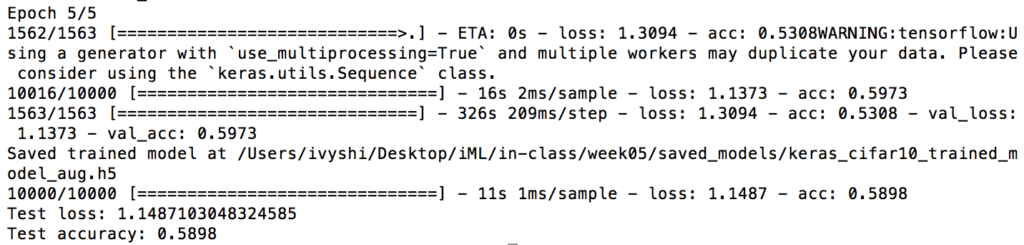
iTo train CIRFAR-10 CNN, I started with default batch size 2048 and ran it with 10 epochs on my 2015 MacBook Pro. During the process, the loss goes down and the accuracy increases as more epochs are trained. In the end, I got a test loss of 1.65 and test accuracy of 0.4167. For each epoch, the training time is around 200s.
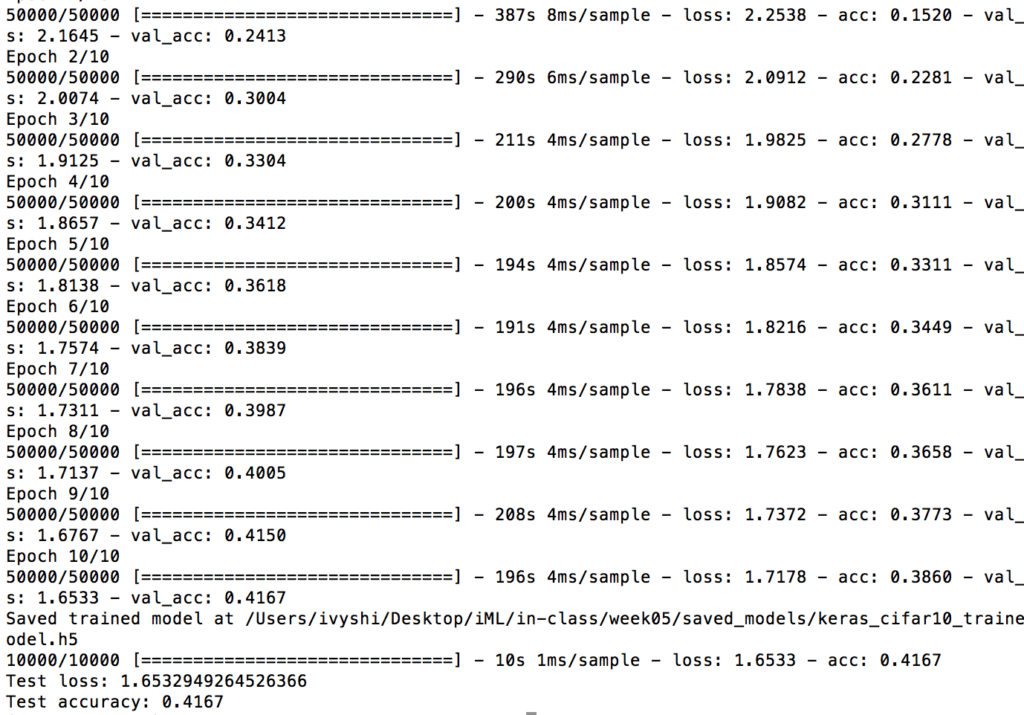
Then I experimented with different patch sizes. Because for the first try with 10 epochs was taking too long, I decided to decreases these trials to 5 epochs each. Here is a summary of the test results:
| Batch Size | Test Loss | Test Accuracy | Running Time |
| 1024 | 1.68 | 0.4069 | ~190s |
| 256 | 1.46 | 0.4681 | ~195s |
| 32 | 1.07 | 0.6210 | ~250s |
| 8 | 1.04 | 0.6083 | ~260s |
Out of all these trials, batch size 32 seems to yield the best results and the best compromise between running time and test accuracy. Even though the running time of batch size 32 is a bit longer compared to the ones with much bigger batch size, the accuracy improved significantly. Hence, I decided to run the training with batch size 32 with 30 epochs. The details are attached below:
