The goal of this midterm project was to give the user a pokemon friend, or a pokebuddy based on some input. The pokebuddy would then sit on your shoulder and you’d have a photobooth like experience where you could click a picture and download it.
Evolution of idea:
Moving from collecting some feautres of pokemon to map to a buddy, I decided to have some machine learning fun here as well. After reading and researching, I decided to use Doc2Vec model to convert pokemon descriptions into vectors. The user would then be prompted to type in the description of the kind of pokemon they would want. This user description would also be turned into a vector. I would then try and find the closest vector to the user’s description and return the corresponding pokemon.
Process:
- Data collection and cleanup. First, I needed to be realistic about the pokemon that could be a buddy (size-wise). So I imported a dataset with pokemon features to MySQL, and ran a query that would only return the pokemon that were 75cm or below in height. I stored this in a text file.
- The next step was to actually collect pokemon description data. I searched and searched and searched but could not find ANY pokemon dataset which had descriptions or pokedex entries in there. So I did what any natural human would do – I wrote a scraper that would get this data from pokemondb.net.
- Scraping the data: I used requests and BeautifulSoup to get the data of the pokemon from the text file that I had created from step 1. The result was a text file with pokedex entries of each pokemon from different versions. There were roughly 10 or so descriptions for each pokemon so it was decent enough in terms of size of a dataset.
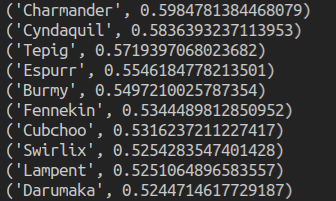
- Next, I had to create the actual Document vectors using doc2vec. I found out about gensim, which had an implementation of Doc2Vec, which seemed perfect for what I needed to do. Using some clever python code, I trained my model using the pokemon I had and used the model’s cosine similarity function to get the closest pokemon to it.
- I was now stuck – all my code was in python and I needed to create a way to get user input on the front end, pass it to the back end where the python logic would work and then return back to the front-end. On the front end would be the photobooth. This sounded like a dynamic web application. Flask was the framework of choice.
- Before actually creating a web-app that would combine the front and back end, I decided to nail the logic of what happens in the front-end. I used p5js to get a canvas and process video stuff. ml5js would be used for the poseNet model.
- I used poseNet to get the user’s shoulder and ear positions. using these and some simple mathematics, I was able to create a box on the users shoulder where the pokemon image would go.
- Finally, it was time to bring it all together. There are 2 different pages. The user enters a paragraph or document and this is sent to the backend to process. After classifying the user input, the server would load a new page where the front end would take video input. The user would then click a button and voila – two (not one, TWO!) pokemon buddies, one on each shoulder. There’s also a button to snap the image and download it.
Phew, that was quite long. Here’s how it looked:
*insert picture/video*
Improvements and moving forward:
No project is complete without problems and things that could be done better.
- The pokemon shakes too much! I’ve tried to change the parameters of poseNet so that the keypoint tracking would work better and not fluctuate so much, but no success. That’s the reason for the shaking.
- The design and layout. I’ve spent all my time working on functionality. I’d like to make it look a little better too, front end styling with css.
Concluding:
Overall this project was a fun and demanding experience at the same time. I’ve learned a lot, mostly through reading official documentation. Here’s a list of all the frameworks I used:
- Requests to GET webpages to scrape data off of.
- Beautiful Soup to parse the webpages and extract relavant data
- NLTK for word tokenization
- Gensim for Doc2Vec
- p5js for front end, the canvas, and the video input feed.
- ml5js for the poseNet model.
- Flask, a python microframework to bring it all together.
The code is here