Title: A Transcendent Journey
Partner: Kyle Brueggemann

Project Description:
A Transcendent Journey reflects our desire to create a performance that transcends beyond the range of normative and physical human experiences, a spiritual and psychological one to be exact. Our intentions were to become pioneers in the realtime audiovisual performance scene by representing a concept through visual and auditory means that were previously only understood through schemas, thoughts, and words.
The choice of concept for this desire is none other than the 3-part theory on personality, founded and developed by Sigmund Freud, the father of psychoanalysis. Freud’s single most enduring notion of the human psyche was first analyzed and explained in “The Ego and The Id” in 1923, in which he discusses the three fundamental structures of the human personality: the id, ego, and superego.

According to Freud, the id is known as the primitive portion of the mind that harnesses sexual and aggressive drives, operating on the aspect of instant gratification while being fantasy-oriented. The super-ego then functions as the moral conscience, incorporating the values and morals of a society that are learned from one’s environment. Its function is to counteract the impulses of the id while persuading the ego (mentioned later on) to pursue moralistic goals as compared to the forbidden drives of the id. Lastly, the ego becomes the part of the mind that mediates the desires of both the id and super-ego, operating on reason and logic according to the principle of reality. It is in charge of working in realistic forms that satisfy the id’s demands while avoiding the negative consequences of society, as concerned by the super-ego.
While prominent, Freud’s theory describes these pillars as being mere concepts, not existing in any physical shape or form as parts of the brain. They are purely theorized systems, through which, people have only learned about and internalized through words and thoughts.
Kyle and I got to wondering how the mind would act if the ego were to disappear, foresay, the death of the ultimate ego. How would the mind react? How would the mind adapt? As partners, we found that this would be the perfect case to exercise our pioneering interests in audiovisual amalgamation. We were inspired to display the innate actions and behaviors of the id, super-ego, and ego by transcending them across sensory understandings of optic and auditory means.
Perspective & Context:
When pinpointing a project in the larger cultural context and perspective of audiovisual performances, it can be difficult, as we have learned in our many readings and studies of the art genre. Nonetheless, I would say that our performance leans relatively more to the side of Live Cinema. Live Cinema is just one minor category that falls under the wing, or as Ana Carvalho depicts, the umbrella that is Live Audiovisual. She describes Live Cinema as being one of many, that works underneath the Live Audiovisual “umbrella that extends to all manners of audiovisual performative expressions” (134).
Our project does not employ any large contraceptions, Lumia projections or the usage of aspects like water or shadows as used in previous performances, but rather, this project focuses much more on the aspect of story-telling and the conveyance of deeper representations. As Gabriel Menotti mentions, in Live Cinema, the creator is given a much “larger degree of creative control over the performance” (95); In which there is a significant increase in leeway for the artist to create what they desire and convey what they wish to inform, considering the reality that he or she does not need to follow momentary trends.
Though similar, our project should not be confused with the acts of VJing, for our emphasis on narration and communication articulates a much more personal and artistic essence for both the creator and the audience member. This is also why “many live cinema creators feel the need to separate themselves from the VJ scene altogether” (93). As live cinema designers and performers, Kyle and I were given full creative control over the audio, the set, the visuals and the fundamental concept behind the performance with no reliance on exterior sources, giving ourselves the upper hand throughout the entire showcase. With the visualization of Freud’s early theory of the human psyche, Kyle and I were able to communicate a cognitive system through the means of narration and story-telling that further allow the audience members to fall deeper into the performance and understand its meaningful representations on a much more significant scale.
Adding to the historical significance, our project was heavily influenced by the words, art pieces and beliefs of both the Whitney brothers and Jordan Belson. These audiovisual artists strived for the elimination of association to the real world by simply replacing it with the truths that lay hidden not in the natural world but in fact the mind. With the usage of their Eastern-metaphysics inspired visual art, both the Whitneys and Belson created ideal worlds, ones that relentlessly and perpetually explored “uncharted territory beyond the known world” (132) in order to reach a new perspective. Similarly, Kyle and I reflected the same perception in the transcendent nature of our own project.
