Inspiration
In recent years, there appears to be a steady rise in the number of students that want to go abroad for master or phd programs to further their studies. In order to design a product, a user experience that caters to the needs of these users, in the past few weeks, our group has conducted market research, interviews, questionnaires to narrow down the pain points of our potential users, so that we could decide on our core task and work out a prototype.
Market Research
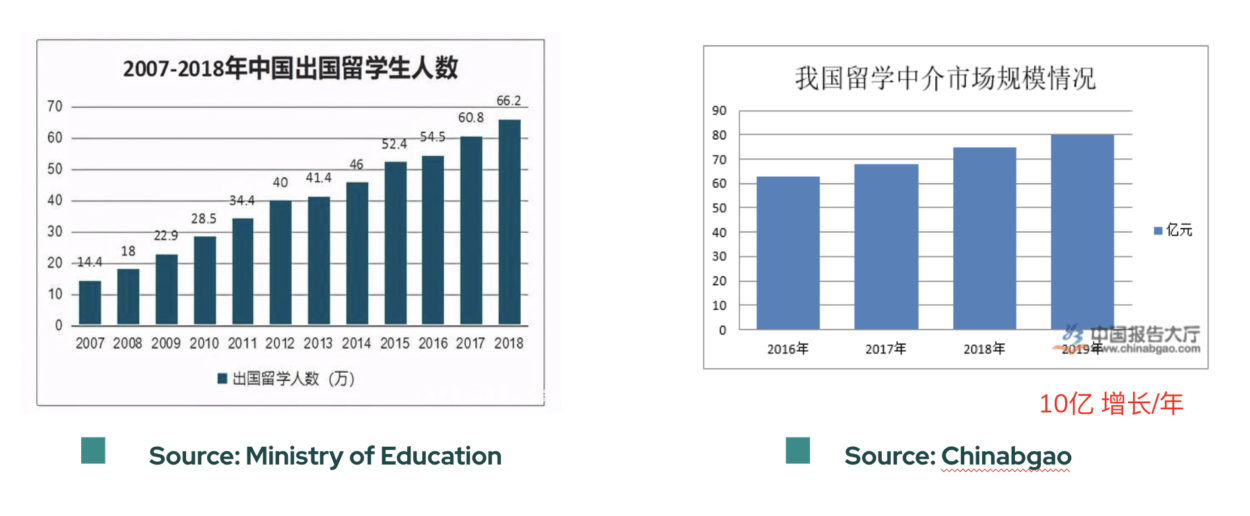
In order to learn about the market size, we looked into the data of the number of Chinese international students, the market value of the graduate students agencies and the increase in the number of international Chinese students each year from different data sources such as Ministry of Education, 白皮书,and Chinabaogao. We also searched for the anxiety and pains of the graduate applicants on social media like Zhihu and Douban. We find that graduate students often find themselves overwhelmed and anxious during the application process.
