Introduction and Project Rationale:
I had a very clear idea of what I wanted to do for my final project for Communications Lab for a while. I had been exploring different facets of Machine Learning for most of the semester, and while doing so, one particular topic struck my fascination more than any of the others – Neural Style Transfer. What this does is as follows – imagine you have two images, Image A and Image B. What if you wanted the content of Image B to be presented in the style of Image A? This is precisely what Neural Style Transfer facilitates. But, what I wanted to do was one step further, what if you could have an entire video stream be relayed back in some different style? And, what if the video is reactive to changes in your environment? When thinking about the latter question, I thought of different ways the user can spark some sort of interaction. Could they maybe press a button that switches styles? Or, maybe as slider that you drag that progressively changes styles? I thought about this for a while, but none of these screen-based options seemed to excite me much. If I was the user presented with a strange video feed, I wouldn’t want to have to do much to cause a dramatic change in the behavior of the feed. It needed to be reactive, it needed to be responsive in the strangest, yet most natural of ways. What sort of stimulus could I capture that would be reflective of changes in the environment? Throughout this semester and what we have been discussing in Communications Lab, we have been prompted to think about different ways of facilitating interaction. And through these discussions, one of the lessons that I learnt is that we all have different perceptions of what “interaction” really means. To this extent, my idea of interaction is that even a small stimulus provided by the user should be able to prompt a great change in the behavior of the project. This is something that I wanted to really emphasize upon in my project.
After thinking about this, I decided that I could do away with any buttons or on-screen elements, and make the most of the video feed, in particular, the user and his environment.The first that came to mind is the user’s facial expressions/emotions. – they are dynamic and can prompt a great deal of change in the behavior of the video feed, all in real time. The response could be multifaceted too – in addition to the different styles being applied, it could also be music that is relayed back, and the appearance of the canvas. And, this requires minimal effort from the user’s end, and so they can pay attention to making the video react in different ways. Above all, this was technically feasible, so I thought why not? In an ideal case, I envisioned that this piece would make for a nice installation somewhere, and this sort of interaction seemed to be ideal for such a project. I thought of different places where this could go; one particular place was the corridors in the Arts Centre at NYU Abu Dhabi. In the past, there have been screens set up close to the IM Lab there, where there was some interactive sketch that would react to the user’s motion. These sort of projects do not require a keyboard/touch screen or any sort of deliberate input device of sorts, just a screen and a camera.
With all of this in mind, I set out to bring “sent.ai.rt” to life. For the sake of completion, here is a complete description of sent.ai.rt:
sent.ai.rt is a real-time interactive self-portrait that utilizes techniques in machine learning to create an art installation which changes its behavior depending on the user’s mood derived from his/her facial expressions. The user looks into a camera and is presented a video feed in the shape of a portrait which they can then interact with. The video feed responds in two ways to the user’s emotion – it changes its “style” depending on the expression, and the web page plays back music corresponding to the mood. The style that is overlaid onto the video feed comes from famous paintings that have a color palette that is associated with the mood, and the music was crowd sourced from a group of students at a highly diverse university. The primary idea is to give individuals the ability to create art that they might have not been otherwise been able to create. On a secondary level, since the styles used come from popular artists such as Vincent Van Gogh, it is essentially paying homage to their craft and creating new pieces that essentially draw from their art pieces.
The phrase “sent.ai.rt” comes from the words “sentiment” which is meant to represent emotion which dictates how the portrait responds, and “art”. The “ai” in the middle represents the term “artificial intelligence” which is the driving force behind the actual interaction.
Implementation:
Following the initial peer-review, I did not get any concerns/questions with regards to the technical feasibility, so I went ahead with planning out how I was going to implement my project. Since there were multiple facets to it, I’ll break down the different facets to detail the entire process.
a) Gathering of Assets.
My project required both visual and auditory assets. The visual assets would be the images that I would use as the style sources for the different style transfers. When thinking about what sort of emotions I wanted to capture, these were the first few to come to mind :
Happiness
Sadness
Anger
Confusion.
The next step was to determine what sort of paintings were representative of each emotion. I decided to use color as my deciding factor, and came up with the following mapping where the color is representative of the emotion:
Happiness – Yellow
Sadness – Blue
Anger – Red
Confusion – White/Grey.