Development & Technical Implementation:
Github: https://gist.github.com/kcb403/f694a176df373ad1c655bf9c54d261c0
Audio Creation:
Kyle volunteered to take over the aspects of the audio due to his experience in other classes. He used the application LogicProX, in order to create a base layer. He followed our proposed sectionized portions and stacked together audio after audio in order to have each section significantly differentiate from one another. Upon completion, Kyle selected 12 audio snippets for us to use in our patch. These sample layers along with the main base layer were exported and placed into the patch for further manipulation.
Filming – Base Video:
For the project, I was tasked with going around Shanghai and taking minute-long videos of things that stimulated me. I knew that I wanted to gather a collection of videos that utilized light, color and focus to their core, which is why I went to a number of places that I knew would fulfill these requirements of mine. I went to the Bund, I went to the Light Museum and I also went to the Space Plus Club located right in Pudong. At these various places, my eyes were set on any source of light that I could find.

In the midst of planning, Kyle and I showed an immediate infatuation in the usage of bokeh, which is the technique of rendering the lenses of a camera to create out-of-focus qualities in a photographic image, or in this case, video. Aside from just light, I was also on the hunt for any location I could gather bokeh from. I was able to collect a handful of videos that I admired, but after actually trying all of them in our patch, Kyle and I decided not to go with our original plan of using multiple videos for backgrounds and scenes. Instead, we would use just one video throughout the entire performance in a number of different methods in order to maintain a steady fps value and keep the Max crashes down to a minimum.
Patch (Video Base):
I was in charge of creating the effects for the base video with the help of Vizzie modules. I uploaded the 3-minute video by using the recommended process of HAP settings and connected that to jit.movie. From there, I started experimenting with the Vizzie modules we had come to familiarize ourselves with and focused myself on the categories of effect and transformative elements.
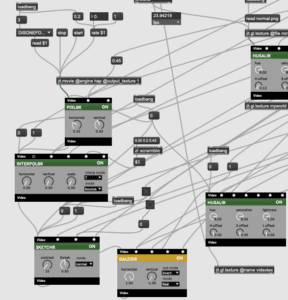
The modules I had chosen to work with for this project include and come in the following order: PIXL8R, INTERPOL8R, SKETCHR, KALEIDR and the HUSALIR. Aside from the KALEIDR and HUSALIR, I didn’t necessarily like what the output looked like when I used either the INTERPOL8R, SKETCHR and PIXL8R on their own, but as I played around with them and stacked them atop of another while understanding the effects of toggling the invert/regular settings, I started to like how I was able to achieve so many different visuals from just a total of 5 modules. Kyle and I felt that the video moved too quickly at times for our liking and so, we had to manipulate the speed of the overall video by attaching a rate $1 message to the corresponding jit.movie and then use float/messages that would toggle the speed between 0.2 and 1. This gave us the freedom to move back and forth between a set slow and fast speed on the MIDI board.
Patch (3D Head):
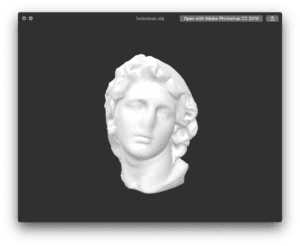
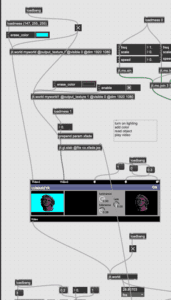
Using our skills learned from the 3D Model lesson this semester, Kyle and I thought that it would be memorable and smart to incorporate some sort of 3D head model in our performance, considering how our topic revolves around the human mind. The two of us looked for several models online, only to finally settle on an antique head, which we thought would fit in perfectly with the nightmarish style of our second act. Kyle was able to implement the 3D object into the patch using a jit.gl.model called myworld.