Questionnaire
Based on the results of previous market research, our questionnaire puts forward the main ways to obtain information as a participant, the reasons for choosing to study abroad, and whether relevant software and intermediary services have been used. Through the feedback of 76 participants, we found that most of them were college students or graduate students. They pay more attention to the quality of studying abroad and enrich their own life experience.
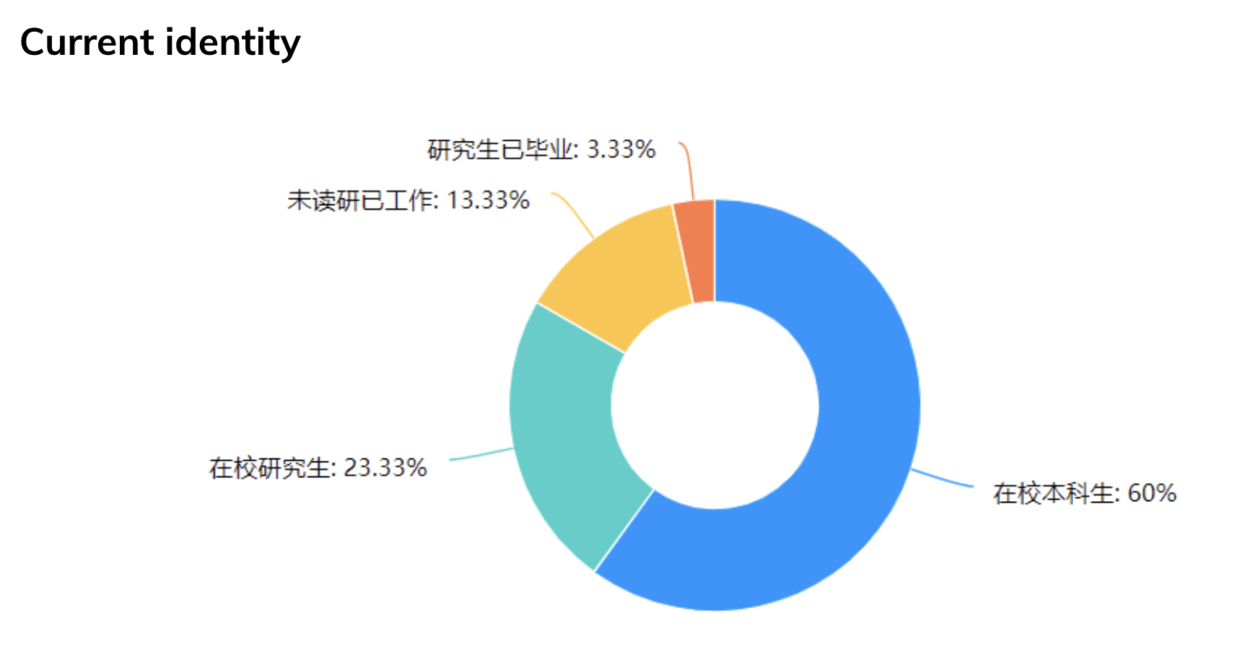
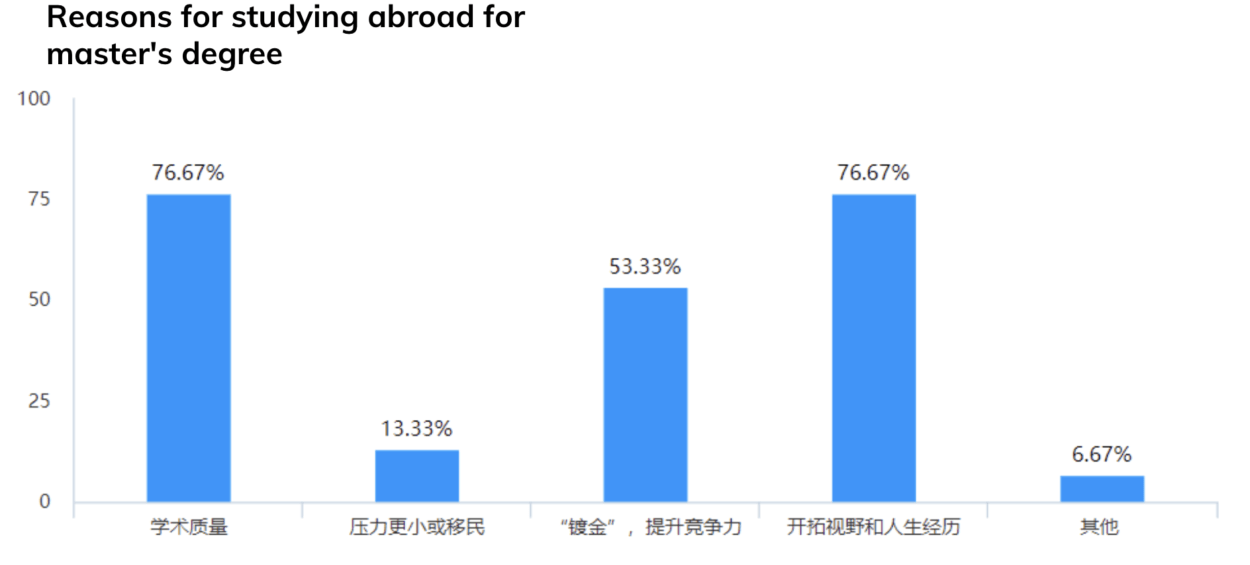
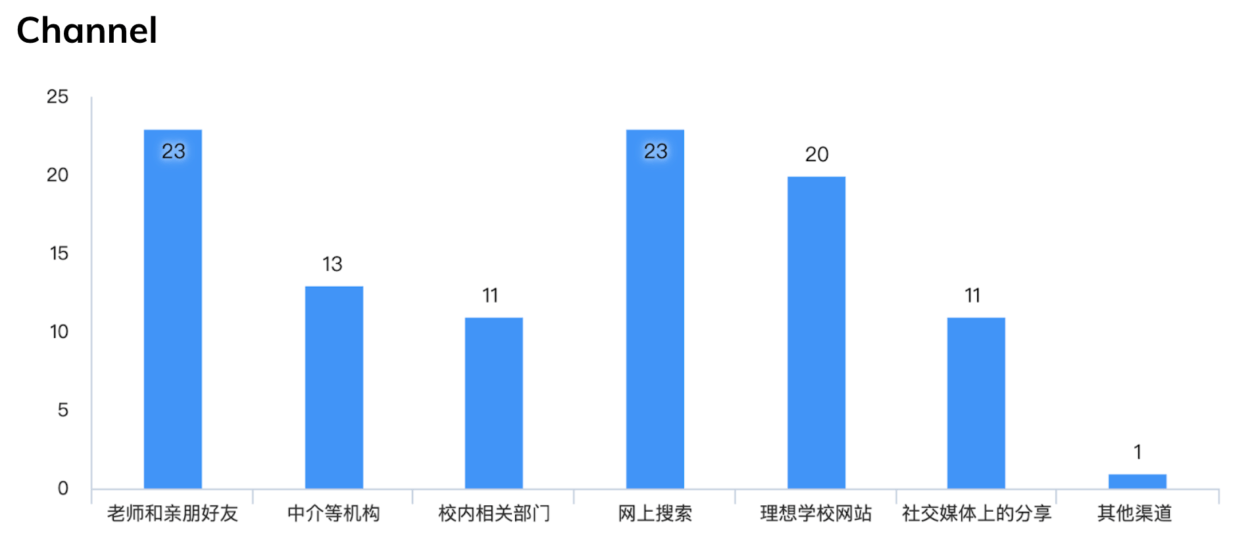
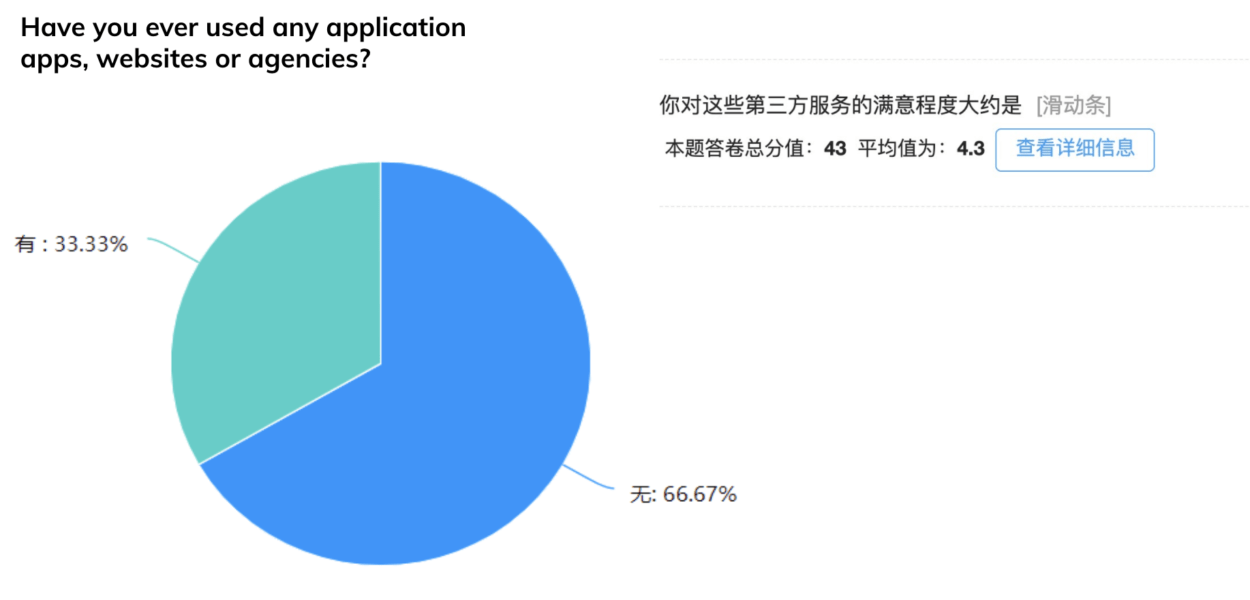
However, in China, the channels for obtaining information are not professional. Generally, information is collected through friends around and searching on the Internet without the help of relevant practitioners. Only one third of the people have sought advice from professionals. They prefer to have a professional institution to provide more detailed information, materials and self-assessment required by the school.