Next, I sourced out famous paintings that had these color palettes as the primary colors. These four paintings are what I settled on in the end:




While the selection of these paintings were somewhat arbitrary in nature, I believe that since I was more interested in sourcing out paintings with a desired color palette, these images fit the description pretty well.
In addition to these visual assets, I also needed to gather music that corresponded to the different emotions. In order to minimize personal bias on this step, since I did not have any fixed criterion to decide what songs correspond to what mood, I decided to crowd-source these. I compiled a collection of songs after conducting a survey on NYUAD’s campus Facebook group.
Here are the songs that I used from the results of the survey:
Happy
1) Queen – Don’t stop me now
2) Goodbye Yellow Brick Road by Elton John
3) Surrender by Cheap Tricks
4) Juice by Lizzo
5) On The Top Of The World By Imagine Dragons
Angry
1) Kawaki wo Ameku – Minami
2) Na Na Na – My Chemical Romance
3) Copycat – Billy Eilish
4) Kanye West, Jay Z, Big Sean – Clique
5) Paranoid Android – Radiohead
Confused
1) Tiptoe through the Tulips
2) clocks by coldplay
3) Babooshka – Kate Bush
4) Sleepwalker by Hey Ocean
5) joji – will he
Sad
1) Orange Blossom – Ya sidi
2) Linking Park – Blackout
3) Coldplay – Fix You
4) Hurt by Johnny Cash
5) limp bizkit-behind blue eyes
b) Machine Learning Models
There are two facets to the Machine Learning – the actual Neural Style Transfer models and the facial expression detection.
For the neural style transfer part, I used ml5js’s training script to train a model with the necessary images.
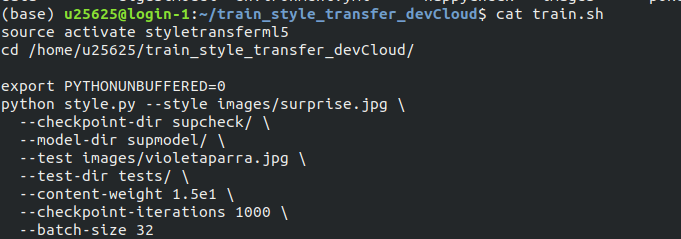
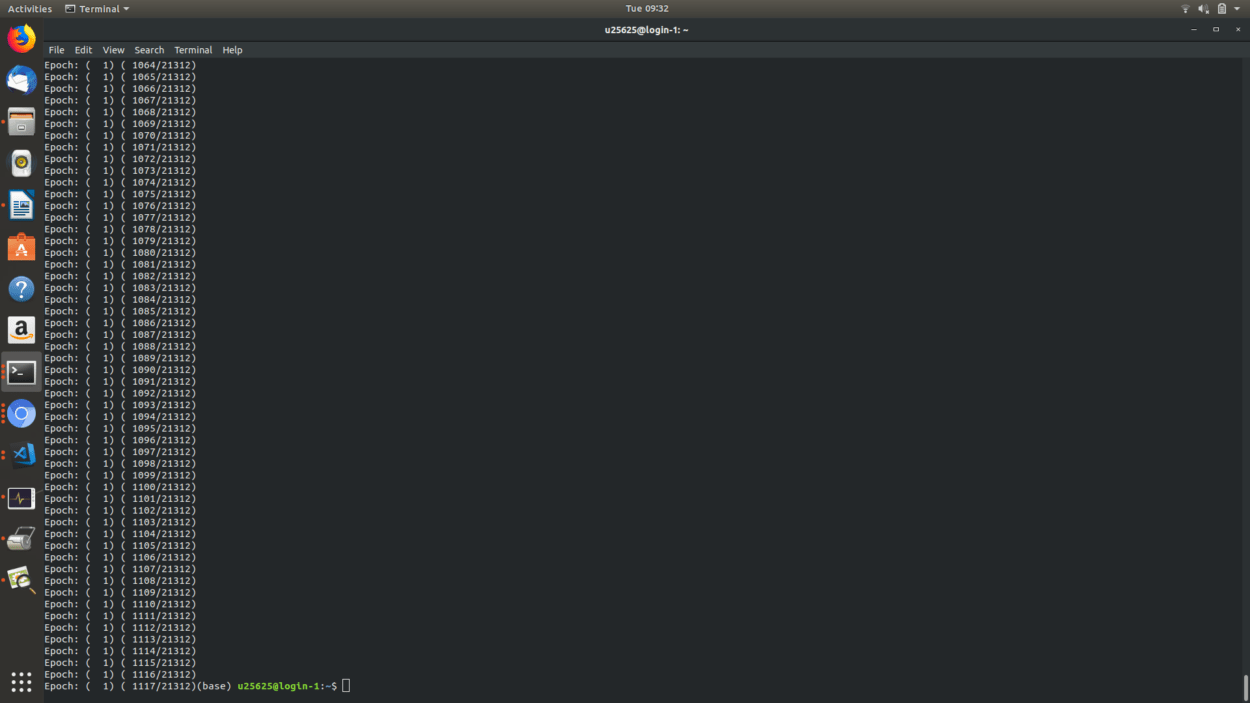
Usually, training such a model could take over two days on a regular computer, but since I had SSH access to an Intel CPU cluster from Interactive Machine Learning, I was able to train 4 of these models in under 24 hours. Once the models had trained, it was a matter of transferring the models back to my laptop via scp and then preparing the ml5js code to inference the output.