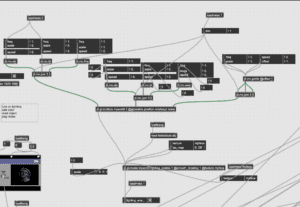
From there, we had the idea to manipulate the movement and placement of the head during our performance and so incorporated the three major attributes of the object into the patch: position, rotatexyz, and scale through a separate jit.gl.multiple command. From there, Kyle managed to find a fixed position for the head right in the middle of the screen and I managed to connect the speeds and scale attributes of the head’s various axis onto the MIDI board for our performance.
Furthermore, Kyle and I both agreed that the grey-scale head was too boring and mediocre for the visuals we had imagined, in which Kyle was able to solve the problem with the usage of a texture. With this uploaded texture, Kyle and I were able to manipulate the colors changing across the face through the usage of our trusty Vizzie modules. The modules in question include the HUSALIR and the TWIDDLR controller that would help us manage the intensity, hue, saturation, and lightness of our rainbow texture in realtime.


Patch (Tunnel Background):
As mentioned earlier, after much discussion between the two of us, Kyle and I thought that it would get too repetitive and dull to just use a different video background and manipulate it for the third and last act of our performance. Kyle then started to play around even more with the jitter program and was fascinated by the torus shape he was able to employ into the patch. With the torus object and with much arduous labor, Kyle showed me this tunnel visual he was able to create by expanding and zooming in on the inside of the torus, or as we like to call it, the donut.
I immediately liked the idea of using this tunnel-like imagery for how seamlessly it was able to fit in with the introductory audio to the specific act, in addition to its originality. Kyle managed to find the perfect settings for the ‘tunnel,’ and after multiple crashings of the Max patch, we decided that it would be best to set a loadbang in addition to multiple messages that would automatically send the desired values to our ‘tunnel’s’ attributes upon the opening of the patch.
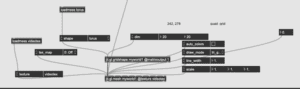
Patch (Video Mixing):
We then mixed the video components and the 3D object together through a LUMAKEYR. We attached the 3D model as Video 1 and then the other videos (Base and Tunnel) through Video2. Kyle and I wanted to move seamlessly from the base video to the tunnel base, which is something we were able to achieve through an xfade Vizzie module. Using this component gave me the access to fade between the videos using just the twist of a knob on our MIDI board. Later on, we realized that this xfade module was causing our patch to crash frequently, in which we sought assistance, and were told to use a different form of the xfade component, which greatly helped our crashing problem. We switched the connection between the MIDI board and the xfade module with the flonum component instead. Using the flonum worked just as effortlessly as the previous option.
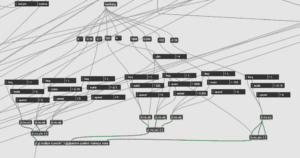
Patch (Audio Implementation):
We first laid out all of the 12 audio tracks carefully selected by Kyle into a straight line in the patch, followed by the base layer which was placed underneath them. We then connected each of the 12 minor tracks to separate AUDIO2VIZZIE modules in order to convert the data into Vizzie readable values. From there, the 12 tracks were then each connected to a SMOOTHR module before we began to attach them to the Vizzie modules we had already created in previous sections of the project. We then attached each of the 13 audio tracks, including the base layer, into 2 large pan mixers. These pan mixers were then finally led through a stereo output for the integrated sounds to be sent through our exterior speakers.
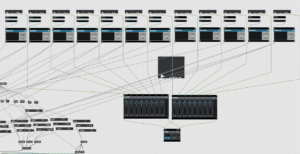
The process of connecting our pre-polished audio files with our Vizzie elements in the patch was quite possibly one of the most confusing and hectic processes of our entire project.
I was put in charge of working with audio to video connections. For this process, I used a method of trial-and-error. I would first listen to the audio track, understand its theme, understand its position in our 1/2/3 act performance, and attach it to different Vizzie modules until I found the effect that I admired most and thought fit best with the audio.
