Project Name
Zihua / 字画: A Kanji Character Generator
Intro
Inspired by Xu Bing’s the Book from the Sky, in which he used strokes of the Chinese character to create over 4,000 fake Chinese characters, this project aimed to find a way of generating Kanji characters by using sketchRNN. I hope this project can serve as an interesting way for the audience to feel the beauty of Chinese characters and create something new.
Technique
To achieve my goal, I used sketchRNN. By adopting the Quick Draw! dataset, sketchRNN showed an amazing performance in reconstructing different types of doodle works created by users. The unique part of sketchRNN is that it has a sequence-by-sequence autoencoder, which is able to predict the next stroke based on the last one. When combining this feature with the p5.js library using magenta.js, it can draw doodles line by line like a real person.
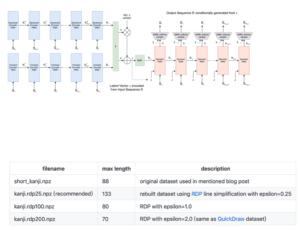
The dataset I choose is called Kanji Dataset, which contains 10000 characters for training, 600 for validation and 500 for testing. The reason why I chose that dataset is that all the sketches in this dataset are vector drawings which are the perfect form for training sketchRNN. Once plugin with this model, of course, the sketchRNN will not be able to understand the meaning behind those characters but it will try to use different types of stroke I learned to recompose characters. This process is quite similar to what Xu Bing did in the Book From the Sky.
Overview
In general, this project is made by three parts: Kanji generator, Kanji Sketch Board and the description part.
Kanji Generator


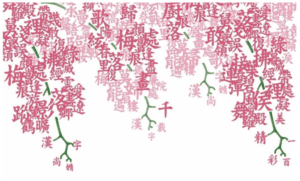
This is the first page the audience will see once they open the project. The generator will keep creating new characters in the background from top to the button. Once it researches the button, it will start a new line from the right side. It feels like there is a real person who is writing on the blank page, and it’s quite funny to watch. Few of the characters it writes are real ones, but most of them are entirely new characters. The shape of those characters varies a lot. Some have existing elements in it while some are completely made from no-sense strokes. The writing process echoes to my experience when I forgot how to write certain characters. It can be seen that sometimes the AI is quite confident with its memory, it composed elements in a nice form, but when it’s going to complete the rest of the character, it kind of forgets how to do it and randomly put some strokes on it. Once the characters fill all the screen, it will clean the full screen and start over. This part serves as a blurred background of the whole project, and in the middle of the project, it will be shown again.
Kanji Sketch Board
The sketch board will be presented to the user once they have gone through a brief introduction, it and also be directly accessed by clicking the brush shape button below the screen.
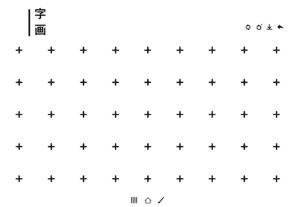


On this sketch board, the user will be able to create their own characters by drawing on it. Once they accomplish several strokes, the AI will help their finish the rest of it. There are three buttons on the top right. The most left will clear the whole screen, and the middle one will let the AI rewrite the stroke that it just wrote, the right one allows the user to save their work to their devices. The writing process is quite interesting. I found that the AI won’t respond to every stroke I wrote. For instance, if I wrote the Chinese character of NYU SH IMA department (上海紐約大學交互媒體與藝術) in the traditional form, only the character 紐, 約, 互 will trigger the AI to write the rest strokes. After a few experiments, I found some strokes become quite easy to trigger the AI, as I showed in the presentation. And it also requires some writing techniques. If using the mouse to write, it’s very hard to trigger the AI since the input should be rather smooth. So I used the iPad as the sketch board, which I will mention in the Other Works part. This might because the percentage of different Chinese character elements in the dataset is unbalanced, there are some elements have been used to train way more times compared to others, which makes them become more easily to be recognized.
Description Part
In this part, I gave some introduction of the Kanji’s history and my inspirations. I applied some web animation to present the content by using an editor called hype which allows me to create those animation effect and generate the html page.
Other Works
I posted the website to Github so it can be openly accessed by this link. The Chrome can achieve the best effect and the user need to scroll at the side of the page. My initial thought was that the user can access this page with their iPad so the drawing process can be done in a smoother way, but I then figured out that the borrowers on iPad will cash every time when I open this site while it works pretty well on my laptop. It seems that the compatibility of the magenta framework is not that good with iPad. So I removed part of its function and just kept the sketch board part. This time it works for iPad. So as Aven has shown in one of our classes, I saved this page to my iPad’s desktop so it looks like an app and the user can write with the Apple Pencil.
Future Works
The performance of the sketchRNN still has space to improve. The dataset is relatively small compared to Quick Draw! dataset. So when the user is trying to generate Kanji characters, there are certain limitations. First, the users’ writing must follow the style in the dataset but the fact is that each different people has their own style of writing Chinese characters. And also some strokes are hard to be recognized by the AI since their data size might be very small in the Kanji dataset. The best way to improve this part is to have a bigger dataset which has the collection of characters wrote by different people. To gather the data, the way used to collect the Quick Draw! dataset, which is to use a game to collect users’ drawing, can also be used to collect the writing of Chinese characters. Amazon’s AMT can be another way to collect those data. The shape of the strokes can also be improved. It could be better if those strokes can resemble the real Chinese brush style. And by using the style transfer network, the user can transfer their work into a real Chinese calligraphy work.
Inspirations
Monica Dinculescu, Magic Sketchpad
Xu Bing, the Book from the Sky
Ulrich Apel, Kanji Dataset