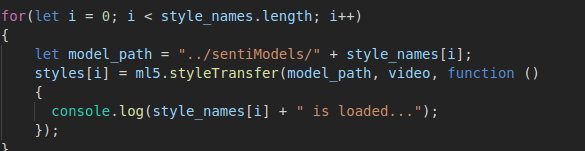

More details about style transfer in ml5.js can be found here
The code to train the actual models for the style transfer can be found here
The next step was to figure out a way to do the facial expression detection, and luckily, there was an open source API called face-api.js.
Built on top of the Tensorflow.js core, the API allows various image recognition techniques with faces, and one of them is Facial Expression Detection. They provided different pre-trained models, which were trained on a variety of faces, so that saved me a lot of time in trying to train a model from scratch, which would have proven to be quite difficult in the limited time that we had.

They provided a simple endpoint through which I was able to use the API in order to do the necessary detection, and calculate the most likely expression.
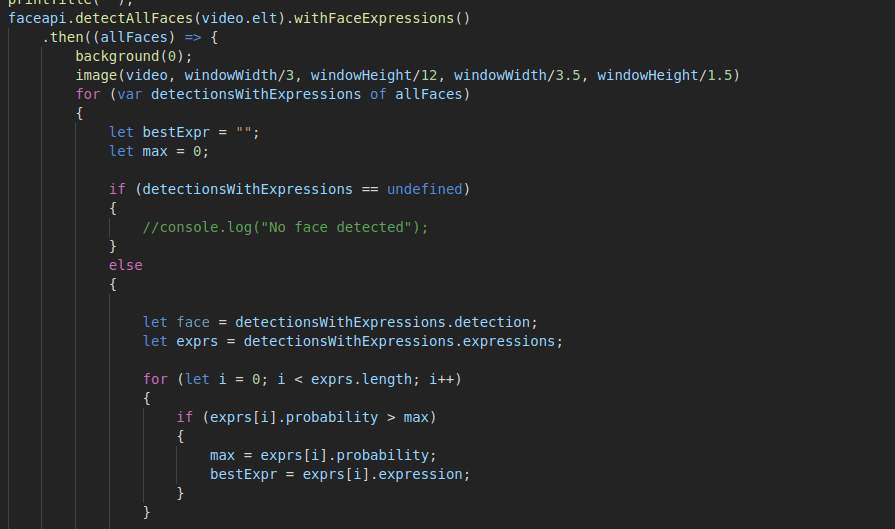
After I had confirmed that the model was working, I was ready to put all the different components together.
