Inspiration
Even before my proposal, I was very heavily drawn towards working with text based machine learning. Chatbots have always fascinated me, especially models that are able to ‘trick’ the user into thinking that they are having a conversation with a real person. I wanted to have the bot be able to take in inputs from the user, and output certain responses to create the ‘back and forth’ interaction of a simple conversation.
The same week the midterm proposal was introduced, my psychology professor briefly talked about a strange syndrome called Wernicke’s Aphasia, which is essentially “characterized by superficially fluent, grammatical speech but an inability to use or understand more than the most basic nouns and verbs.” The aphasia can appear when the patient receives damage to the temporal lobe of the brain, and renders the patient either unable to understand speech, or unable to produce meaningful speech, albeit retaining proper grammar/syntax usage.
Here is an example of a patient with Wernicke’s Aphasia attempting to answer questions posed by a clinician:

Personally, this was especially interesting to me, the fact that the human brain can experience errors in language comprehension similar to computers. In a weird way, the effects of this aphasia was the inspiration point for my project; I wanted to have the chatbot simulate a patient with Wernicke’s. This seems like a sharp contrast to normal chatbots, where understanding is shared between two parties, because in this case, only the computer can ‘understand’ what the user is saying, but the user cannot deduce any meaning from the chatbot’s replies. People may wonder what the point is in talking with something that spews ‘nonsense’, but I think the interaction can accurately depict the struggles of an individual experiencing this aphasia in real life, where he/she is essentially isolated in terms of the social world.
Retrieving Data and Building the Model
In order to begin creating this chatbot, I needed to have powerful tools to work with language processing, and after some research, discovered the spaCy library, which integrates seamlessly with Tensorflow, and prepares text specifically for deep learning. I also found tutorials regarding the use of ‘bidirectional LSTMs’, which are essentially extensions of traditional LSTMs that improve upon model performance for sequence classification problems. The main use for the LSTM is to predict what the following word is for a given sentence (which is the user input).
In order to train the data, I needed a thorough data set complete with common English phrases and a variety of words to work with. I started off training the model with a copy of “Alice in Wonderland”, but the novel was just to small of a data set, so I ended up using “War and Peace’ by Leo Tolstoy, which is around 1585 pages.
I acquired a copy of the novel from the Gutenberg project, and split them into separate txt files. Because 1585 pages was extremely large, and I was on a strict time schedule, I ended up only feeding it around 500 pages.
Using spaCy, I formed one list of words containing the entire novel, which I then used to create the vocabulary set for my model. The vocab set acts essentially as a dictionary, where each word is stored without duplicates, and assigned an index.
Next, I needed to create the training sets for my model; in order to do this, I had to split the set into two parts, one of which contains the sequence of words from my original word list, and the other containing the next words of each sequence. Therefore, the end result of the model would be to be able to predict the ‘next word’ of a sequence of given words.
Lastly, I needed to convert these words into digits so that it could be understood by the LSTM, and build the model with the use of Keras; in order to do so I had to transform my word sequences into boolean matrices (this took a long, long time, with the help of several tutorials).
Training the Model
Since I spent most of the time learning how to implement spaCy and how to create a machine learning model, I had less time left to train the model, which was a big downside. Therefore, I couldn’t afford to feed it all 1500~ pages of the novel, and fed it only around 500~ pages. The result is as follows, with a batch size of 32 and 50 epochs:
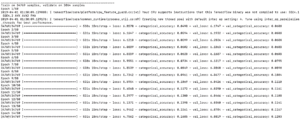
The first 14 epochs saw a steady decline in loss, and an increase in accuracy, which yielded a loss of 2.2 and an accuracy of 0.47 in the end. Not too bad, as the inaccuracy of words can actually play a part in stimulating the lack of meaning for the bot’s output.
Testing The Bot
I figured that I needed a way to adjust how the model ‘predicts’ the next possible word from my seed sentence (user input). Using sample( ), I ended up picking random words from my vocab set, but the twist is that the probability of the word being picked depends on how likely it is to be the next word in the sentence (which is determined by the trained LSTM). After a few more tweaking with the bot’s predictability numbers, I was ready to ‘talk’ with the chatbot. I asked the bot a few simple questions, similar to questions a clinician would ask a real patient with Wernicke’s. The result:

As you can see, the outputs are indeed nonsense sentences, but I felt that the lack in meaning was much too severe. Therefore, I had to adjust the predictability numbers quite a bit to find a good balance between nonsense and comprehension, as well as fix issues with periods and commas.

The second generation ended up having words that related more to the original question; it seemed as if the robot was trying to answer the question in the first half of the sentence, but loses all meaning in the second half, which was precisely the effect I wanted. In order to better differentiate between the user and the chatbot, I used Python ‘colored’ to change the chatbot’s outputs to a red color.

![]()

Even though I could not understand the chatbot at all, there was something engaging about asking it questions, and receiving a response back, especially when you knew that the bot was able to ‘read’ your inputs. Sometimes, the chatbot’s response would be eerily close to a meaningful response, and other times, completely incomprehensible. I ended up talking with the bot for at least half an hour, which was surprising to me, because I did not think that I would be engaged in essentially a one way conversation with a computer.
Issues
My biggest issue with the process is that I didn’t have enough time to feed it a larger, more robust data set. Also, because “War and Peace” was written quite a while back, the language that my bot learned is a bit ‘outdated’, meaning that if I were to ask it “Hey, what’s up?”, it would not be able to reply, because those words are not in it’s vocabulary set. Instead, it would feed me a ‘KeyError’. Another issue is that I had to manually tweak the syntax a few times (such as adding commas or periods) because grammar usage is actually very complex to learn.
Where I Would Like to Take This
I think there are a lot of possibilities to expand upon this project, because language and meaning is such a complex, layered topic. You could argue that the bot has it’s own way of creating ‘meaning’, in the sense that the model I trained it with is predicting words that it finds meaningful in relation to the phrases I ask it. Another aspect is that rather than seeing my original data set of “War and Peace” as a drawback, I could use it to my advantage, such as feeding another bot a different novel, and seeing how the language and syntax changes. I could have two bots trained on two different novels talk with each other, or even have multiple bots converse in a group. I could also train the bot using my own chat history from Facebook or WeChat, and have it emulate my style of speech. Interestingly, Wernicke’s patients have also been tested using pictures, where they are given certain photos, and asked to describe the content of said photo:

As you can see from the photo, there is more than one type of aphasia, which means that I could also create a bot with Broca’s Aphasia (partial loss of the ability to produce language, but with meaning intact), and have it interact with the Wernicke’s Aphasia chatbot. Or, I could just feed the bot an image, and have it describe the image as well, which I think would produce interesting results.
Ultimately, I am still new to the field of machine learning, but I aim to explore more into language processing and interactions between the user and the machine. Hopefully, I will be able to utilize more deep learning techniques to better train my model for the final project.