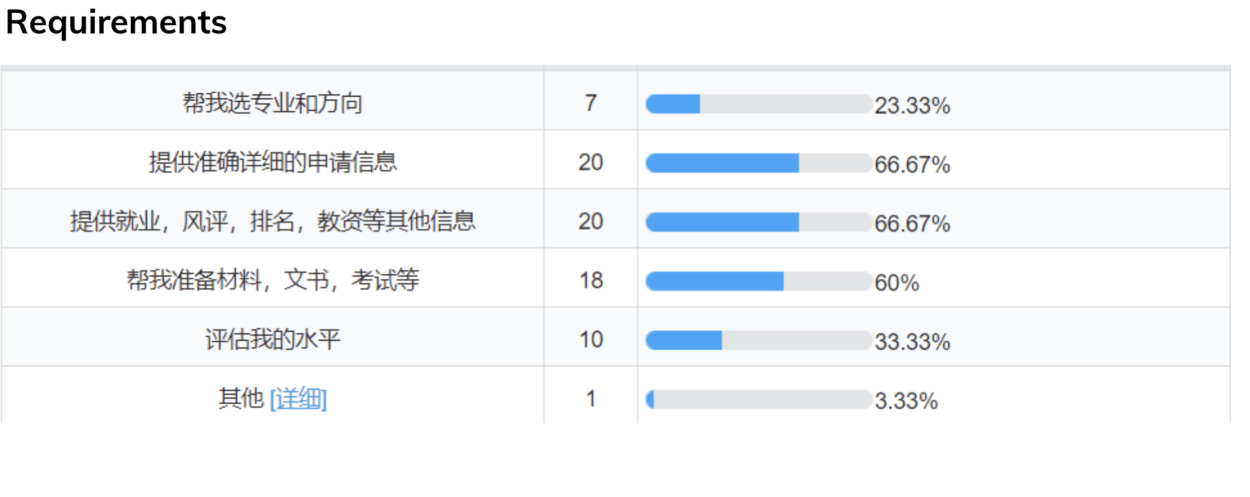
Interview
For the interview, we wanted to get the widest possible range of perspectives from our potential audience. Therefore, we conducted six interviews from an undergraduate student, a university professor, and a graduate student. Each interview was roughly 30 minutes and contained 21 questions. After the six interviews, we used dovetail to find trends in what users wanted and also potential pain points. We compiled all of these keywords into a word cloud and were able to get a visual representation of the most repeated points that our interviewees brought up. These were a lack of resources, too much time spent on searching, and a feeling of being overwhelmed and lost.

Pain points
Searching for graduate program information is too time-consuming, inefficient, and overwhelming for applicants.