c) Integration
This was probably the lengthiest stage of the entire process, If I were to sum up the workflow of the piece, it would be as follows:
->Capture video
–> Detect Expression
—–> If Neutral – > do nothing
——> Otherwise -> Perform style transfer
———-> Update canvas with elements related to the detected expression (play audio, show name of track, and display which emotion has been triggered)
———————-> Repeat
(In addition to the above, the user can disrupt the workflow by pressing the spacebar, causing the program to momentarily halt to take a screenshot of the video feed)
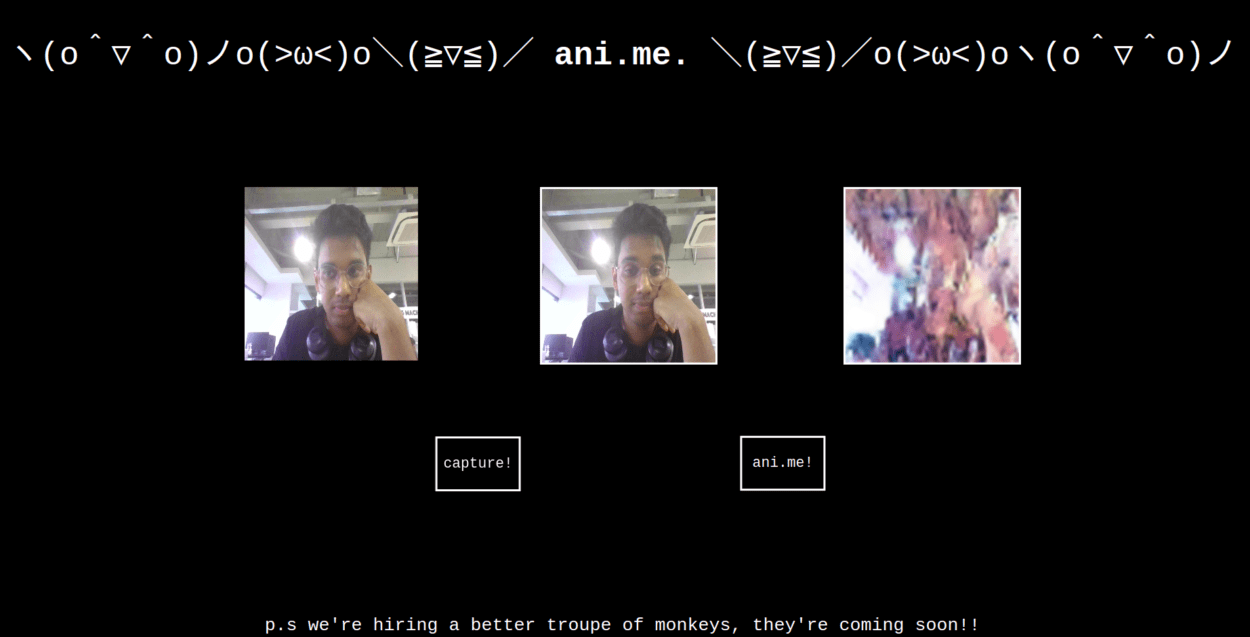
In order to create a real-time video feed, I used p5.js’s createCapture() functionality with Video. At this stage, three of my major components- the video, facial expression detection and style transfer – are solely Javascript based. With that in mind, I decided to use the whole webpage as a p5.js canvas which would make it easy for me to integrate all these components together. This also meant that any text and styling would also be done in p5.js, and this seemed to be a much better option than regular HTML/CSS in my case because of the fact that all the different elements depend on some Javascript interaction, so it was easier to do all the content creation directly on a canvas.
The layout of the page is very straightforward. The video feed sits in the middle of the page, with different words describing the active mood lighting up in their respective colors on both sides of the video. The audio assets are loaded in the preload() function while the weights for the machine learning models are loaded in the setup() function because ml5js has not integrated support for preload() as of yet. The face-api models are also loaded in setup(). Once that is done, the draw() loop handles the main logic. Before diving into the main logic, I also wrote some helper functions that are called in the draw() loop, so these will be described first.
getStyleTransfer() – This function gets the index of the best facial expression detected from the styles array
playSong() – This function plays a random song from a random point for a given expression.
stopSong() – stops all audio streams
getTitle() – This returns the name of the song that is currently being played.
keyTyped() – This function checks if any key has been pressed. In this case, it checks if the spacebar has been pressed, and if so, it runs a block of code to get the pixels from the video feed and save it as a png image that is downloaded by the browser.
writeText() – This writes the decorative text to the screen
printTitle() – This updates the title of the currently playing song on the screen.
displayWords()- This function displays words corresponding to the given expression/mood at pre-defined positions in colors that correspond to the mood.
windowResized() – This function helps make the page as responsive as possible.
