Introduction
This final project is a continuation of previous midterm project and it simplify the fashionGAN model into more practical bodyPix and styleTransfer model. BodyPix is responsible for making body segmentation and styleTransfer is responsible for adding different patterns or transforming different colors on the input clothing images. Since in real cases, the same clothes would have different colors and texture patterns as well. So it is really useful if I could use styleTransfer to generate different styles of the same clothes.
Goal
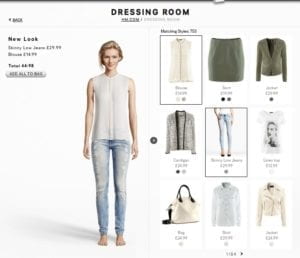
Continuing on my midterm project, I think I do not really need to stick with DeepFashion since the image synthesis part does not quite compile with my project idea. What I really want to create is like some e-commerce website already have. They have their own virtual online dressing room with 3D models generated by computer. When the user select different clothes, the model will automatically fit in different clothes. The conceptual webpage could be like this.
Demo
Here is a quite demo about the webpage I created. When pressing different keys on my computer, different clothes will be matched onto the upper body part of the model and different text description will display on the left hand side of the image.
demo
My Web Layout

Workflow & Difficulties
Here the techniques I used are basically these two models and here styleTransfer is based on ml5.js and bodyPix is based on p5. (Moon helped me to create the p5 version of bodyPix and I used this one instead of the original p5 based on Tensorflow.)
First of all, I worked on these two work stream separately and combined them into two linked webpage. But then wired things happen that every time I input the segmentation I got from bodyPix into styleTransfer, my webpage crashed for some unknown reason. I am not quite sure about the exact reason but both my newly trained styleTransfer model and existing styleTransfer model failed. But all of these models worked perfectly fine with other input images.
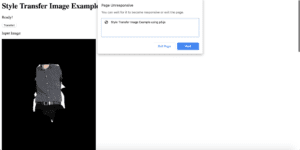
one of the newly trained model — a white T-shirt (input & output images)



Then I adjust my work plan and I think if I really want to get a better visual result, the best way I can do for now is to map the clothes images directly into the body segmentation I get from bodyPix. So here I cropped the segmentation images into rectangular shaped position and they map the clothes images into this position. Some of the results are really fit with the model while some are not. There are two reasons behind.
The first reason is that I used the rectangular shape to map clothes images rather than using the bodyPix outline. That may created some losses. The second reason is because I also use the rectangular shape of clothes images rather than the outline of the clothes images. Then in this way, I cannot perfectly map every outline of the clothes with the model. There is always some gaps in between especially in the shoulder part. Here are the four clothes images I used to map on the upper body of the model.




Future Improvement
1)Outline detection
In the future, the outline detection accuracy has a lot of space to improve. One simple method could be using bodyPix to get the segmented outline of the clothes image. But there are still lots of problems when matching the clothes images into the model. I think maybe different machine learning model similar but powerful than Pix2Pix may be really helpful since Pix2Pix basically detect the outline of one image. Also, I noticed that if I choose a model image which does not have a front body, then bodyPix will have a relatively low accuracy and the matching process will become tricky since you need to adjust not only the proportion but also the rotation of the clothes image. That part could be hard to realize in a 2 dimension way. I am wondering whether there is any 3 dimension machine learning model to refer to.
2)Video capture
I think the ideal way to make an interaction is to let the user stand in front of the camera and take an image of themselves. Then they can select different kinds of clothes from the computer that they would like to try on virtually.
Source & Code
https://github.com/tensorflow/tfjs-models/tree/master/body-pix
https://www.dropbox.com/s/1vhf7qjawa5wv75/iML_final.zip?dl=0