Project Name: Music Accompaniment
Project Description: Using Seq2Seq Model, with an input lead melody data, it will generate the accompaniment melody on the exact beat. The melody data then change to MIDI notes and time data and write into a new MIDI file. With the help of Logic Pro X, I bounce the merged MIDI files into the MP3 data.
Demo:
Process: Below, I will talk about the model I chose, the dataset I got, how I process the data and train the data, and then model inferencing.
-
- Model: I chose the RNN models since it is good at dealing with sequential data, for music information, time is a very important parameter, so using RNN is very reasonable. Here is also a link to the article by Andrej Kaparthy which talks about how powerful RNN is.
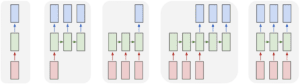
The pictures show several cases of RNN models.
For music accompaniment, I chose the special variations of RNN which is the Encoder-Decoder Model, also called Seq2Seq Model. It gets rid of the limit of output having the same length as the input.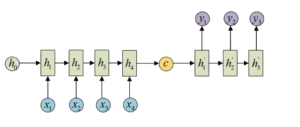
The Seq2Seq Model includes an Encoder RNN, a Decoder RNN and a states vectors which pass the Encoder data to the Decoder.
I refer to the Keras Documentation Seq2Seq example, which is the English to French Translator. - Dataset: There are many formats of music files, using MIDI files is the most convenient way. Because we can access to the instrument type, time data and pitch data from the MIDI file. I download the MIDI files from this link.

The MIDI files include two tracks, the first track is the lead melody, and the second track is the accompaniment melody.

- Data Processing: In order to train the data, I need to first process the data. The data should be changed from the midi file to a 3D array.
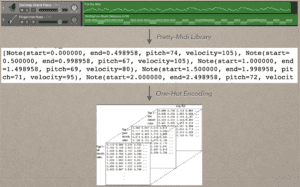
I first read the midi file into a text data by python pretty-midi library. And then I differentiate the lead track and accompaniment track into two lists. Each list store all the data in the dataset.
Then I changed these two lists to 3 different 3D matrices, which are encoder input data, encoder output data, and decoder output data. The 3D matrices are initialized to zero first.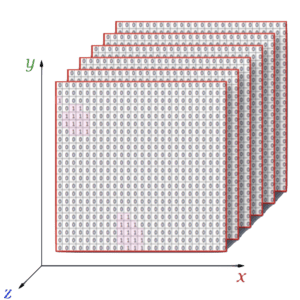
The Z index suggests the number of training pieces. The y-axis is the time information, with a static interval of 0.5s. The x-axis is the total number of the pitch, which is 0-127.
Using One-Hot-Encoder, we set the matrices according to the list data. For example, from the start time of 0s and the end time 0.5s, the pitch 64’s note is on, then set 64’s index of the first line to 1, and other positions remain 0.

- Train Data: I need to train the data for both the encoder model and decoder model.
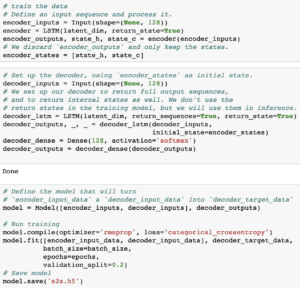
An encoder LSTM turns input sequences to 2 state vectors (we keep the last LSTM state and discard the outputs).
A decoder LSTM is trained to turn the target sequences into the same sequence but offset by one timestep in the future, a training process called “teacher forcing” in this context. It uses the state vectors as the initial state from the encoder. Effectively, the decoder learns to generatetargets[t+1...]giventargets[...t], conditioned on the input sequence. - Inference Mode: First, I vectorize the lead melody, and pass the input sequence into the encoder model, and get the states vectors. Then, pass the target sequence and the states vectors into the decoder model. With a while loop, looping through notes by notes, I get the output tokens and choose the three index with top weights, and append them into a list.
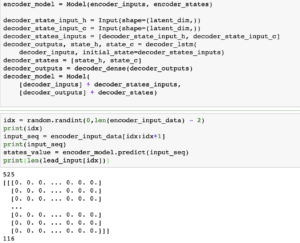


The last image is turning the list into MIDI files.
- Model: I chose the RNN models since it is good at dealing with sequential data, for music information, time is a very important parameter, so using RNN is very reasonable. Here is also a link to the article by Andrej Kaparthy which talks about how powerful RNN is.
Conclusion and Future Work: I’ve learned a lot on this specific model and the algorithm of machine learning. I also think that there are a lot can be done in music accompaniment, such as more dynamic timing, adding more tracks of instruments, creating more variations and so on. Music Accompaniment also has a lot of potentials, such as real-time accompaniment, people singing and the machine automatically make accompaniment melody for the singer.