The first thing that is done in the draw loop is that all the text is displayed. Then, the face-api is triggered to pick up facial expressions, and once the expression has been processed, the algorithm will decide whether or not to do a style transfer. If the expression is determined to be “neutral” , then the feed remains unchanged, and if not, there is another block of logic to deal with activating the transfer for the given mood/expression. The logic for this block works in such a way that the algorithm checks the currently detected mood with the previously detected mood. This ensures that there is continuity of the video stream and that the music playback isn’t too jittery. Figuring out the logic for this part was the biggest challenge. My initial code was quite unstable in the sense that it would swap styles very unexpectedly, causing the music to change very rapidly, so you wouldn’t really be able to hear/see much because of how unstable it was. I recalled that in any feedback control system, using the previous output as part of the next input helps ensure that there is a smoother output, and so, incorporating such a feedback system really helped make the stream a lot smoother.
d) Deployment (WIP)
The biggest issue right now is figuring out a stable way to host my project on the internet. When it was tested, it always ran through a Python server, and once I put it up onto IMANAS, I realized that the IMA server did not have the same functionality as a Python server. So, I had to look out for alternative ways to host my project. One option that I was already reasonably familiar with is Heroku,
My initial attempt at deploying it to Heroku was through a Python Flask application, but I ran into a lot of issues with pip dependencies. This was quite annoying and I later learnt that Flask and Heroku don’t really play well together, so I opted to use a Node app instead. After setting up a Node server, and setting the routes, the app was deployed!
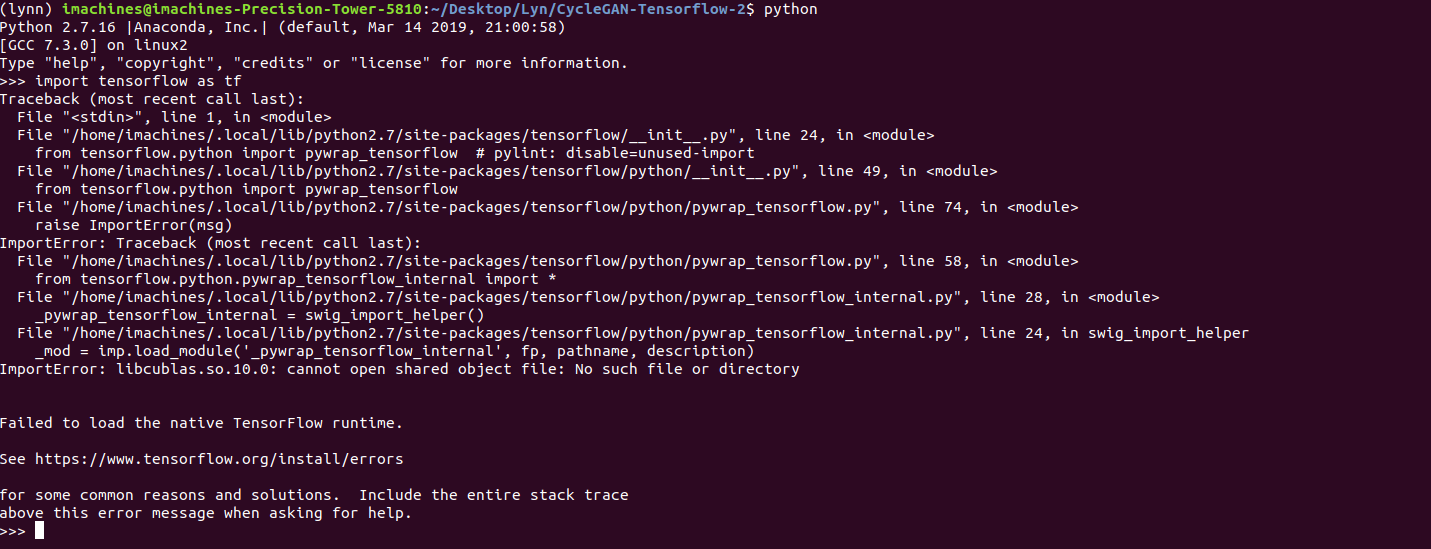
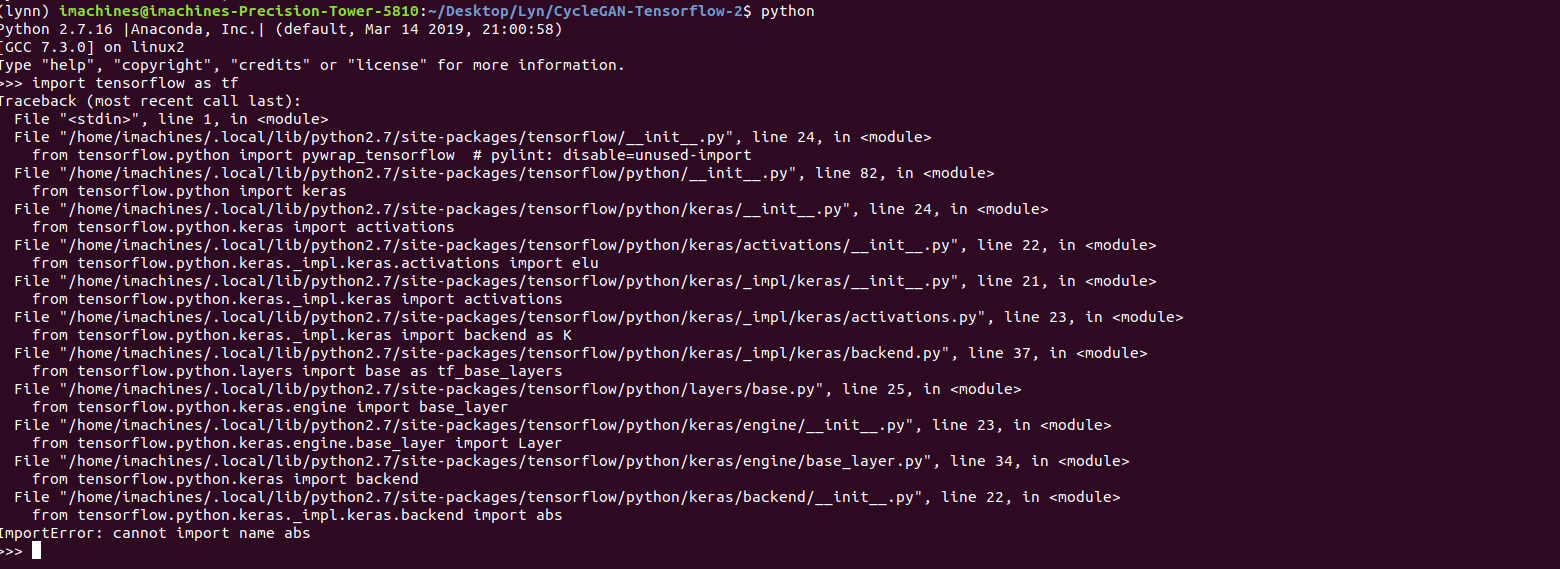
