DenseDepth
The model is developed to predict depth from 2D images. Depth estimation from images is used for scene understanding and reconstruction. The model is able to achieve detailed high-resolution depth maps using an encoder and decoder to extract features from the pre-trained neural network.
The model is trained with the NYU Depth v2 and the KITTI dataset. According to the paper by Ibraheem Alhashim and Peter Wonka, NYU Depth v2 provides images and depth maps for different indoor scenes, containing 120K training samples and 654 testing samples. KITTI provides stereo images and corresponding 3D laser scans of outdoor scenes captured using equipment mounted on a moving vehicle.
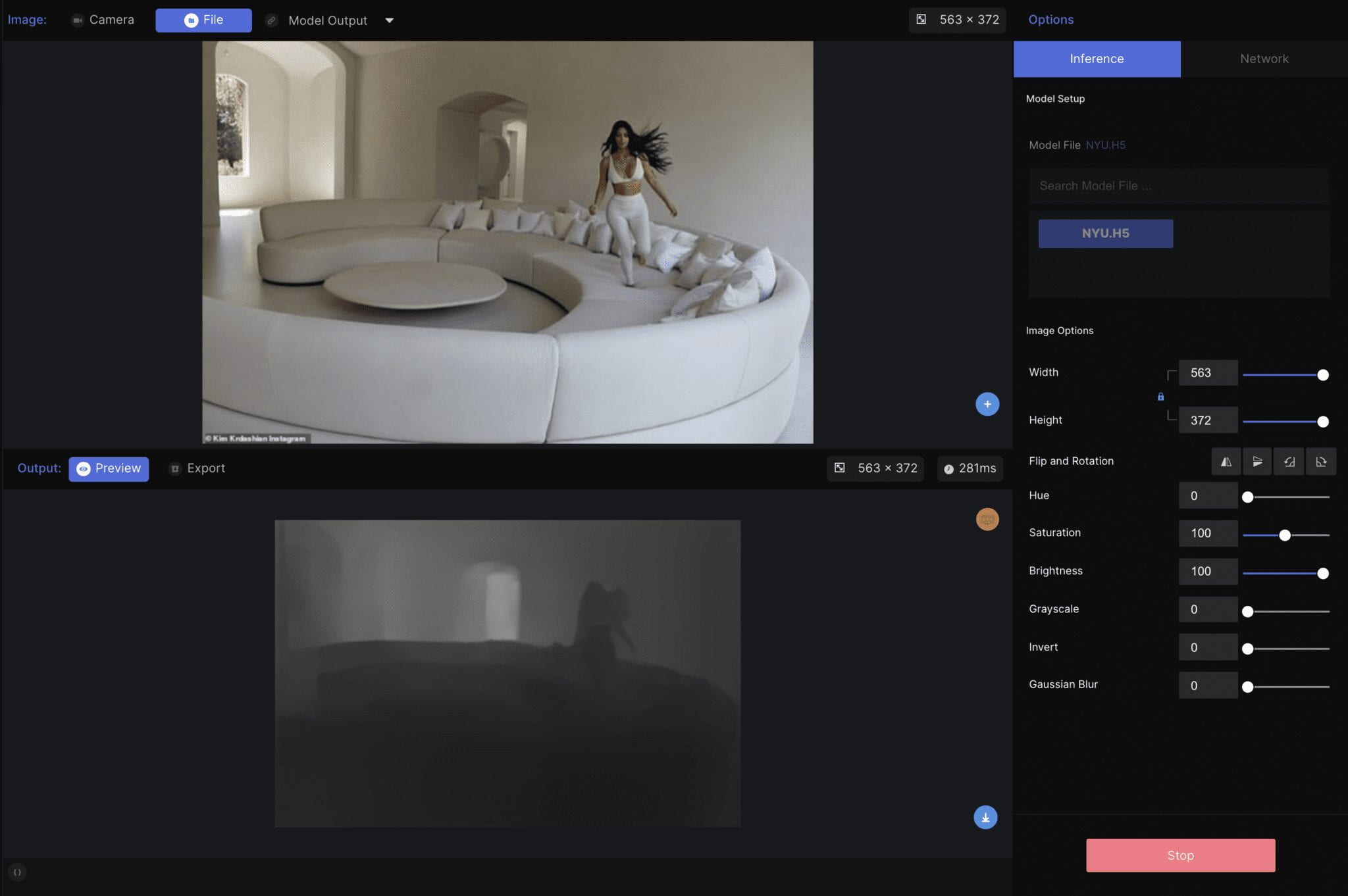
I experimented with multiple images, and it surprised me that digitally rendered artwork also works on this model. I am amazed by how detailed the depth predictions are. However, the result is a little too noisy, which I think is affected by the textures, lightings, and reflections.