Persona
Cai Xiaoqing
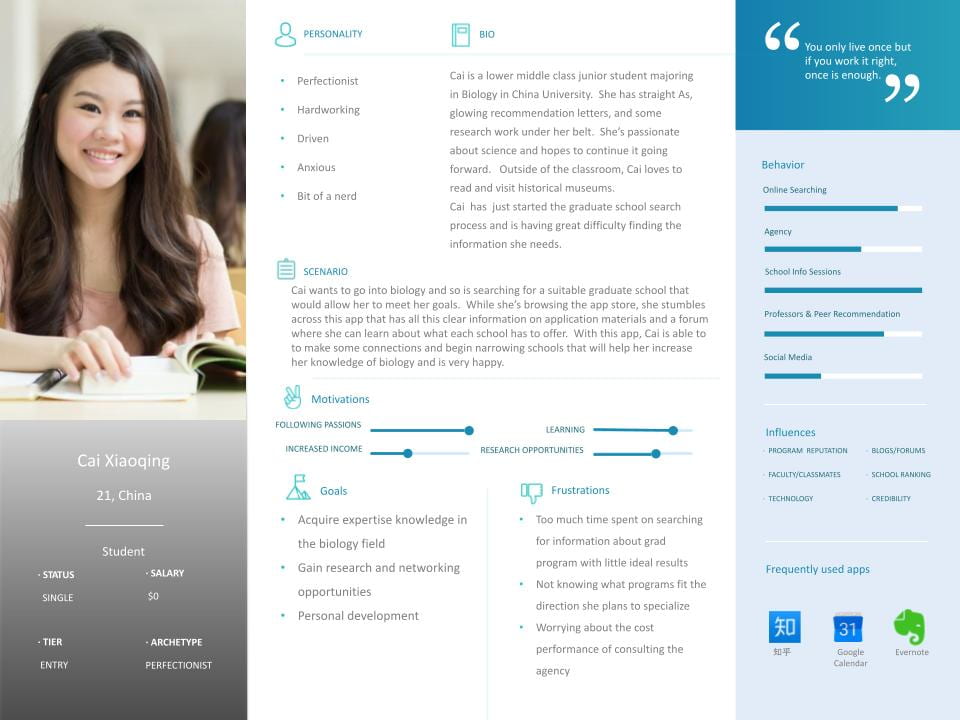
- Cai is our hardworking undergraduate student persona. She is a lower middle class student who dreams of going to graduate school and fulfilling her dreams of doing biology research. However, she is concerned about the expensive price of using an agency to help her look for schools and put together an application. Her own efforts to find suitable schools for her needs have yielded few results, especially as she is not yet sure where she wants to specialize in the Biology field.
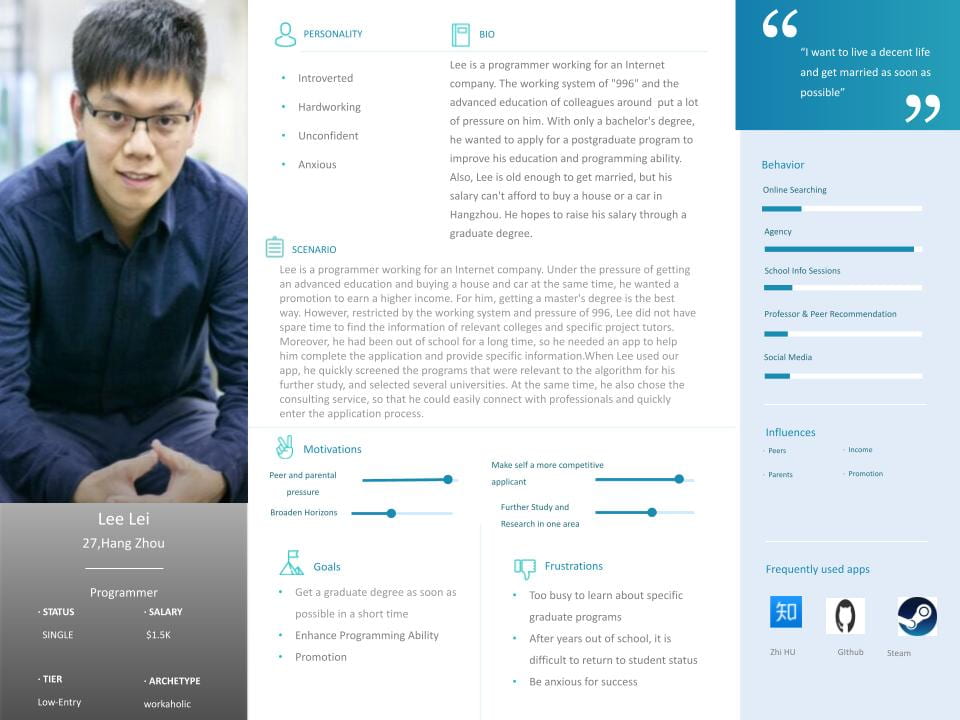
Lee Lei
- Lee is a programmer working for an Internet company. Under the pressure of getting an advanced education and buying a house and car at the same time, he wanted a promotion to earn a higher income. For him, getting a master’s degree is the best way. However, restricted by the working system and pressure of 996, Lee did not have spare time to find the information of relevant colleges andecific project tutors. Moreover, he had been out of school for a long time, so he needed an app to help him complete the application and provide specific information When Lee used our app, he quickly screened the programs that were relevant to the algorithm for his further study, and selected several universities. At the same time, he also chose the consulting service, so that he could easily connect with professionals and quickly enter the application process.
