Website: cartoon.steins.live
Github: https://github.com/WenheLI/cartoonGAN-Application
Methodology
-
- Model Struct
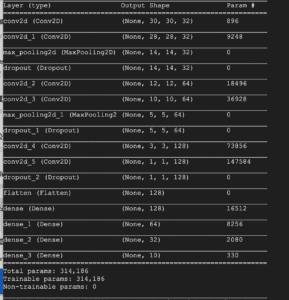
- To get the best cartoon-like style, we use the CartoonGAN[1] proposed by students from THU. As a typical GAN model, we need to have two separate nets, the generator, generating target images and the discriminator, telling the differences between target images and original images.
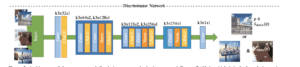
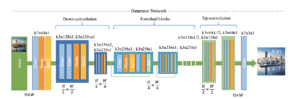
- The two networks structure demonstrates the complexity of this model. And we need to build up such a model in TensorFlow python and export the model to h5 format for the next step.
- In addition, the model requires some high-level layers and customized layers. If we want to make the model running on a browser, we need to replace those high-level and customized layers with pure Python and basic Keras abstraction. In this way, we can have a plain model that could be able to run directly on the browser.
- To get the best cartoon-like style, we use the CartoonGAN[1] proposed by students from THU. As a typical GAN model, we need to have two separate nets, the generator, generating target images and the discriminator, telling the differences between target images and original images.
- Model Converting
- After the previous step, we got a workable model that can be converted by TensorFlow-convertor.
- In addition, if the model involves customized layers, we need to either implement it on the javascript side and Python side. To make life easier, in this stage, I chose to implement it on the Python side.
- Web Procedure
- After the model is converted, we want to put the model on the browser with the help of TensorFlow.js.
- We want to have multiple models that allow users to choose from. How to design the operation logic remain a problem.
- We also want to implement the application on the mobile side either in the form of PWA or Wechat MINI program.
- Model Struct
Experiments
-
- Model Training
- Because of the complex model, hours of time are needed to put into the model training process. However, the model training is hard for GAN. We took a couple of days to put everything on track.
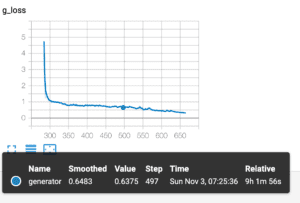
- Previously, we used a batch size of 128 with four RTX 2080ti. However, it makes harder for the generator to converge due to the large variance introduced by large batches. Below is the loss curve for 128-batch after one day’s training.
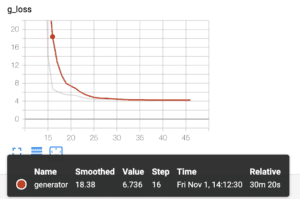
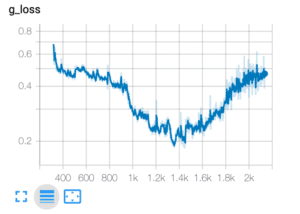
- After finding that the generator gets trapped within the local optimal, we shift the batch size to 8 for a better generator. Right now, the generator gets trained for 12 hours and the loss curve looks good. We still need days to see if it goes well. Currently, we can see the generated images have some edges on it.
- Model Training


2. Model On Web
Since I got some prior models for CartoonGAN, we could implement the web part along with the model training process. Two major problems we are facing right now are a large memory that the model consumes, which we can not improve any more in this case due to the complexity of the model.
Another problem is while inference, the model takes a large number of CPU/GPU usage which will stop the render of UI. To make the best of solving it, I introduce WebWorker to mitigate the rendering delay.
Also, the large memory consuming makes it hard to do inference over a mobile browser, as it will take more than 1.5 GB of v-ram.