But, note, the keyword is “deployed”. Even though the app was deployed successfully, the page took an unreasonably long time to load up. This is because of the fact that I was loading 4 ml5js models onto the browser memory, and this took a really long time. And, once this was done, the page was extremely laggy and would sometimes cause the browser to crash, especially if there are multiple tabs open. This is a circumstance that I did not anticipate, and so right now, the only stable way to run it is through a local server. While this is quite annoying and prevents me from deploying my project to a suitable public platform, I think this also raises some very important questions about ml5.js and its underlying framework, Tensorflow.js. Since both of these frameworks rely on front-end processing, there has to be suitable method of deployment, and until there is such a method, I feel that running the heavy computations on the back-end would be a much better option.
Final Thoughts/Future Work/ Feedback
All in all, I’m pretty happy with the way things turned out, I was able to get all the elements working on time. However, one of the more glaring problems is the fact that the video stream is quite laggy and renders at a very low frameRate. Moon suggested that I use openCV to try to capture the face before feeding the stream to the faceAPI so that there would be fewer pixels rendered in real time. Dave and I sat down with Visual Studio Code LiveShare to try and integrate openCV but it would cause trouble on the ml5js side and since it was already quite late, we decided to shelf that feature for later. Ideally, that would make the video stream a lot faster. Another feature that I might integrate at some point is a function to maybe Tweet any photos you take via a Twitter Bot to a public Twitter page. Additionally, I’m still in the process of searching for a proper host that could serve my site in a reasonable amount of time without crashing.
After presenting in class, I learnt there were a few more minor adjustments that could have been made, after taking into account Cici’s, Nimrah’s and Tristan’s feedback. One thing that was brought up was the very apparent lag in doing the style transfer (which is something that I’m working on). However, at the actual IMA show, I found that there was another glitch which was that the program would often get “confused” when there were multiple faces in the frame, so I’m looking for a way to make it actually detect a single face instead.
But, again, I’m quite pleased with what I’ve put up, its been quite the journey, and as frustrating as it was at some points, I’m glad that I did it.