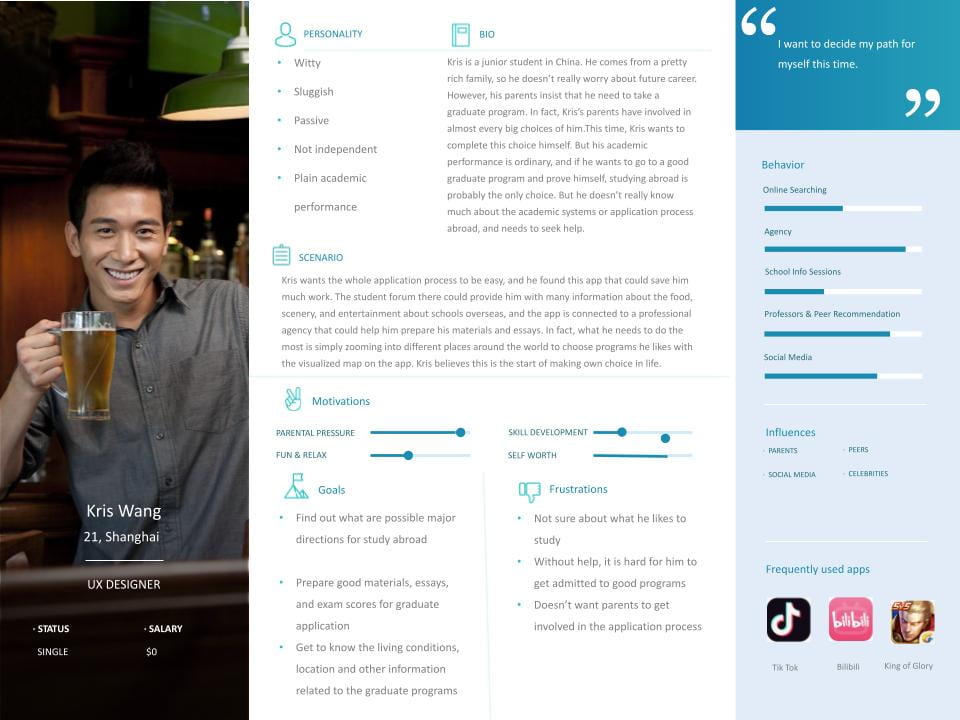
Kris Wang
- Kris is a junior student in China. He comes from a pretty rich family, so he doesn’t really worry about future career. However, his parents insist that he need to take a graduate program. In fact, Kris’s parents have involved in almost every big choices of him.This time, Kris wants to complete this choice himself. But his academic performance is ordinary, and if he wants to go to a good graduate program and prove himself, studying abroad is probably the only choice. But he doesn’t really know much about the academic systems or application process abroad, and needs to seek help.
- Kris wants the whole application process to be easy, and he found this app that could save him much work. In fact, what he needs to do is simply spending 15 minutes a day choosing he likes among the programs which the app recommends for him. Kris believes this is the start of making own choice in life.
