being played, the program would skip the play function.
Then I apply all techniques to the two people model, by calculating the average speed of the two noses, the program would switch between the fast and slow song. The two figures both consist of the color yellow and pink, indicating the body parts belonged to different users. When there aren’t two and only two people in front of the webcam, it displays a loading gif.
The loading page:
However, due to the problem of not classifying the two users’ bodyparts clearly, the two people model can’t perform as well as I imagined and would display the wrong color if it misrecognizes. It would also fail to locate the hips’ y position accurately. I suppose if a better camera is used for detecting, instead of the laptop’s webcam, the project would perform better.
Social Impact & Artistic Influence
For Dancing With a Stranger, my goal is to bring people closer by interacting with each other through dancing to music. For me, music and dancing are the things that break down boundaries. By combining technology (PoseNet and p5) and art together, I created a new approach to entertainment. The users (currently 2) are closely connected and influencing each other constantly in this project and together, they control the music choices——the music choice depends on the average moving speed of the users. We are living in a society where our lives are closely connected with technologies, there were lots of previous designs that aim at separating humans from their technologies in order to strengthen the human-to-human bonds. However, I don’t think that is the right attitude to deal with the booming technologies in our era, a better approach should be strengthening the bond among people with the help of technology. With p5, I managed to create an unrealistic visual effect of body movements. With PoseNet, I get to present what happens in the physical world on the screen and mirrored the movement in a non-human form. The users can, therefore, enjoy this process of being themselves but not actually themselves on a virtual platform.
Further Development
For further development, I’d like to transform my project that based on one pc to a platform that allows multiple users to use their own devices for PoseNet detection and mirror their images onto one public platform. The user gets to see their own image on a communal screen and perform the dancing together on that communal platform while using personal devices. Preferably, the color of the user’s figure changes after the model collect the speed of each user and compare them together, then assign different colors from the fastest to the slowest figure. I’ll also input more music choices into the model and implement different ways to decide on music. If possible, I’d also switch to different backgrounds instead of the all-black one. I would also improve the figures displayed on the screen by adding more p5 effect to the figures.