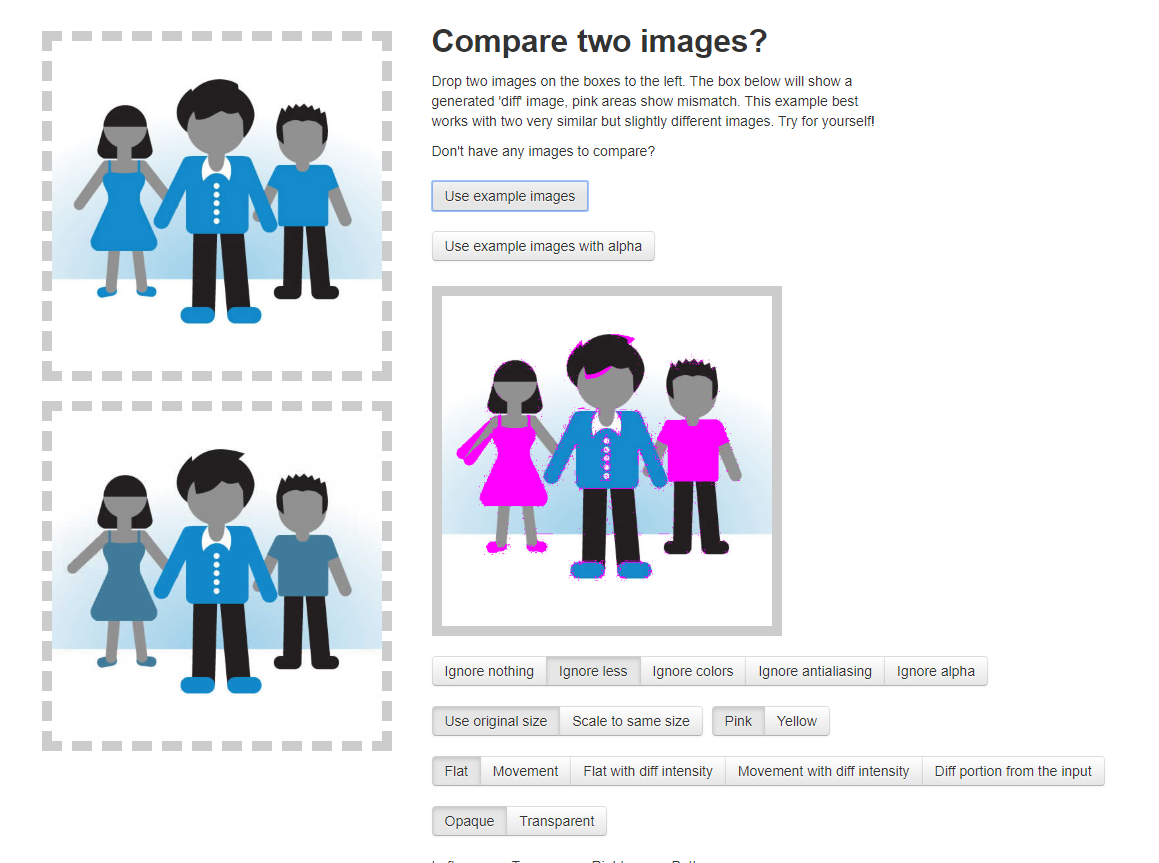
For my final project I wanted to continue advancing the work I did for the midterm, but go a step further in smoothing the process, as well as creating a better visual presentation of the material. I ambitiously wanted to create a neural network to recognize handwriting myself, but amongst other assignments failed to give myself enough time to do so, so I defaulted back to using resemble.js as I had in the midterm in order to compare the canvas to an image. With help from Professor Moon, I realized that I could actually refer to the p5 canvas as an html element, which drastically improved the smoothness of the project since I didn’t have to worry about the conflict between saveCanvas() running on a live server. (which normally reloads the live server, not allowing anything to be done after the canvas is saved to the machine.) I still ran into other problems with resemble.js that I did not expect. A problem that had deterred my progress for several hours was in the recording of the comparison data fed by resemble.js. Since I was trying to make a video game, in which you need to copy the given glyphs in the same order as presented, I wanted to store the ID of each glyph within an array. Then, when the player repeated the gylphs, it would be stored in a separate array then compared to the original. In order to do this, I put the resemble.js command inside a for loop, but it would turn an array specifically limited to 24 values into a length of 25, and only feed data into the 25th item in the array. I tried many ways to amend this problem, one being the addition of a setTimeout() into an empty function to delay the speed of each loop, amongst other attempts to change names and order of which it would call each function. After spending about 3 hours on this single problem, I found that the solution was simple changing the (var i = 0; i<24; i++) to (let i=0; i<24;i++).