Core Task
Provide graduate program applicants with accurate, comprehensive, and accessible information to help them find the program best suited to themselves.
Paper Prototype
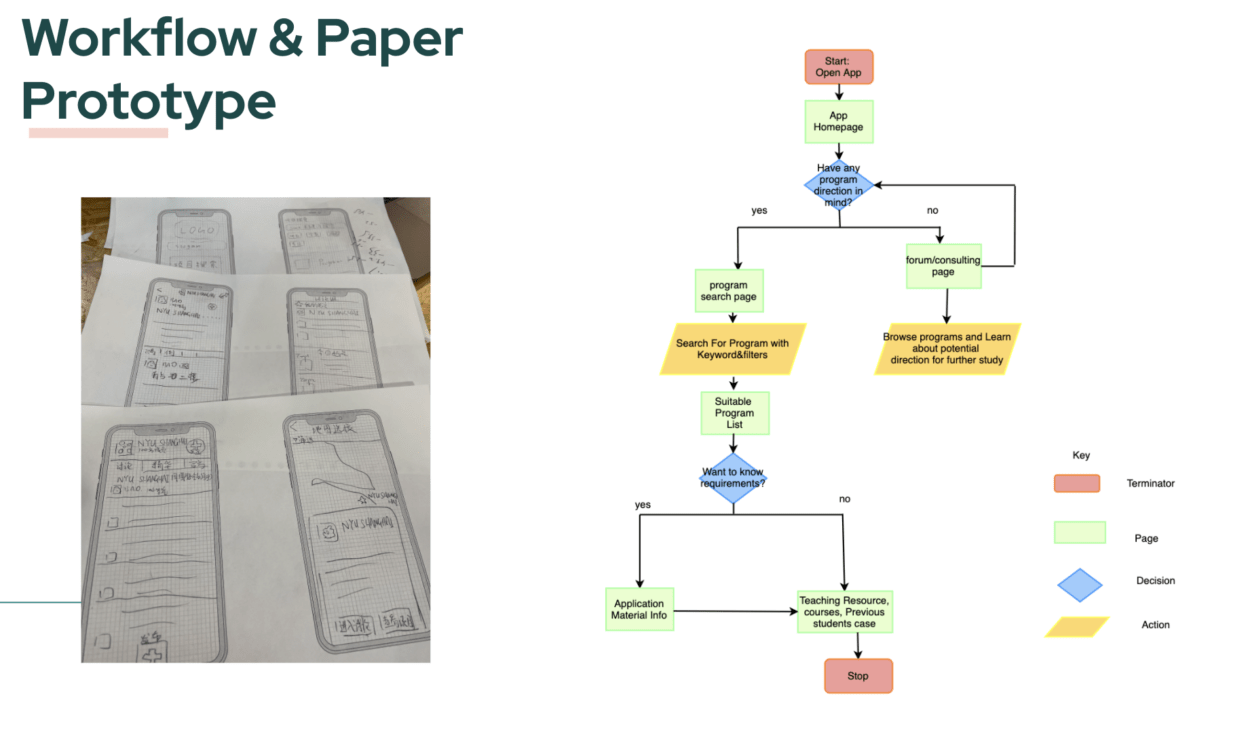
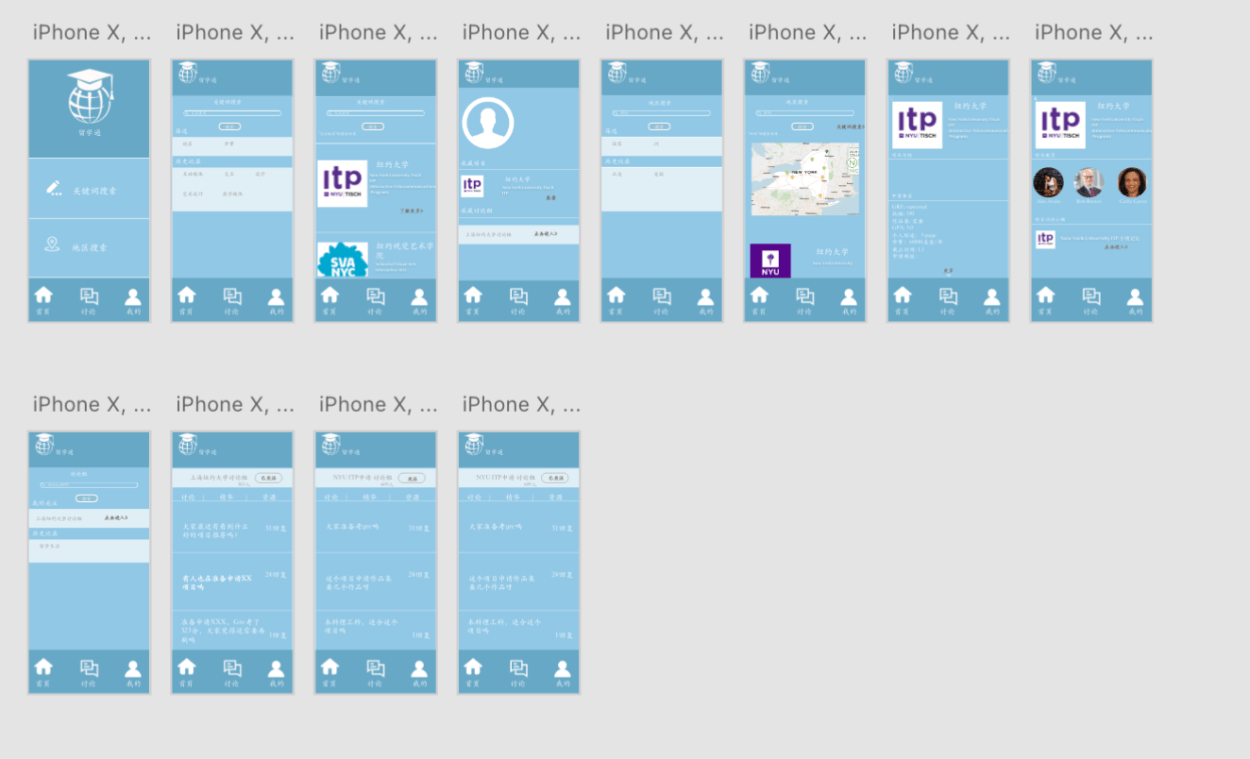
First Draft Prototype
User test
We got a lot of feedback including:
“Needs more information sections, such as sample courses, application deadlines, and alumni status.”
“The interface is a bit confusing. Why does the map and the program keywords search need to be separate?”
“The logo looks too big on the homepage”
Second Draft Prototype

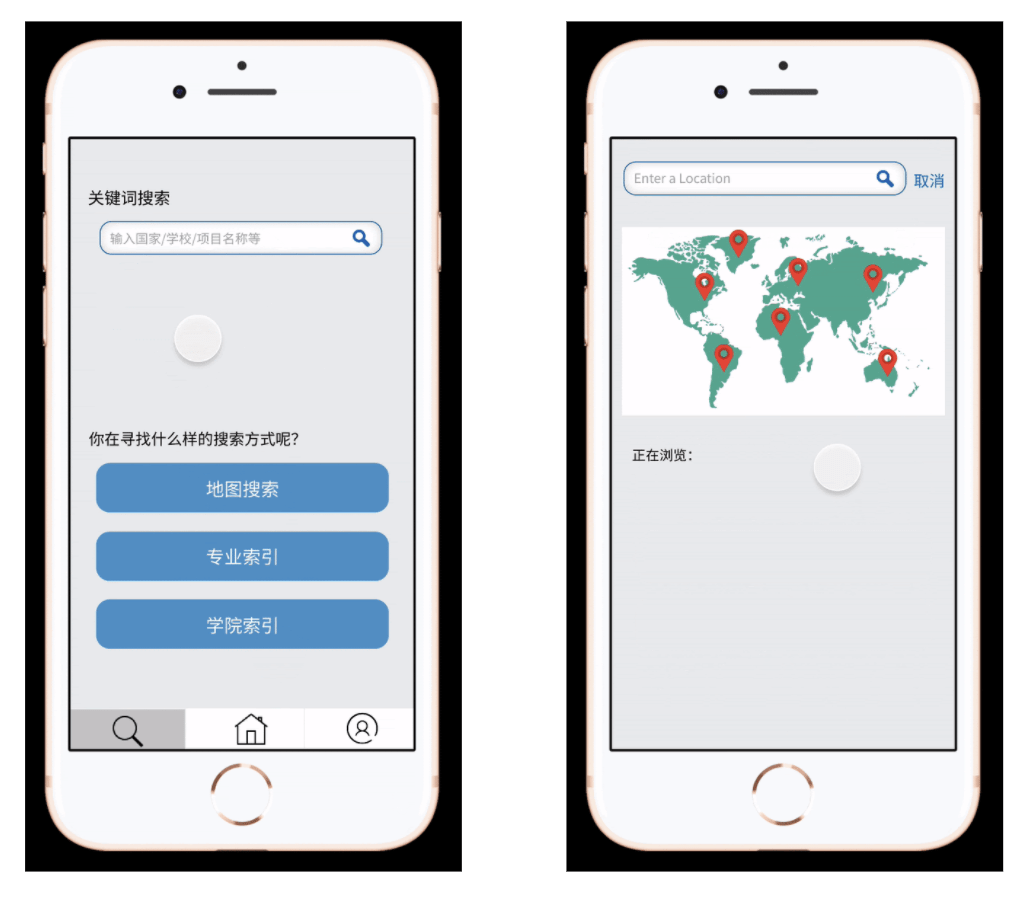
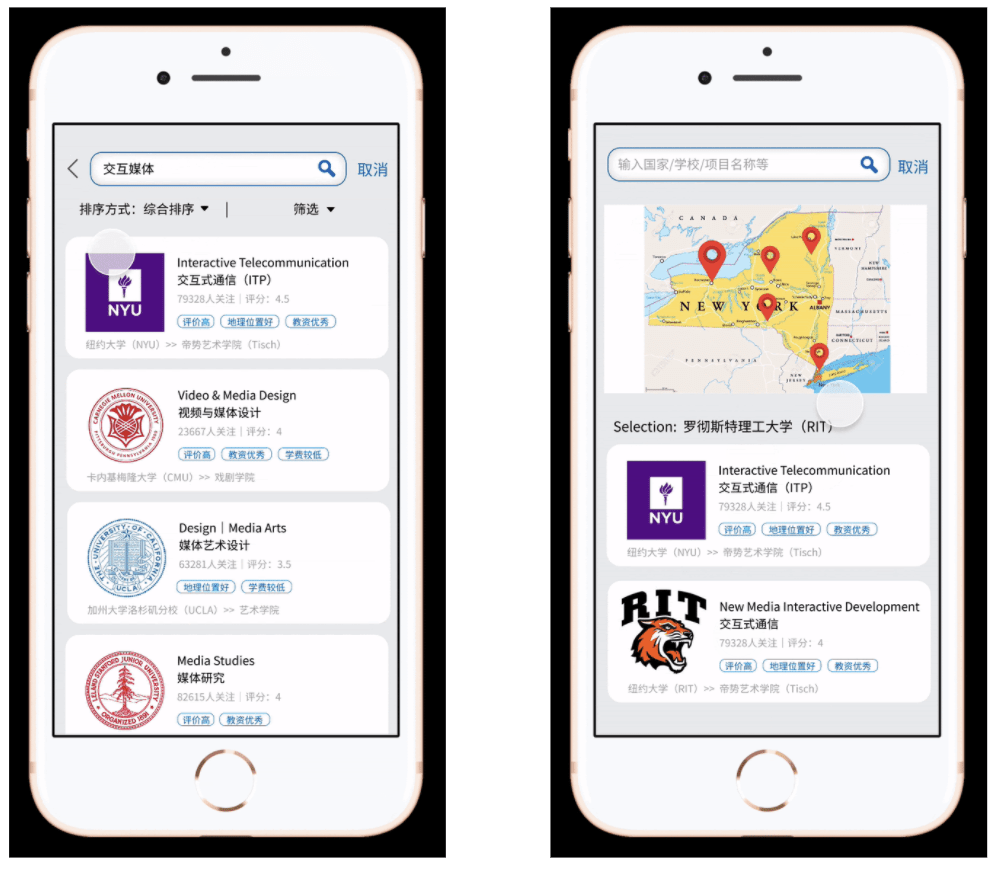
Focused Solution
- From the user test and class feedback, we realize it could be distracting for users if we just simply add multiple functions to the app. So we decided to really focus on solving one pain point, and after analysis and discussion, we concentrated on the hard searching process and tried to provide help.
Map Search
- The map search function allows users to find a school by interacting with a map. They can tap on an area on the map and it will zoom in and display a list of schools in said area as well as a map marker for each corresponding school. Users can tap on the map markers to find out which markers correspond to what schools.
Keyword Search
- Keyword search would be the most powerful search method, as we would give all programs multiply tags to match users’ keywords. With these tags, the search would be more accurate and the users and better compare different programs. Also we would provide various filters to satisfy different search needs.
