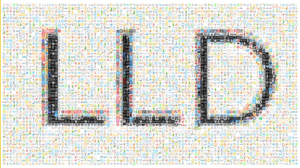The idea
Human has a long history of using logos. Those graphic elements severed as a good way for people to express their identities and feelings. Some logos that we are familiar today can actually date back to a very early age. Some logos remained the same as their original shape while some changed a lot through the process of evolution. For instance, the logo of Apple changed a lot and every new version can represent some changes regarding the identity of the company. From those long-lasting logos we can see that a good logo should be decent and simple and also consists of multiple meanings.


However, but every logo is well designed. We can still see a lot of logos that’s confusing and even scary. Those logos might fail to leave people a good impression of the company or the product they represent. Unfortunately, designing a decent logo might not be an easy job for ordinary people since it not only involves a lot of design principles but also requires a good skill in using those softwares such as AI and PS. It will be wonderful if we can design a product which can generate decent logos for users by simply pressing a button.

Technology
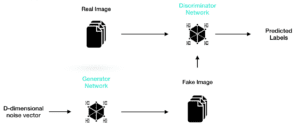
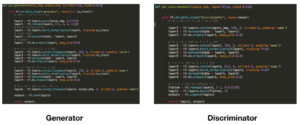
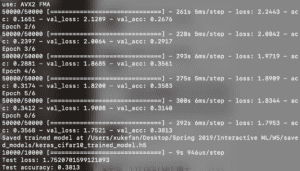
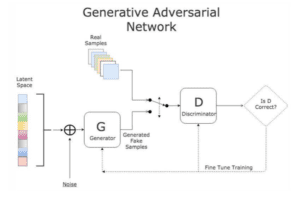
To automatically generate something sounds like what GAN can achieve. The GAN stands for the generative adversarial network. It consists of two neural networks which compete with each other. The generator will first generate some fake samples base on random noise, then the discriminator will be used to tell whether the sample generated by the generator is fake or not. Then the feedback will be given to the generator for it to generate samples of the better quality. Once the discriminator fails to tell whether the sample is fake or not, it indicates that the quality of the sample generated by the generator is good enough. By using this GAN network, I hope I will be able to train a model which can automatically generate decent images of logos to help normal people to design logos which are decent and impressive.
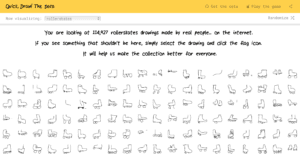
Dataset
The dataset I got is LLD (Large Logo Dataset) which contains over 600 thousands images of logos obtained from the Internet.
What I expect
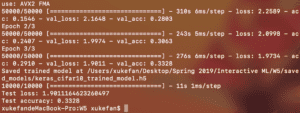
By using this logo to train a GAN network, I am hoping I will be able to get a GAN model which can generate high quality images of logos which are will designed and impressive. I believe this will save a lot of effort of ordinary people to have their own logos.
Reference
https://en.wikipedia.org/wiki/Neural_network
https://99designs.hk/blog/design-history-movements/the-history-of-logos/
https://data.vision.ee.ethz.ch/sagea/lld/