The first few tracks went quite smoothly, as all I had to do was attach the tracks to a VIZZIE effect that I liked most. It did get more and more difficult forever as I realized just how hectic the patch was becoming as I was moving these links and attachments from the upper-right hand corner to the bottom-left corner. I could have, however, avoided this situation by cleaning up the patch and moving the modules closer to certain sections.
Another difficulty I really struggled with was how as I was going through each track and its attachments, I realized how I needed certain modules to be turned on or off during certain parts of the performance. I then thought it would be best to replay the entire audio with the connections I had already made, and just as I had expected, many of the audio tracks did not appear visually as how I had planned because I needed to turn off or turn on certain modules along with the audio track that was being played. Confusing, I understand.
I created messages (1/0) for all of the Vizzie modules and buttons to go along with them, I attached the audios I wanted to correspond with the modules through the button, creating a bang that would be sent to activate either the 1 or 0 message box to the module. This, as you may imagine, only complicated the patch even more. I continued like this throughout the entire audio, until I was finally satisfied with how the entire 10-minute track sounded and looked.
Kyle and I did, however, manage to give ourselves a clearer perspective by adding only the essentials to our Presentation Mode. This helped us in our performance, but I still think that we could have tidied up our main patch as well.
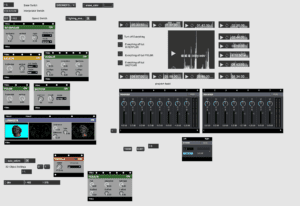
MIDI Board:
From there, I made difficult decisions as to which settings on the patch I wanted to manipulate in realtime through the MIDI board. I linked them through, connecting all of the base video effects to the sliders on the bottom of the board, and then split sections of the MIDI board between the movement of the 3D head along with certain xfaders and so on. I then took the professor’s advice and stuck masking tape onto the MIDI board and used a felt pen to write down certain notes and labels that would help me quickly identify the usage of certain sliders and knobs if I were to forget them during the performance.

Performance:
For our performance, Kyle and I wanted to keep things as clean and minimalistic as possible when it came to supplies and set-up. We had split our roles equally before the project, in which Kyle would be in charge of using the computer and therefore, the audio, while I would be in charge of using the MIDI board. These were the only two materials we brought to the performance aside from our much needed, USB-C adapter.
When practicing, Kyle and I put a lot of focus into scheduled actions, meaning that we were interested in every single minute that went into the performance. As we practiced and changed a number of things throughout the patch and our arranged timetable of events, the two of us finalized a transcript indicating specific timestamps and their corresponding operations. By using this transcript on my phone, in concurrence with a stopwatch playing on Kyle’s, we managed to pull off the performance just as how we practiced, in sync, in motion, and on schedule.

During the performance, things went quite smoothly, we started out well and ended on a good note. Throughout the 10 minutes, Kyle and I managed to follow through the entire transcript while keeping an eye on the stopwatch. There were times, however, where we had to tap on our phone screens in order to keep them on. We could have avoided this by pre-programming our phones to automatically stay on through a display that never sleeps.
Aside from our phones, I think that we performed great together. At that moment, and I think I can speak for Kyle as well, I was only focused on the stopwatch, the transcript, the monitor and my MIDI board. I was too nervous to look at anything else, not Kyle, not the professor not even the audience. I think that Kyle and I worked together gracefully, and were able to pull off the performance well by constantly giving each support through minor gestures, words of endurance as well as small thoughtful reminders.
There are of course, always improvements to be made to any project/performance. There were a few times in our performance, where I noticed that either Kyle or I would be acting too late or too early on our operations for the performance as according to our scheduled transcript. There were also times where I would be twisting the knobs in the wrong direction, which gave the opposite outcome we wanted on the screen. I also think that the head movements were sometimes either too abrupt or too slow when pitted against the screen and its audio counterpart, this could have been fixed by slowing down the rate in which the head moved. Also, I do think that the labels taped on to the MIDI board helped a lot, especially since we were performing in the dark.