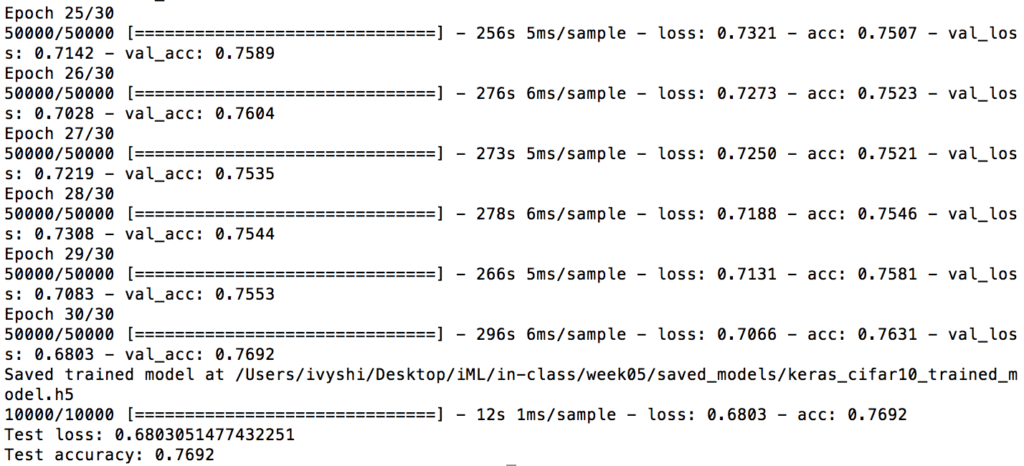
This training took about 2 hours. The final results are 0.68 test loss and 0.7692 test accuracy. I am quite satisfied with the results but there are definitely ways to improve. It would be valuable to repeat the same process on better hardware and see how the outputs further enhance.
Data Augmentation:
I also experimented with Data Augmentation by adapting the code here https://keras.io/examples/cifar10_cnn/. However I was getting some errors while training.
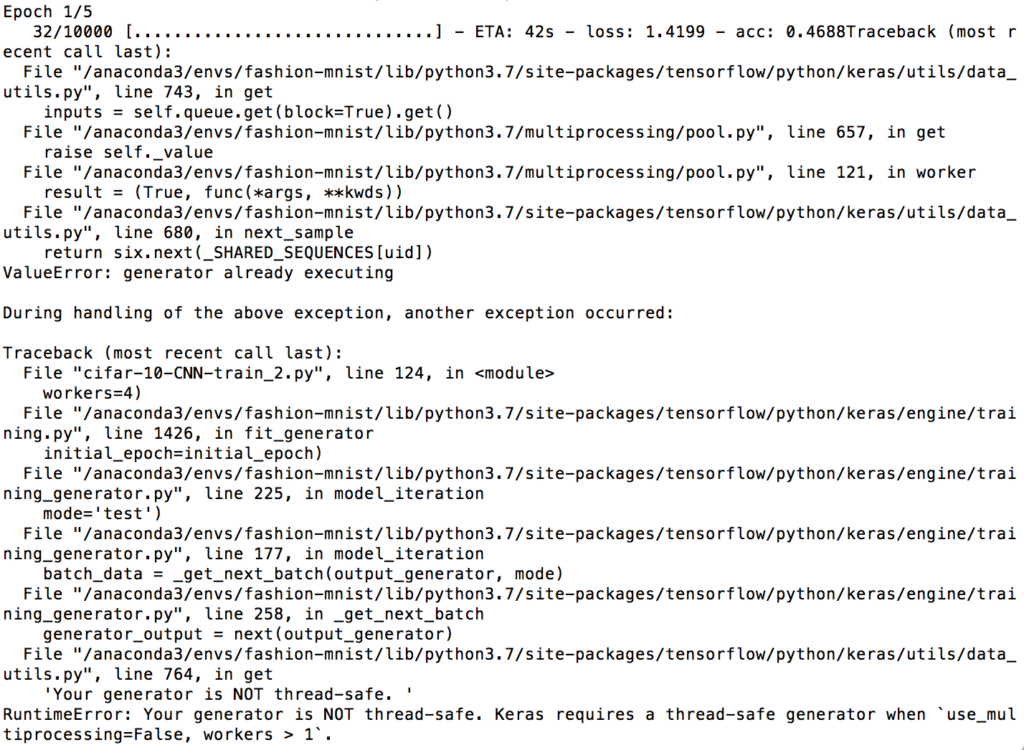
I searched online “generator is not thread-safe keras” and found an issue on github https://github.com/divamgupta/image-segmentation-keras/issues/42. It shows one possible solution by adding use_multiprocessing=True in the fit_generator statement.

The results are shown below. With batch-size 32 and 5 epoch, I got test loss of 1.15 and accuracy of 0.5898. This is slightly less accurate than the training result without data augmentation. More trials are needed to achieve the optimal parameters and the best results. In addition, there might still exist a problem with using ‘use_multiprocessing=True’ which may duplicate data as indicated on the command line.