Project Name: Stick Figure Transfer
Name: Yinmiao Li
Introduction: This project focus on transfer human full body photos to stick figure pictures. Choose full body photos from local computer and upload to the webpage. Then, by machine learning models, human photos can be transferred to the stick figure. Below are the three examples that I think works the best.
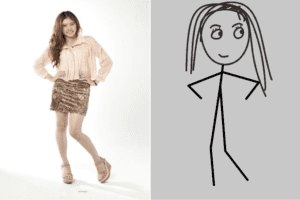


Process:
-
- Determine which method to use. I’ve tried to apply style transfer to only the head part. But the model trained is not very successful and the results are not good. There are also related projects using GAN or image classification. This Link suggests CariGAN they used: CariGAN
But I think the styles are not the same, and stick figure is much more abstract than this CariGAN style. Therefore, I decided using feature extraction for face recognization, and PoseNet for body actions. The features I chose for the face are:- gender: I detect gender first because I would want to distinguish man and woman in some details. So with the given gender, if it’s detected as a girl, then their eyes have eyelashes, if a boy, then no eyelashes.
- face shape: There are 5 kinds of face shapes. Round, Oblong, Diamond, Rectangle, Diamond.
- glasses: detect if human have glasses or not, as a feature of eyes. (Avoid classifying eyes shape, cause it’s more complicated, also, I want the stick figure stay abstract)
- hairstyle: It’s not easy to classify all the different hairstyle, so I decided to divide them into the following 3 features.
- hair length: short or long
- hair type: straight or curly
- facial hair: yes or no
- Build Model:
- For face shape and glasses, I didn’t use the machine learning model. Instead, I used Python Dlib and CV library to analyze. I refer to the paper: glasses detection on real images based on robust alignment. quoted from the paper “Eight facial landmarks are obtained [15]. In order to get the angle of misalignment, a regression line is calculated based on four points: the canthi of the left and right eye, i.e., left inner eye, left outer eye, right inner eye and right outer eye (see Fig. 4). After that, faces are rotated and aligned in the images so that eyes are located in the same coordinates for all the images. The area around the eyes is calculated in source image. Once the coordinates for the corners of the eyeglasses region in the rotated image are calculated, the resulting area is cropped from the rotated image.”
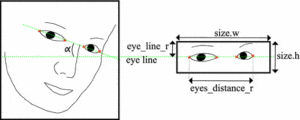 Also, I refer to the code from wtx666666
Also, I refer to the code from wtx666666
For face shape, the principle is quite similar, with the help of dlib and CV, it determines by calculating the different line distance on the face and the angle of the face. Here is the reference. - Gender: I saw other people make datasets by collecting 2200 face images from google. The model is created by training SmallerVGGNet. The face images are cropped by CV lib.
- Hair Features: I’ve searched for researches doing hair features detection. One of the researches uses pytorch, and they classify the hairstyle in 7 categories. First, I want to try to implement this in tensorflow. But then I think, the 7 categories are not very precise, and very concrete or detailed. I also think of bodyPix to get the edges of the hair, but still, this is very concrete and not accurate, so the result will be very weird. That’s why I think about getting all the features. Then I saw this post: https://datasciencelab.nl/deploy-your-machine-learning-model/. They mentioned they train the model with the help of inception v3. So I refer to the following list to get to know what is inception v3 and how to use it to train our own model: //www.tensorflow.org/tutorials/images/image_recognition?hl=zh-cn
https://blog.csdn.net/qq_16320025/article/details/89154488
https://www.jianshu.com/p/acb681e9b68a - PoseNet: I first tried to use the ml5 posenet model. But I didn’t figure out how to detect photo by ml5 posenet. I searched the questions online, and see the solutions all suggest tensorflow.js posenet model. Therefore, I changed to tensorflow.js posenet model.
- For face shape and glasses, I didn’t use the machine learning model. Instead, I used Python Dlib and CV library to analyze. I refer to the paper: glasses detection on real images based on robust alignment. quoted from the paper “Eight facial landmarks are obtained [15]. In order to get the angle of misalignment, a regression line is calculated based on four points: the canthi of the left and right eye, i.e., left inner eye, left outer eye, right inner eye and right outer eye (see Fig. 4). After that, faces are rotated and aligned in the images so that eyes are located in the same coordinates for all the images. The area around the eyes is calculated in source image. Once the coordinates for the corners of the eyeglasses region in the rotated image are calculated, the resulting area is cropped from the rotated image.”
- Process: I implement the face detection part in Python, and it will return a list of the features like this. The list has an order like this: [‘ gender ‘,’,’ glasses or not ‘,’face shape’,’ facial_hair or not ‘, ‘ hair_length ‘, ‘ hair_type ‘]
Input:

output:
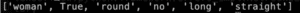 Then I dealt with this information in Python, select the corresponding photos for the pictures.
Then I dealt with this information in Python, select the corresponding photos for the pictures.
I then implement the poseNet part. I encountered a big challenge here, which is combining Python and JavaScript together. Professor Moon has helped a lot on this. So finally, with the help of Node.js, I can send data from js file to Node.js and run Python as a subprocess of JS. I first upload an image on the webpage, and then save the image as the name out.jpg. So in python, I always dealt with the image called out.jpg. Then, I went to the next page, show the original image and the stick figure photo together. Also, I scale the size of the head for fun. - More Demos and Analysis:
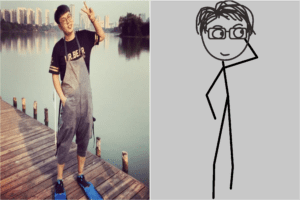


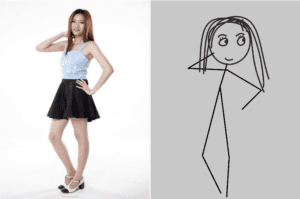
These three pictures show the model distinguish gender and reflected on the eyes’ features, the hairstyles are also different, and the eyeglasses part. The second and third girls show the differences in face shape. There are more examples showing these, but some inaccuracies on some parts.


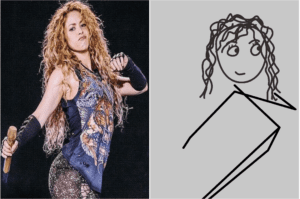

- Determine which method to use. I’ve tried to apply style transfer to only the head part. But the model trained is not very successful and the results are not good. There are also related projects using GAN or image classification. This Link suggests CariGAN they used: CariGAN
Future Work: I would want to make it more interactive. Use a webcam to take a photo and then show the result, this supposes to be easier to implement, but very high demand for the clarity of pictures. What’s more, I would want to take Moon’s suggestion, and implement the eye’s position in it, to make them have more emotions. If possible, I would want to print it out using Arduino or raspberry pie.
Conclusion: I’ve learned a lot from this final project, and I think although I have a lot of things that I want to do, I’m satisfied with the current stage. I think it’s a good start to continue with, I can do more on this path as well.