The problems I mentioned could have been avoided or minimized with more practice on our part. More practice with the transcript, more practice without stopping and maybe even more practice in the dark or with an audience could have helped our situation. Nonetheless, I think that despite these minor mistakes, Kyle and I managed to move past them without panicking or accidentally indicating to the audience that we had made a mistake.
Some of My Favourite Moments:
Conclusion:
Since the initial proposal we created for this final project, Kyle and I have made several changes to the presentation, production, and vision to the overall product. While our main research and connection to real-time audiovisual performance did not change, our proposed plan has gone down a much more minimalistic path, as we had been advised to during the proposal hearing. We were told to minimize our sections down to a smaller amount in order for us to truly focus on them and create the best outcome from each of them, which is exactly what we did.
The creation process went smoothly in the beginning, for Kyle was able to work on the audio compilation he fairly enjoys and I was given the opportunity to once again, go out and explore Shanghai and videotape what I deemed to be visually stunning. The creation process in Max may have been the most arduous portion of the entire project, but it was also one of the most stimulating moments in the entire process. I was determined to fix any problems that arose and I was determined to use my knowledge and skills to the max. The execution of the project at Elevator was just the icing on top, I was super nervous before going up, but who wasn’t? I was lucky enough to have a hardworking partner like Kyle and was grateful that we had practiced enough to create a visually-stimulating performance that we were both satisfied with. There is, however, always improvements to be made, but for the most part, I really enjoyed the entire journey, the entire “transcendent journey”.
I learned of the importance of placing trust in your partner and the importance of splitting certain roles in order to allow one another to grow and take responsibility of their actions for the greater whole. I discovered a deep interest in audiovisual performance and an appreciation for the arduous planning and work that goes into each VJing/audiovisual/live cinema performance.
I believe that together, Kyle and I succeeded in creating a 3 act performance in correspondence with the id, ego, and superego of Freudian theories. With 3 distinguished sections like ours, I believe that we were able to reflect the distinct attributes of the psychodynamic theories as mentioned earlier.
I wished that Kyle and I could have taken the time to organize our patch, like in our presentation mode. I feel like this is something we struggled with, but due to time and lack of understanding in its importance, we were unable to keep the patch clean and refrain ourselves from becoming confused and muddled by the chaotic imagery that was and is our patch. I believe that Kyle and I could have also benefited from more practice before our performance at Elevator, this way, we could have been more comfortable with our selves, and felt more in sync and in tune with our music. I felt that during the performance we were somewhat stiff, which may have also been because of stage fright. Nonetheless, I am confident that more practice could have done more positive than negative to our overall project.
Overall, I am very satisfied with the outcome Kyle and I had created for this final project of Realtime Audiovisual Performances. Going into the process, I was very hesitant and timid about the scale of the entire performance, but as I worked through everything step-by-step, alongside the schedule we had created for the project, things didn’t seem as terrifying as they did in my head. It was a fun and stimulating process in which I got to learn even more about the planning and impacts of realtime audiovisual performances.
Furthermore, I was glad to have been able to produce a visually and auditorily stimulating performance that depicted a concept that had not yet been created in any form other than thoughts and words. I feel like some sort of courageous pioneer in this aspect, which is what I think is an important attribute when one wishes to become a part of the realtime live audiovisual community.
Works Cited:
Carvalho, Ana. “Live Audiovisual Performance.” The Audiovisual Breakthrough, 2015, pp. 131–143.
Menotti, Gabriel. “Live Cinema.” The Audiovisual Breakthrough, Edited by Cornelia Lund, 2015, pp. 83–108.
Thames, and Hudson. “Cosmic Consciousness.” Visual Music: Synesthesia in Art and Music Since 1900. N.p.: n.p., 2005. 125-61. Print.