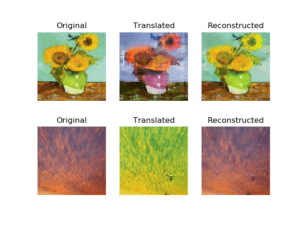
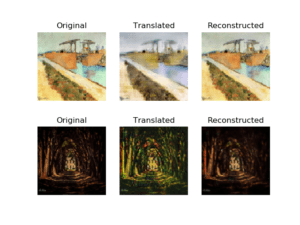
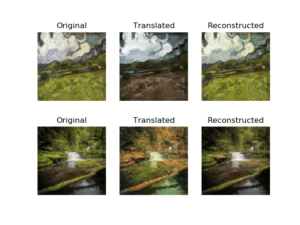
Originally, I wanted do something with GANs. I saw how good GANs are at creating novel information just by training on a dataset. Particularly, I was interested in the histogram of gradients visualizations / latent space interpolations. I was initially interested in this because I saw some GIFs of this online, the effects are rather stunning, so I wanted to create my own. I know how good generative adversarial networks work, and I know through a latent interpolation, people would better understand how the work internally. Because the generator network is essentially a deconvolutional network which takes random noise, we can perturb that latent vector slightly in order to move in some certain direction, that direction I am not sure of, and if we move around we will eventually see the different effects that the model can generate. I got sort of confused around this stage, because a lot of the gan models had weird inputs so I was not sure how to manipulate the latent variable. If I had more time, I would explore the model code more closely in order to see how I can interpolate the models to how I desired. I was also suggested to use TL-GAN, however I could not figure out how to get it to work with what I wanted ( style transfer).
In Hindsight: Ultimately, I abandoned the project because I didn’t know how to interpolate in latent space for the models that I downloaded (cyclegan), so I instead switched focus to something closer to the domain of style transfer. One that looked particularly interesting to me was Cyclegan, which allows for style transformations from a domain without an explicit one to one matching in the training set.
Note – I wrote this after completing the midterm
Author: Andrew Huang