Comparison:
DenseDepth:
MiDaS:
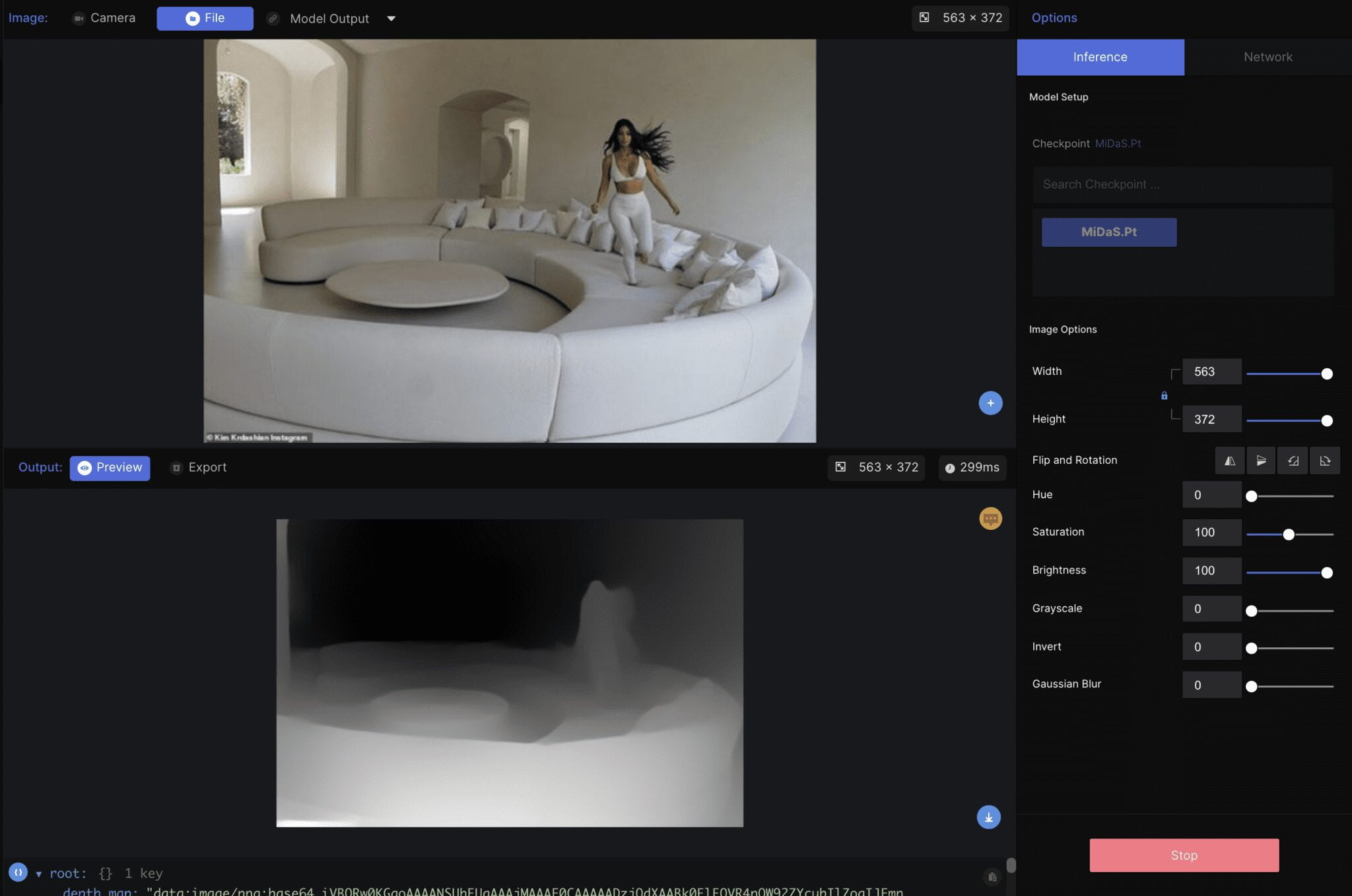
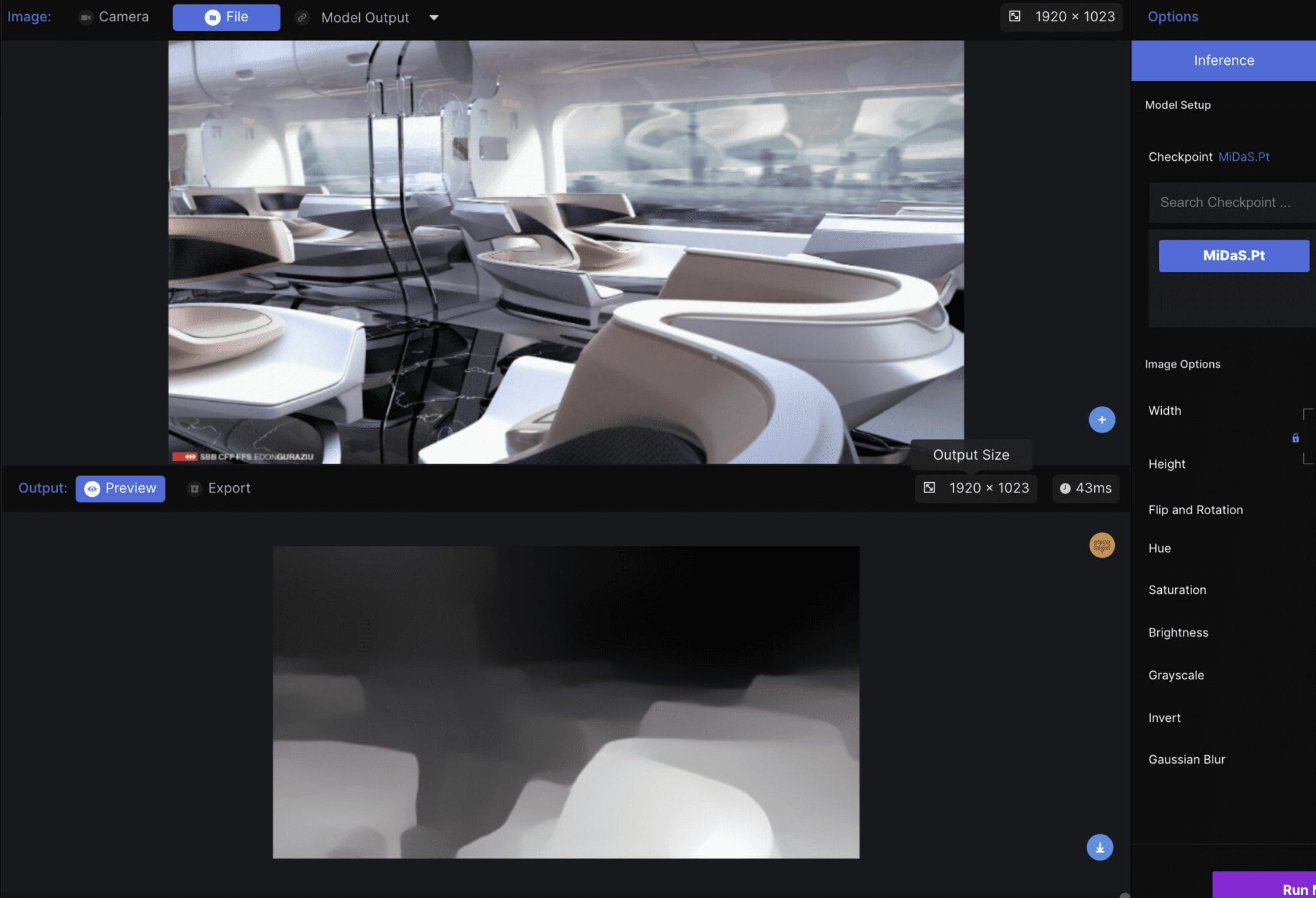
MiDaS model is trained with massive data source mixing multiple datasets, which decreases biases and outliers in each dataset. The result is quite different from DenseDepth. I feel like the result of MiDaS is less detailed but more accurate than that of DenseDepth. Lighting, shading, and texture have less influence on MiDaS, which is more intuitive and easier to interpret the depth.