Model training
I choose this painting from Picasso as the target style and use cd image_path and qsub image_name colfax to upload this image to my devcloud.

But when I submitted my training task, I couldn’t see the expected result. Professor checked and found that I didn’t have the local train.sh. So I created one and upload it to the devcloud. This time it worked and then I downloaded the model by using scp -r colfax:train_style_transfer_devCloud/models 111(my name). At first, I did this on the devcloud platform, so I failed to download the model. Then I realized that I should download the model on the local terminal and got my model successfully.
Application
I changed the original code to apply my own model and got this:
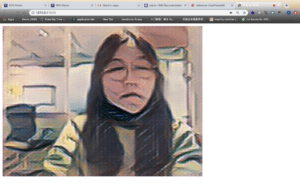
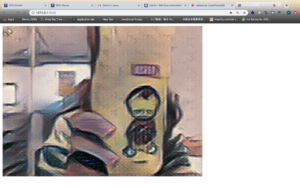
This image is abstract and is quite different from my original image, but it looks funny. Also, the canvas isn’t smooth when the style is changed. I think the reason might be the huge calculation like my midterm project. I thought this was simple because I could only change the style by pressing the space. Thus, I added poseNet model to use the pose to replace space. When the coordinates of the user’s nose reached a certain range, the style will change. However, every time I changed my position, the style would change from the original one to Picasso style. Therefore, it looked so weird and it blinked. So I had to give up this method and still applied the keyPressed function.
But it inspired me a lot for my final project. Maybe I can use the pitch or tone of sound to trigger the change of the style so that it can enrich the visual output. For example, if the tone is high enough, the style will transfer to another one. However, the precondition is to solve the problem of stuck live video.