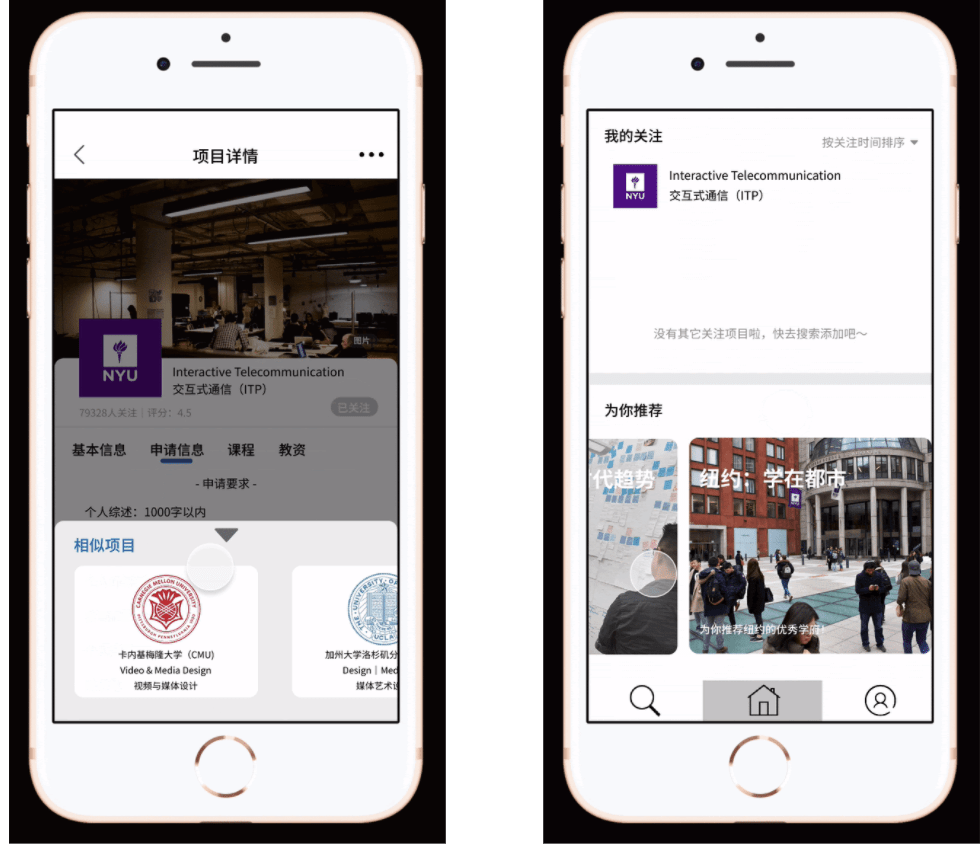
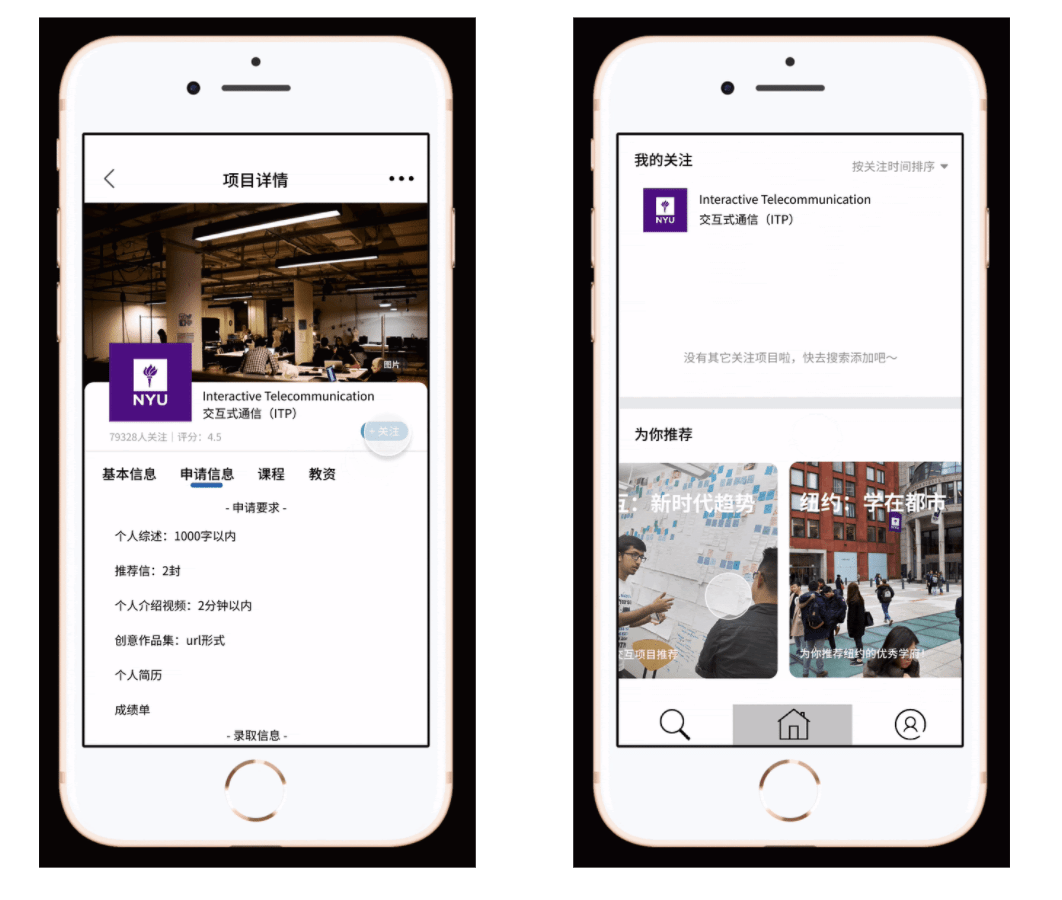
Detailed Information
- In order to solve the pain point, we would offer very detailed information about programs. We have prepared information including requirements, courses, professors and etc. that are urgently needed by applicants according to our previous research.
Easy Access
- One feature of our app design is that you can easily get access to the information. So besides simple search, you can also simply review the information once you add the program to your list.
Smart push
- In order to save user’s research time, we would provide smart recommendations for them. So you found one good program, you found them all. The recommendation would be based on the programs in users’ list and users’ information, so the more you use, the recommendation would be more accurate.