Another problem in the same area of code was in the calling of the images themselves. In my last project I preloaded images and was able to refer them in the find difference command of resemble.js. This time, I kept getting an error asking me to import the images as blobs, and even after making sure that the information being referred to was specfically the data image, the problem turned out to be with the physical library as opposed to the canvas image.
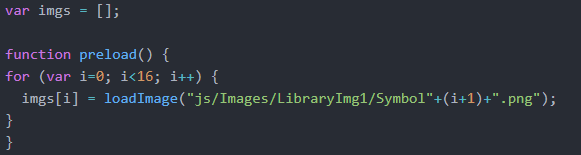
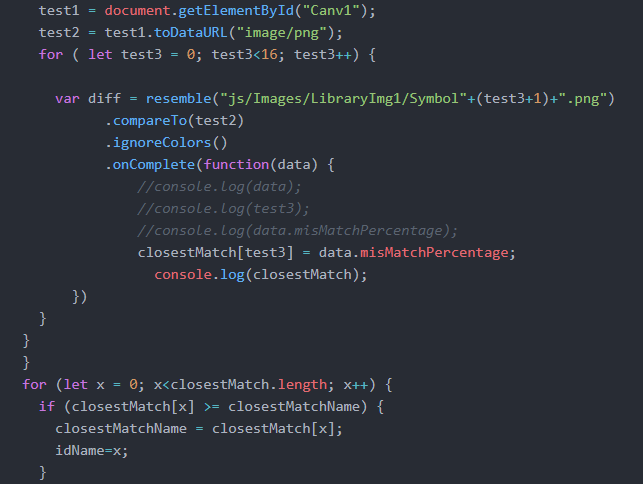
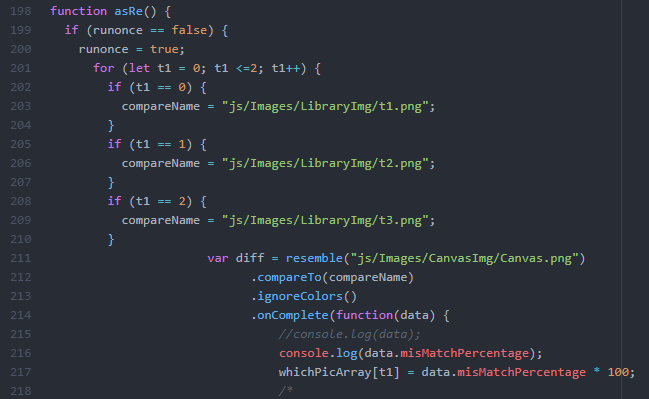
In the image above, I had originally simply referred to the image library with imgs[test3] instead of the full directory reference (“js/Images/LibraryImg1/Symbol”+(test3+1)+”.png”).
It was little problems like these that hindered me the most, in hindsight resemble.js was not only a rather impractical way of attempting to recognize handwriting, but was also filled with inconsistencies as such.
In the areas of code not pertaining to resemble.js itself, things went much more smoothly. Since I wanted the visual presentation and interactivity of the project to improve, I spent a fair amount of time trying to develop the game aspect of the project.
A part of the inspiration for the game actually came from the game “osu,” a rhythm game, where you need to hit circles as they pop up on the screen. There is a mod in the game that makes it so that instead of staying on the screen until the note is passed, it simply flashes for a fraction of a second and you simply need to remember where it was. This brought me to the idea of creating a type of game where you needed to rely on this extreme short-term memory in order to pass. About 2 months ago I had also gotten around to playing God of War 4, which included several puzzles involving Nordic runes. I liked the idea of basing the images off of those symbols, as completely random/made-up glyphs may have been hard to follow, and regular letters or Chinese characters might’ve been too easy and boring.
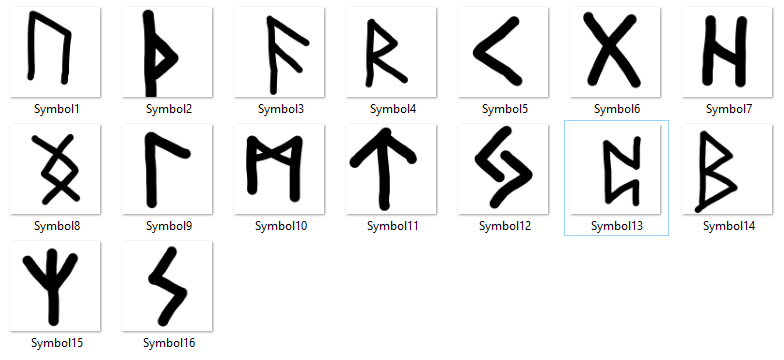
I originally tried supporting 24 different runes, and by manually training (appending more and more images to simulate different “handwritings” of the different glyphs) I quickly realized that resemble was not suited for heavy duty work. Even with the base of 24 images, in order to compare each one to the canvas took around 30-40 seconds for just one rune; and the starting level would already have 3. In order to cut down this time, I cut the number down to 16 but the idea of trying to make model more accurate failed as more pictures added significantly more time.
