Name
What If U Re Beauty (BeautyMirror)
GitHub
https://github.com/NHibiki-NYU/AIArts/tree/master/Final
Source
Proposal | Paper | Pretrained Model | Presentation
Tech Specs
In this final project, I mainly separate the work into two parts:
- backend: to be in charge of computational jobs and static servers.
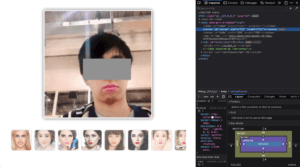
- frontend: to interact with the user, take the picture, send it back to the server, and display the result of the GAN network.
So, the pipeline of the whole steps are:
- The frontend takes a photo by webCam
- The frontend process and compress the image at frontend and post it back to backend
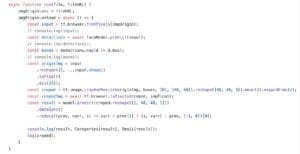
- The python server receives the image and transfers it to numpy matrix
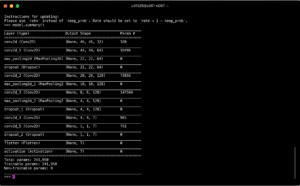
- The python server passes the matrix as input to TensorFlow backend and gets the result
- Again, the backend server transfers the output matrix to image and encode it to base64 string as a result for frontend request
- The frontend gets the base64 image and displays it on canvas
Development process
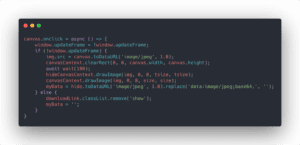
Firstly, I used a method navigator.mediaDevices.getUserMedia to create a context to activate WebCam. Then, I create a <video /> element and set its source to the context. The realtime camera should be displayed on the screen.
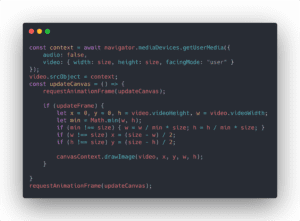
After that, by using canvasContext.drawImage(video, x, y, w, h);, the video frame could be extracted to the canvas. When the user clicks, we only need to pause the update of the canvas and send the image on canvas to the backend server.

Obstacles
There are many problems when I want to publish the demo to the world-wide-web.
Unable to connect to HPC
Since HPC in NYU Shanghai does not have a static public IP address, it is not possible to access the machine directly from the outside part of the NYU network. So, I need to find a way to break this NAT environment. There is an open-sourced software called ngrok, which allows users to run client mode on their NAT server and run server mode on their host server which has a public IP bind on it. When the user requests the IP address via the host server, the host server will connect the NAT server through the tunnel. The users, therefore, have access to content on the NAT server without a public IP.
WebCam only be allowed on https
Another obstacle is the WebCam can only be launched on https (Http over TLS). So, I use letsencrypt to issue a certificate for a domain. (I used my own domain in this scenario, but we can also use those public domain services like nip.io or xip.io)
When got certificates and keys from letsencrypt, we need the file privkey.pem for the private key and fullchain.pem for the certificate. The flask server can be start like this

Now the server should be started at :3003 with https encrypted.
Screenshots