Background
My inspiration is a project called teachable machine. This model can be trained in real time. The user can make some similar poses as the input for a class. The maximum of the class is 3. Each pose corresponds an image or GIF. After setting up the dataset, once the user makes one of the three poses, the corresponding result will come out.
For me the core idea is excellent but the form of output is a little. There are also some projects about motion and music or other sound.
So I want to add audio as output. Also, the sound of different musical instruments is really artistic and people are familiar with it. Thus, my final thought is to let users trigger the sound of the instrument by acting like playing the corresponding musical instrument.
Motivation
My expected midterm project is an interactive virtual instrument. Firstly, the trained model can identify the differences in how musical instruments are played. Once it gets the result it will play the corresponding sound of the instrument. Also, there will be a picture of the instrument on the screen around the user.
For example, if the user pretended to be playing guitar, the model would recognize the instrument is guitar and automatically play the sound of guitar. Then there will be an image of guitar showing on the screen. The expected result is that it looks like the user is really playing the guitar on the screen.
Methodology
In order to achieve my expectation, I need the technology to locate each part of my body and to identify different poses and then classify them automatically and immediately. According to the previous knowledge, I decide to use PoseNet to do the location part.

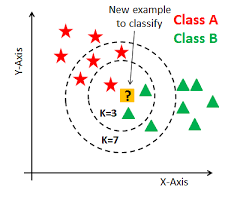
I plan to set a button on the camera canvas so that the users don’t need to press the mouse to input information and the interaction will be more natural. To achieve it, I need to set a range for the coordination of my hand. When I lift my hand to the range, the model will start receiving the input image and 3 seconds later it will automatically end it. Next time the user makes similar poses the model will give corresponding output. KNN is a traditional algorithm to classify things. So it can be used to let the model classify the poses in a short time and achieve real time training.
Experiment
Virtual button
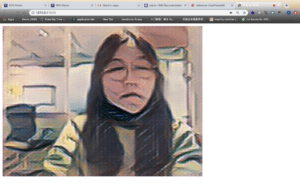
The first step to make my project is to replace buttons that users need to use the mouse to press by to the virtual button triggered by the human body part, for example, the wrist. To achieve it, I searched for the image for the button and found the following GIF to represent the virtual button. To avoid touching mistakenly, I put the buttons at the top of the screen which looks like the following picture.

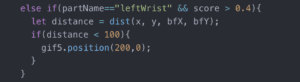
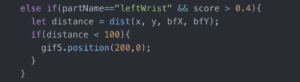
I used the poseNet to get the coordinates of the user’s left and right wrists and then set a range for each virtual button. If the user’s wrist approaches the button, the button will change into GIFs containing different instruments (Guitar, drum and violin). These GIFs play the role of feedback to let the user know they have successfully triggered the button.

After that the model should automatically record the video as the dataset. The original one is that if the user press the button once, there will be five examples added to the class A. For my virtual button, the recording part should run once the user trigger the button. However, I need to set a delay function to give users time to put their hands down and prepare to play a musical instrument. Because the model shouldn’t count the image that users put their hands down as the dataset. So I set 3s delay for the users. But collecting examples is discontinuous if I keep raising my hand and dropping it.
Sound
The second step is to add audio as the output. At first, I said if the classification result is A and then the song will play (song.play( ); ). But the result is that the song played a thousand time in 1 second. Thus, I can only hear noise not the sound of guitar. So I asked Cindy and Tristan for help, and they suggested me to use the following method: if the result is A and the song is not playing right now, the song will play. Finally, it worked. There was only one sound at a time.

UI
The third step is to beautify UI of my project. First is the title: Virtual Instrument. I made a rectangle as the border and added an image to decorate it. It took some time to change the size of the border to the smaller one. Also, I have added shadow to the words and added 🎧🎼 to emphasize music.

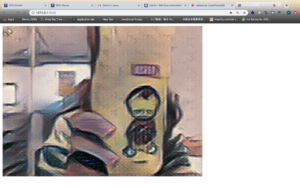
Then I added some GIFs which shows the connection between body movement and music. They are beside the camera canvas.



At last I added the border to the result part:

Problems
The problems I found in the experiment are as follows:
- The process of recording and collecting examples is discontinuous. It often gets stuck. But the advantage is that the user will know whether the collection part end by seeing if the picture is smooth or stuck. Also, the stuck image may have something to do with my computer.
- Sometimes the user might touched two buttons at the same time, but it is hard for me to avoid this situation through the code. So I just changed the range of each button to widen the gap between them.
- I have set the button to start predicting but it was hard for the model to catch the coordinates of left wrist. Sometimes it took a lot of time for the user to start predicting. Thus, I have changed the score from 0.8 to 0.5 to make it better.
- Once the user pressed the start button, there would be a sound of the drum, even though the user didn’t do anything. It made me confused. Maybe it is because that KNN cannot consider the result that doesn’t belong to any classification. The model can only consider the most possible classification the input belongs to and give the corresponding sound.
Therefore, the next step is to solve the problems and enrich the output. For example, I can add more kinds of musical instruments. And also the melody can be changed according to different speed of the body movement.
Social impact
My goal is to create a project to let people interact with AI in an artistic and natural way. They can make the sound of a musical instrument without having a real physical one. Also, it is a way to combine advanced technology and daily art. It provides an interesting and easy way to help people learn about and experience Artificial Intelligence in their daily life. In a word, it provides a new way of interaction between human and computer. I think this project can be used as a way to display the project in the museum and as a medium to bridge the viewers and the project.
Further development
The next step is to solve the problems happened in the experiment and enrich the output. And I need to fully utilize the advantage of real-time training in my final project. My idea is to give users more opportunities to show their thought and creativity. To let them decide which kind of input can trigger which kind of output. Also, I want to add style transfer model to enrich the visual output. The style of the canvas can be changed as the mood of melody changes. For example, if the user choose the romantic style of the melody, the color of the canvas can turn to pink and also there will be pink bubble on the canvas. But the most essential problem is how to let the users create their own ways of expression through the real-time training. How to make the interaction smoother is also important for the final project. Also, I want to take advantage of the sound classification to play the role of the visual button. On the one hand, the users can create their own sound command to control the model. On the other hand, this function can avoid the problem happened in my previous experiment. But I am worried that the model of sound classification can not work accurately enough so that the result can not reach my expectation.