I also wanted the game to be able to go on forever like an arcade game, and the objective was simply trying to retain the highest score. In order to up the difficulty over time, I made it so with each level the speed at which the runes flashed became faster, resetting every 5 level along with the addition of an extra rune (3 runes lvl 1-4, 4 runes 5-9, etc). I made sure to specifically code everything to keep scaling larger with these numbers as well.
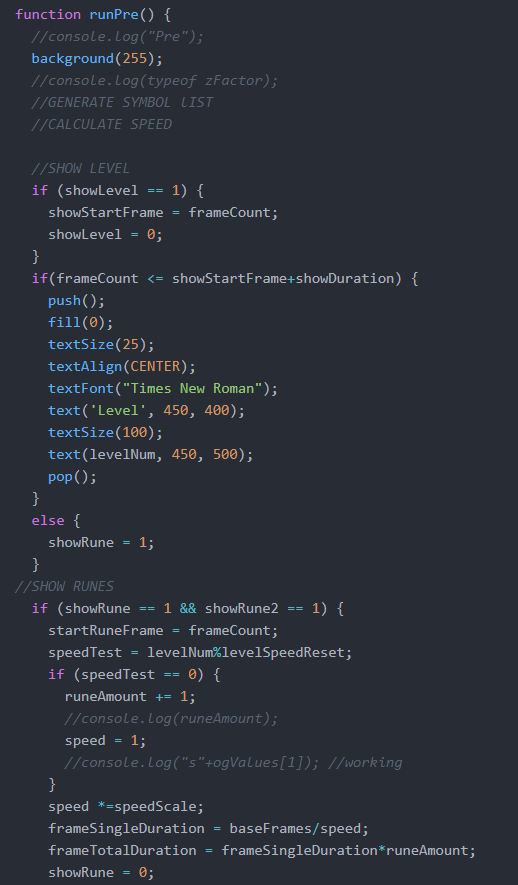
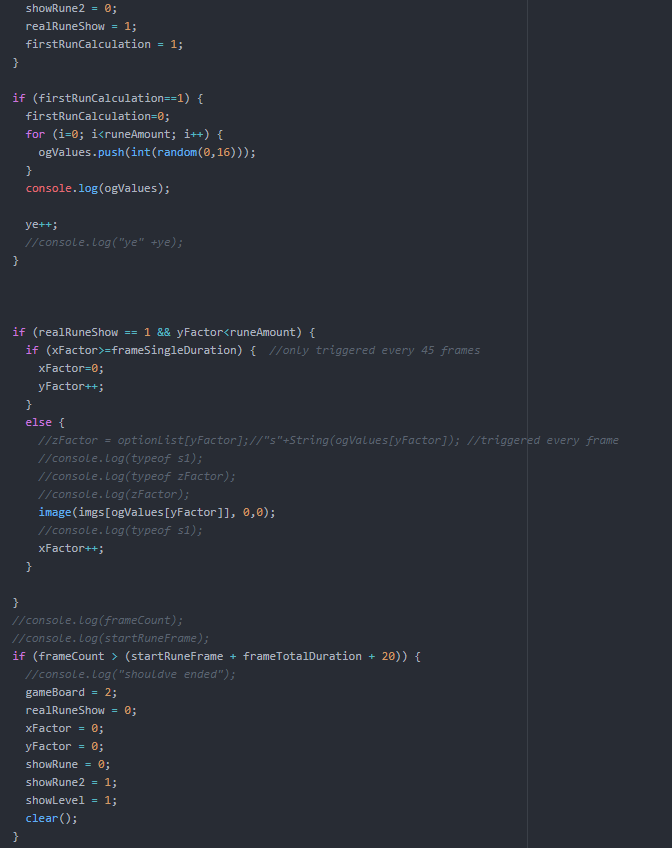
This was best exemplified in the gamescreen “Pre-game,” where I did all the calculations for how many runes to show, tracing what level you were on, and the speed at which the runes were shown. Overall, my disappointment mostly lied in my choice of using resemble.js instead of putting in time to truly develop a neural network capable of more accurately understanding what the user input. While I certainly had an unfortunately timed semester, with midterms dragged out right to the start of finals, I certainly could’ve and should’ve made sure to get an earlier start on this project in order to build a strong basis and make sure that the little problems I faced could be avoided.